









深度学习gpu的显存至关重要,显存过小的话,模型根本无法跑起来,本文介绍几种显存不足时的优化方法,能够降低深度学习模型的显存要求。
目录
一、梯度累加
梯度累加是指在模型训练过程中,训练一个batch的数据得到梯度后,不立即用该梯度更新模型参数,而是继续下一个batch数据的训练,得到梯度后继续循环,多次循环后梯度不断累加,直至达到一定次数后,用累加的梯度更新参数,这样可以起到变相扩大 batch_size 的作用。
model = SimpleNet()
mse = MSELoss()
optimizer = SGD(params=model.parameters(), lr=0.1, momentum=0.9)
accumulate_batchs_num = 10 # 累加10次梯度
for epoch in range(epochs):
for i, (data, label) in enumerate(loader):
output = model(data)
loss = mse(output, label)
scaled.backward()
# 当累计的 batch 为 accumulate_batchs_num 时,更新模型参数
if (i + 1) % accumulate_batchs_num == 0:
# 训练模型
optimizer.step()
optimizer.clear_grad()
二、混合精度
参考:混合精度训练
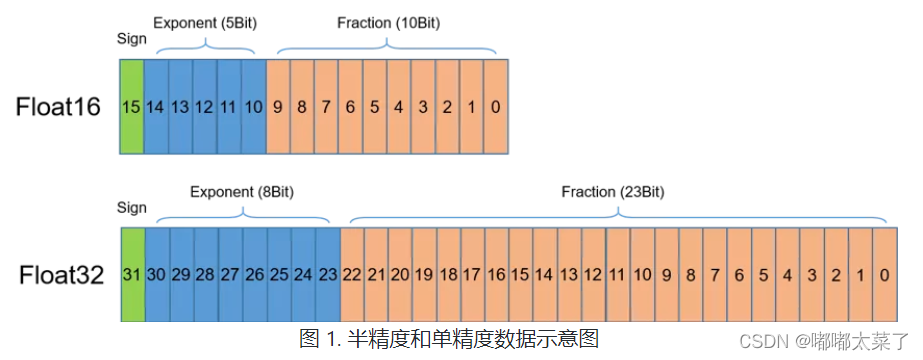
浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16),如图所示,半精度(FP16)是一种相对较新的浮点类型,在计算机中使用2字节(16位)存储。在IEEE 754-2008标准中,它亦被称作binary16。与计算中常用的单精度(FP32)和双精度(FP64)类型相比,FP16更适于在精度要求不高的场景中使用。
在使用相同的超参数下,混合精度训练使用半精度浮点(FP16)和单精度(FP32)浮点即可达到与使用纯单精度训练相同的准确率,并可加速模型的训练速度,这主要得益于英伟达从Volta架构开始推出的Tensor Core技术。在使用FP16计算时具有如下特点:
-
FP16可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下研究人员可使用更大更复杂的模型以及更大的batch size大小。
-
FP16可以充分利用英伟达Volta、Turing、Ampere架构GPU提供的Tensor Cores技术。在相同的GPU硬件上,Tensor Cores的FP16计算吞吐量是FP32的8倍。
但是使用FP16也会存在如下缺点:
- 数据溢出:数据溢出比较好理解,FP16相比FP32的有效范围要窄很多,使用FP16替换FP32会出现上溢(Overflow)和下溢(Underflow)的情况。而在深度学习中,需要计算网络模型中权重的梯度(一阶导数),因此梯度会比权重值更加小,往往容易出现下溢情况。
- 舍入误差:Rounding Error指示是当网络模型的反向梯度很小,一般FP32能够表示,但是转换到FP16会小于当前区间内的最小间隔,会导致数据溢出。如0.00006666666在FP32中能正常表示,转换到FP16后会表示成为0.000067,不满足FP16最小间隔的数会强制舍入。
为了想让深度学习训练可以使用FP16的好处,又要避免精度溢出和舍入误差。于是可以通过FP16和FP32的混合精度训练(Mixed-Precision),混合精度训练过程中可以引入权重备份(Weight Backup)、损失放大(Loss Scaling)、精度累加(Precision Accumulated)三种相关的技术。
1、权重备份
权重备份主要用于解决舍入误差的问题。其主要思路是把神经网络训练过程中产生的激活activations、梯度 gradients、中间变量等数据,在训练中都利用FP16来存储,同时复制一份FP32的权重参数weights,用于训练时候的更新。具体如下图所示,在前向和反向计算时,使用FP16,但是更新参数使用FP32.

2、损失缩放
在网络反向传播过程中,梯度的值一般非常小,如果使用FP32可以正常训练,但是如果使用FP16,由于FP16表示的范围问题(下图红线左边的部分在FP16中都为0),会导致较小的梯度在反向传播时为0,造成参数无法优化,模型无法收敛。
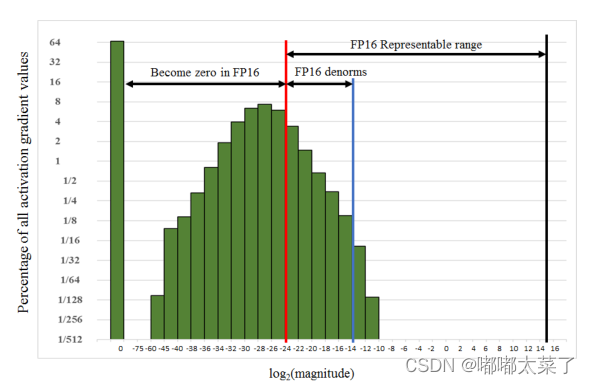
为了解决梯度过小数据下溢的问题,对损失函数进行缩放,并在参数优化时再将参数缩放回去。具体的操作为:
① 前向传播:loss = loss * s
②反向传播:grad = grad / s
损失函数乘上一个系数s,则梯度等比例增加,再优化参数时将其缩放为1/s,则可以解决梯度数值下溢的问题。
torch示例代码如下,参考:
# Creates model and optimizer in default precision
model = Net().cuda()
optimizer = optim.SGD(model.parameters(), ...)
# Creates a GradScaler once at the beginning of training.
scaler = GradScaler()
for epoch in epochs:
for input, target in data:
optimizer.zero_grad()
# Runs the forward pass with autocasting.
with autocast():
output = model(input)
loss = loss_fn(output, target)
# Scales loss. Calls backward() on scaled loss to create scaled gradients.
# Backward passes under autocast are not recommended.
# Backward ops run in the same dtype autocast chose for corresponding forward ops.
scaler.scale(loss).backward()
# scaler.step() first unscales the gradients of the optimizer's assigned params.
# If these gradients do not contain infs or NaNs, optimizer.step() is then called,
# otherwise, optimizer.step() is skipped.
scaler.step(optimizer)
# Updates the scale for next iteration.
scaler.update()3、精度累加
在混合精度的模型训练过程中,使用FP16进行矩阵乘法运算,利用FP32来进行矩阵乘法中间的累加(accumulated),然后再将FP32的值转化为FP16进行存储。简单而言,就是利用FP16进行矩阵相乘,利用FP32来进行加法计算弥补丢失的精度。 这样可以有效减少计算过程中的舍入误差,尽量减缓精度损失的问题。
三、重计算
一般来说深度学习网络的一次训练由三部分构成:
前向计算(forward):在该阶段会对模型的算子进行前向计算,对算子的输入计算得到输出,并传给下一层作为输入,直至计算得到最后一层的结果位置(通常是损失)。
反向计算(backward):在该阶段,会通过反向求导和链式法则对每一层的参数的梯度进行计算。
梯度更新(优化,optimization):在该阶段,通过反向计算得到的梯度对参数进行更新,也称之为学习,参数优化。
在反向传播链式传导时,需要中间层的输出来计算参数的梯度,故在训练阶段会保存中间层的输出。为了减少显存消耗,可以不保存中间层的计算结果,在反向传播计算梯度时,再进行局部前向计算出中间层的输出,来用于计算梯度。
重计算是通过时间换空间的操作。


















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











