









一、运行Hadoop自带的hadoop-examples.jar报错
Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x

解决办法:
1.进入hdfs
su - hdfs
2.查看目录权限
hdfs dfs -ls /
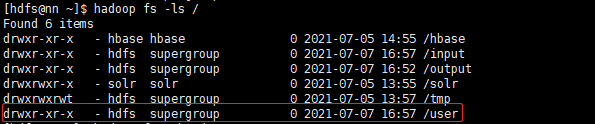
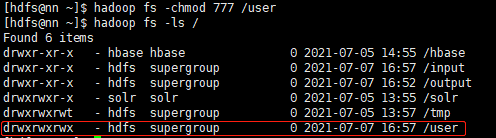
3.修改权限
hadoop fs -chmod 777 /user
运行Hadoop自带的example例子(wordcount):
首先创建input文件夹
hdfs dfs -mkdir -p /user/hdfs/input
创建测试文件(用来统计该测试文件单词个数)
cd /opt/hadoopTest
touch test
将下面测试句子追加到test文件中
Hello OK!
将test文件上传到hadoop分布式系统
hdfs dfs -put /opt/hadoopTest/test /user/hdfs/input/
将hadoop-examples.jar自带的jar包放到/opt/hadoopTest/下面
执行命令运行hadoop-examples.jar
hadoop jar /opt/hadoopTest/hadoop-examples.jar wordcount input/test output
ps:
hadoop jar是hadoop运行jar包命令
/opt/hadoopTest/hadoop-examples.jar是本机的hadoop-examples.jar路径
wordcount是程序主类名
input/test 是输入路径,运行wordcount计算test文件中的单词个数
output是输出路径
运行结果:
[hdfs@nn ~]$ hadoop jar /opt/hadoopTest/hadoop-examples.jar wordcount input/test output
21/07/08 19:46:49 INFO client.RMProxy: Connecting to ResourceManager at nn/172.30.128.212:8032
21/07/08 19:46:49 INFO input.FileInputFormat: Total input paths to process : 1
21/07/08 19:46:49 INFO mapreduce.JobSubmitter: number of splits:1
21/07/08 19:46:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1625468095065_0015
21/07/08 19:46:49 INFO impl.YarnClientImpl: Submitted application application_1625468095065_0015
21/07/08 19:46:50 INFO mapreduce.Job: The url to track the job: http://nn:8088/proxy/application_1625468095065_0015/
21/07/08 19:46:50 INFO mapreduce.Job: Running job: job_1625468095065_0015
21/07/08 19:46:57 INFO mapreduce.Job: Job job_1625468095065_0015 running in uber mode : false
21/07/08 19:46:57 INFO mapreduce.Job: map 0% reduce 0%
21/07/08 19:47:02 INFO mapreduce.Job: map 100% reduce 0%
21/07/08 19:47:08 INFO mapreduce.Job: map 100% reduce 100%
21/07/08 19:47:09 INFO mapreduce.Job: Job job_1625468095065_0015 completed successfully
21/07/08 19:47:09 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=42
FILE: Number of bytes written=298359
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=110
HDFS: Number of bytes written=14
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3643
Total time spent by all reduces in occupied slots (ms)=3840
Total time spent by all map tasks (ms)=3643
Total time spent by all reduce tasks (ms)=3840
Total vcore-milliseconds taken by all map tasks=3643
Total vcore-milliseconds taken by all reduce tasks=3840
Total megabyte-milliseconds taken by all map tasks=3730432
Total megabyte-milliseconds taken by all reduce tasks=3932160
Map-Reduce Framework
Map input records=1
Map output records=2
Map output bytes=18
Map output materialized bytes=38
Input split bytes=100
Combine input records=2
Combine output records=2
Reduce input groups=2
Reduce shuffle bytes=38
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=215
CPU time spent (ms)=1080
Physical memory (bytes) snapshot=526041088
Virtual memory (bytes) snapshot=5482082304
Total committed heap usage (bytes)=441192448
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=10
File Output Format Counters
Bytes Written=14
Hadoop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_1625468095065_0015,而且得知输入文件有1个(Total input paths to process : 1),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输出记录。比如说,在本例中,map的task数量是1个,reduce的task数量是1个。map的输入record数是1个,输出record数是2个等信息。
查看结果:
hdfs dfs -ls /user/hdfs/output
hdfs dfs -cat /user/hdfs/output/part-r-00000
















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









