







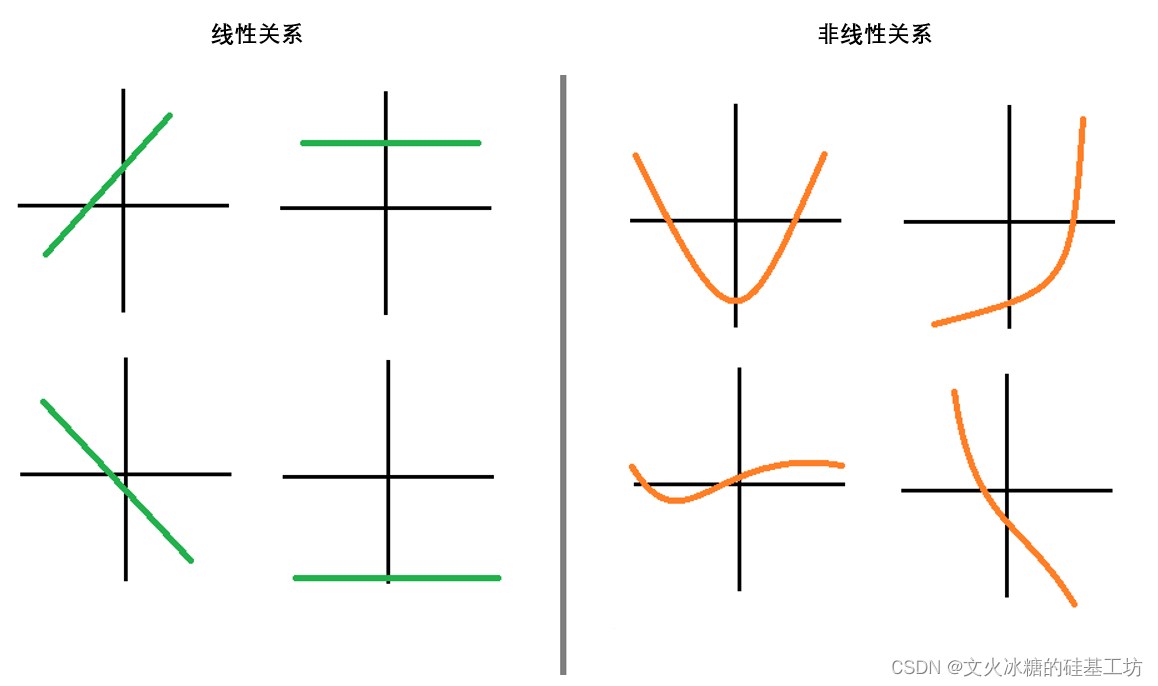
变量的线性与非线性
最常使用的线性是指“变量之间的线性关系”,它表示两个变量之间的关系可以展示为一条直线,即可以使用方程y=kx +b来进行拟合。
要探索两个变量之间的关系是否是线性的,最简单的方式就是绘制散点图,如果散点图能够相对均匀地分布在一条直线的两端,则说明这两个变量之间的关系是线性的。
数据的线性与非线性
数据的线性与非线性,与应用场景密切相关。对于拟合回归与分类,数据的线性与非线性的定义完全不同。
一组数据由多个特征和标签组成,特征为自变量,标签为因变量:
- 当这些特征分别与标签存在线性关系的时候,我们就说这一组数据是“线性数据”。
- 当特征矩阵中任意一个特征与标签之间的关系需要使用三角函数,指数函数等函数来定义,则我们就说这种数据叫做“非线性数据”。
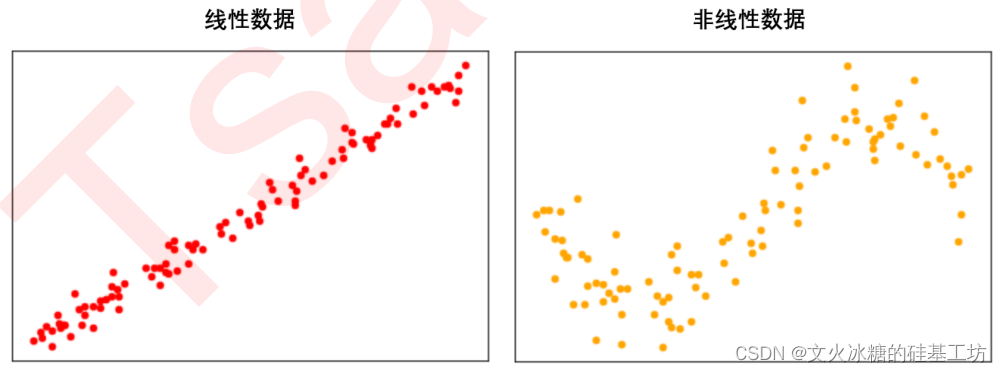
在上述图形中,特征值X是X轴上连续的数值点,标签值Y是Y轴上连续的数值点。
数据的线性可分与非线性可分
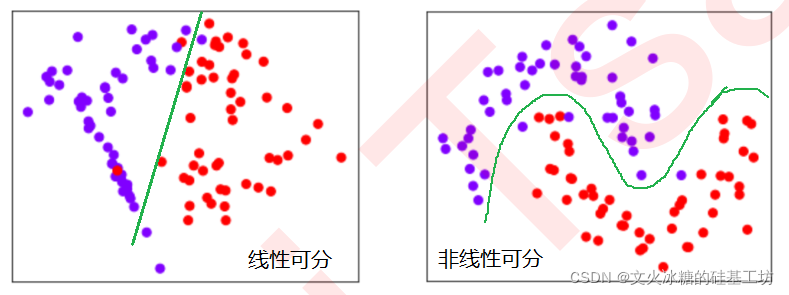
在上述图形中,特征值(X1, X2) 是平面上的连续点,标签值Y是点的颜色,是离散的。
在分类中,我们绘制的是数据分布图,横坐标是其中一个特征,纵坐标是另一个特征,标签则是数据点的颜色(类别)。因此在分类数据中,我们使用“是否线性可分”(linearly separable)这个概念来划分分类数据集。当分类数据的分布上可以使用一条直线来将两类数据分开时,我们就说数据是线性可分的。反之,数据不是线性可分的。
总之:对于分类问题,数据分布若能使用一条直线来划分或分割或隔离类别,则是线性可分的,否则数据则是线性不可分的。
模型拟合数据的思路
1、用线性模型去拟合线性分布的数据。
2、用非线性模型去拟合非线性分布的数据。也可以用非线性模型去拟合线性分布的数据。
3、可以通过通过一些特殊的数据预处理,把非线性数据转换线性分布,然后再用线性模型去拟合。

















 3277
3277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









