







训练篇:使用pytorch实现垃圾分类并部署使用,浏览器访问,前端Vue,后台Flask
1.数据集准备
1.1数据集下载
在百度的AI Studio中有公开数据集,里面有很多不错的数据集可以给我们免费下载使用,下载速度也很快
其中这个数据集就是本文所使用的的数据集,下载链接如下
https://aistudio.baidu.com/aistudio/datasetdetail/30982

数据集下载好之后,新建python工程,将数据放入工程文件夹
1.2 数据集划分
之前学习深度学习的时候,大部分人都是从手写数字识别开始的吧,手写数字的数据集都是直接使用pytorch中的datasets.MNIST方法下载使用的,不需要自己去整理划分训练集和测试集,但是,如果使用自己的数据集做训练的时候,就需要自己去实现datasets方法.
在此之前,我们还需要写个脚本,将图片地址和标签写入txt文件并分为训练集和测试集,方便训练的时候调用。
在工程根目录下新建一个python文件,用来生成train.txt,test.txt,label.txt三个文件
import os
def generate(dir,label):
path = './' # 生成文件存放的位置
files = os.listdir(dir)
files.sort()
trainListText = open(path+'train.txt','a')
testListText = open(path + 'test.txt', 'a')
index = 0
proportion = 0.8 # 训练集所占比例
for file in files:
if index < int(len(files)*proportion):
if(os.path.splitext(file)[1]=='.jpeg' or os.path.splitext(file)[1]=='.jpg'):
name = dir + '/' + file + '**' + str(int(label))+'\n'
trainListText.write(name)
index +=1
else:
if(os.path.splitext(file)[1]=='.jpeg' or os.path.splitext(file)[1]=='.jpg'):
name = dir + '/' + file + '**' + str(int(label)) + '\n'
testListText.write(name)
index += 1
trainListText.close()
testListText.close()
if __name__ == '__main__':
dirs = os.listdir('data/train_data/train_data') # 数据集所在位置
dirs.sort()
label = 0
labelText = open('./label.txt', 'a')
for dir in dirs:
if dir != '.DS_Store':
labelText.write(dir + '**' + str(label) + '\n')
generate('data/train_data/train_data/' + dir, label)
label += 1
labelText.close()
print("down!")
运行该脚本后,会在工程的根目录生成三个txt文件
1.3实现自己的Dataset
新建一个python文件,命名为Garbage_Loader,新建一个Garbage_Loader类继承Dataset,要实现自己的dataset类,我们至少需要重写三个方法,init,__getitem__和__len__方法,__init__方法是实例化dataset类的时候初始化一些参数,__getitem__方法是获取第index个数据的图片和标签,__len__方法返回数据集的大小,具体的实现如下:
class Garbage_Loader(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])
self.val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x: x.strip().split('**'), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img = Image.open(img_path)
img = img.convert('RGB')
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
2.开始训练数据
2.1 实现训练方法和测试方法
新建python文件,实现训练方法和测试方法,代码如下
def accuracy(output, target, topk=(1,)):
"""
计算topk的准确率
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
class_to = pred[0].cpu().numpy()
res = []
for k in topk:
correct_k = correct[:k].contiguous().view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res, class_to
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
根据 is_best 存模型,一般保存 valid acc 最好的模型
"""
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best_' + filename)
def train(train_loader, model, criterion, optimizer, epoch, writer):
"""
训练代码
参数:
train_loader - 训练集的 DataLoader
model - 模型
criterion - 损失函数
optimizer - 优化器
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
writer.add_scalar('loss/train_loss', losses.val, global_step=epoch)
def validate(val_loader, model, criterion, epoch, writer, phase="VAL"):
"""
验证代码
参数:
val_loader - 验证集的 DataLoader
model - 模型
criterion - 损失函数
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Test-{0}: [{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
phase, i, len(val_loader),
batch_time=batch_time,
loss=losses,
top1=top1, top5=top5))
print(' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(phase, top1=top1, top5=top5))
writer.add_scalar('loss/valid_loss', losses.val, global_step=epoch)
return top1.avg, top5.avg
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
2.2 开始训练
在前面的文件中的if __name__ == '__main__':中实现训练流程
- 加载数据
- 定义网络
- 定义损失函数和优化器等
- 训练
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# -------------------------------------------- step 1/4 : 加载数据 ---------------------------
train_dir_list = './train.txt'
valid_dir_list = './test.txt'
batch_size = 32
epochs = 100
num_classes = 123 # 类别个数
train_data = Garbage_Loader(train_dir_list, train_flag=True)
valid_data = Garbage_Loader(valid_dir_list, train_flag=False)
train_loader = DataLoader(dataset=train_data, num_workers=0, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=0, pin_memory=True, batch_size=batch_size)
train_data_size = len(train_data)
print('训练集数量:%d' % train_data_size)
valid_data_size = len(valid_data)
print('验证集数量:%d' % valid_data_size)
# ------------------------------------ step 2/4 : 定义网络 ------------------------------------
model = models.resnet50(pretrained=True)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, num_classes)
model = model.cuda()
# ------------------------------------ step 3/4 : 定义损失函数和优化器等 -------------------------
lr_init = 0.0001
lr_stepsize = 20
weight_decay = 0.001
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=0.1)
writer = SummaryWriter('./runs/resnet50')
# ------------------------------------ step 4/4 : 训练 -----------------------------------------
best_prec1 = 0
for epoch in range(epochs):
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)
# 在验证集上测试效果
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase="VAL")
is_best = valid_prec1 > best_prec1
best_prec1 = max(valid_prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': 'resnet50',
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer': optimizer.state_dict(),
}, is_best,
filename='checkpoint_resnet50.pth.tar')
writer.close()
看到这个说明已经开始进行训练了,接下来就是漫长的等待。
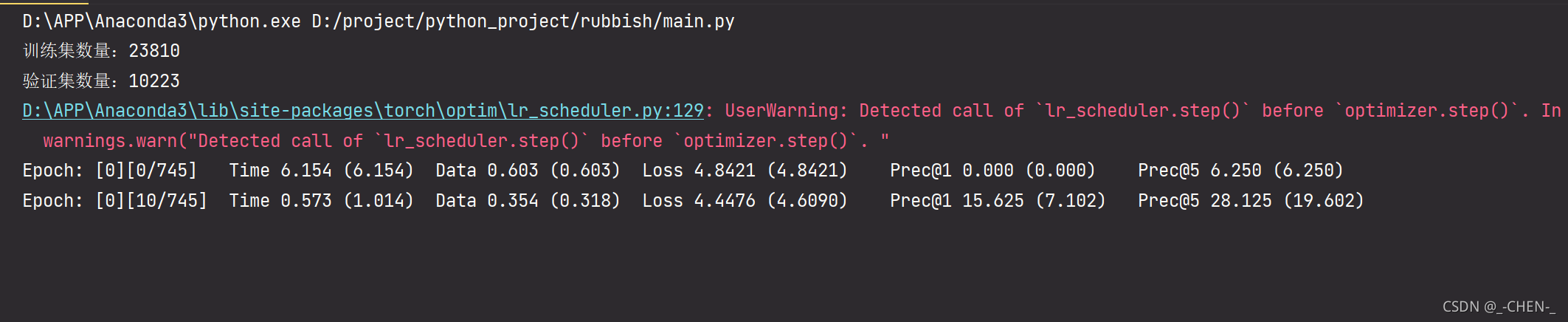
训练的过程,会自动将最好的模型保存下来,以及训练过程的loss,通过tensorboard可以进行查看,终端进入工程目录,运行下面命令
tensorboard --logdir=runs
浏览器输入http://localhost:6006/ 即可查看训练过程

















 1462
1462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











