







 本文详细介绍了如何在Linux系统上直接运行Hadoop自带的WordCount程序,以及在Windows上使用IDEA远程连接HDFS运行,并展示了如何修改程序实现单词出现次数降序排序。在运行过程中,列举了常见问题及解决方案,包括配置错误、内存不足等问题。
本文详细介绍了如何在Linux系统上直接运行Hadoop自带的WordCount程序,以及在Windows上使用IDEA远程连接HDFS运行,并展示了如何修改程序实现单词出现次数降序排序。在运行过程中,列举了常见问题及解决方案,包括配置错误、内存不足等问题。
Hadoop自带了个单词计数的MapReduce程序WordCount,下面用三种方法运行该程序
在开始前先在hdfs上面创建输入和输出路径:
1、使用hdfs dfs -mkdir /input命令创建一个input文件夹
2、使用hdfs dfs -put /home/kingssm/input/data.dat /input命令将需要执行的文件上传到hdfs上的输入文件夹
3、使用hdfs dfs -mkdir /output命令创建输出文件夹,因为hadoop要求输出文件夹不能存在,所以这只是空文件夹,在执行时再确定输出文件夹,如、output/output1
一、Linux系统上直接运行jar包
进入文件查看,最后一个就是我们要执行的程序
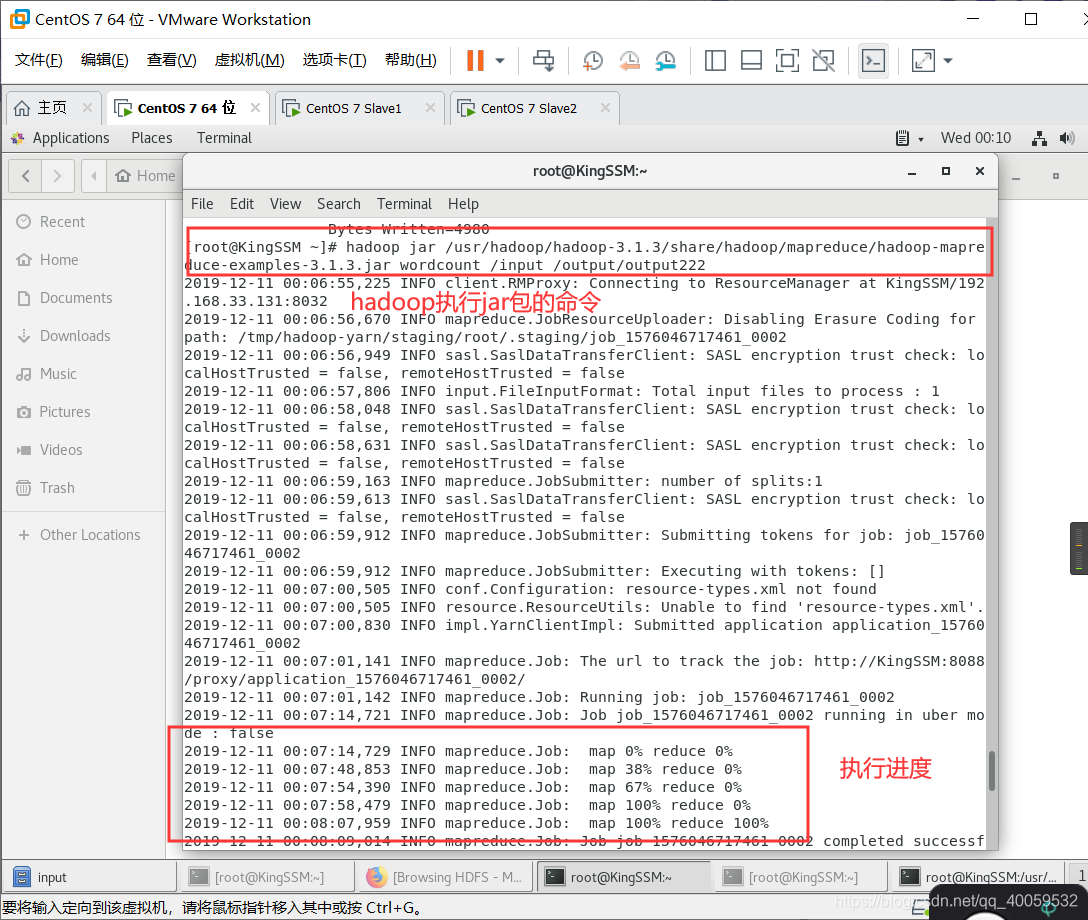
运行程序:输入命令进行执行hadoop jar /usr/hadoop/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output/output222
如果觉得太长了可以先进入到mapreduce目录再执行。
解释:hadoop jar是hadoop执行jar文件必须写的命令,中间很长的是jar包的路径,wordcount是启动类,/input是输入路径,/output/output222是输出路径,输出路径不能已经存在,前面创建文件夹已说。
到页面上查看,创建出了输出文件

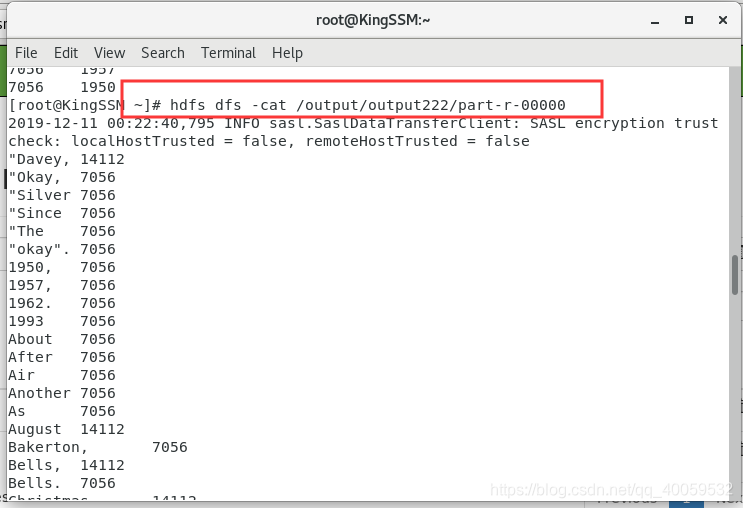
使用命令查看输出文件内容:hdfs dfs -cat /output/output222/part-r-00000
常见问题
问题一:
启动类写成WordCount,虽然代码的真实的类名就是WordCount,但是可能是官方打包是限定了启动类是wordcount,也就是说启动类只能小写
问题二:
运行报错:Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
问题原因:配置问题,在进行集群配置时没有添加该配置(可能是有些没有该配置也可以运行)
解决方案:打开mapred-site.xml文件,添加下面代码
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
问题三:
运行报错:Container killed on request. Exit code is 143 yarn.nodemanager.resource.
问题原因:使用默认内存,内存往往不够用
解决方案:修改下边文件配置(如果是多台虚拟机,那其他虚拟机最好也跟着改一下)
首先在yarn-site.xml中添加下面内容:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1500</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>
然后在mapred-site.xml中添加下面内容:
<property>
<name>mapreduce.map.memory.mb</name>
<value>1500</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3000</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1200m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2600m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
二、在window上使用idea运行、远程连接hdfs
下面是WordCount的源程序:
package test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
/**
* @Classname WordCount
* @Description TODO
* @Date 2019/12/6 22:12
* @Created by KingSSM
*/
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7952
7952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









