






注意idea提示的标黄代码,一般都是代表可以优化或者有可能出问题的点,比较好的效果是代码没有任何标黄提示
大多数情况下,编码规范是相辅相成的,全部结合起来会有1+1大于2的效果
基础
集合有关
工具类使用的使用一定要看一下文档介绍,不然可能会造成意想不到的效果
集合的初始化
集合初始化的时候尽可能指定容量;
没有值的时候优先返回空集合而不是null;
下面以List举例初始化的情况
声明空List(下面两种方式都是返回一个空的List,注意返回的是一个不可修改的特殊List实现类)
Collections.EMPTY_LIST; // 这种编译器会会报黄
Collections.emptyList();
声明普通List
Lists.newArrayList()
声明带有初始容量的List
Lists.newArrayListWithCapacity(16);
Lists.newArrayListWithExpectedSize(16); //这种方式最终的容量会大于给定值,但是官方说后面会弃用:即使在极少数情况下您确实需要一些填充量,最好还是明确选择所需的量
像Set Map 都有对应的工具类,但是使用上可能有细微差别。
其他特殊操作
快速构造一个给定区间的循环
IntStream.range(0, 10).forEach();
将给定集合按批分组
Iterables.partition(Lists.newArrayList(), 10).forEach();
不可变集合(以List举例)
注意空集合和不可变集合返回的值如果进行修改操作会直接抛出异常
ImmutableList.copyOf(Lists.newArrayList());
ImmutableList.of(new Object());
获取首个 最后一个 仅有一个的元素
PS: 这些方法搭配MoreObjects使用更佳
Iterables.getFirst(Lists.newArrayList(), new Object());
Iterables.getLast(Lists.newArrayList(), new Object());
Iterables.getOnlyElement(Lists.newArrayList()); 没有元素的时候会直接抛出异常
有关基础类型和其包装类
局部变量尽可能使用基础类型,类属性强制使用包装类,
对于类属性,null 和非null 实际上应该是有特定的意义的。
排序
用以排序的方法很多。
// 使用stream排序
from.stream().sorted(comparator).collect(Collectors.toList());
// 使用Ording
// 仅当结果列表可能需要进一步修改或可能包含null时使用此选项 稳定排序
Ordering.from(String::compareTo).sortedCopy(Collection<String>);
// 返回的是不可变有序集合
Ordering.from(String::compareTo).immutableSortedCopy(Collection<String>);
// 集合类自带sort方法
List<T>.sort(String::compareTo);
// Collections.sort(), 根据谷歌Ordering类文档中所说,性能不好,优先使用上面的几种方法
Collections.sort(List<String>, String::compareTo);
如果想同时实现排序和去重的话,用流是很好的选择,当然treeSet也可以。
null值有关
@Nullable 注解
在可能返null的方法体上,以及可能为null的函数入参、属性值上打上@Nullable注解
这个注解没有什么实际功能,主要是为编译器标明了这个方法或字段是有可能为null,;
对于标注了@Nullable的方法,一些不安全的调用会标黄提示。我们可以多关注这些地方,这样能尽可能避免空指针异常的出现。

null 和 empty
null 是有其特殊含义的,一般null值代表异常情况出现了,特别是对于集合类,没有结果应返回空集合。当有必要返回null时,应该在方法上注明 @Nullable
代码实操
注释
首先要有注释;然后不能过度注释;业务有关的注释一定要写;
推荐阅读 《代码整洁之道》 关于注释的部分;
常用Javadoc文档标记, 这个哥们总结的很细
@param
@see
@return
@link
@exception
方法变量命名
不要怕名字长,见名知意,求求不要用a,b这样的变量名
可以多阅读一些源码,学习一下优秀框架的命名风格,优秀的代码可以减少注释。
get*** 极为简单的取值,获取数据
fetch** 代表要请求远程服务器
do** 代表实际要干活的方法
***IfNeed 当满足条件时才做某种操作
resolve*** 字段解析,深层值获取
**pick**By* fiterBy*****从指定数据中选取部分作为结果
map类型指定key value, 一般是****By*Map*,比如<商品id,商品信息>的map, Map<Long,Goods> goodsByIdMap;
min** max** 包含边界值的区间
***From *To 不包含边界值的区间
is*** 是否满足某种条件
***Factory 一般代表工厂方法
***Holder 用来保管某种信息的
***Context 代表用来存储上下文信息
***Service 代表无事务的Service
***TxService 代表有事务的Service
omit*** 忽略某些值
**rejectBy** acceptBy****接受或拒绝某些值
convert*To**把转换成
…
字母拼写错误
字母拼写错这种低级错误很多地方能看到,推荐开启idea拼写检查,会有标黄提示(我改成红色了)。

多抽小方法
要确保主方法体的精简,动辄一两百行的代码肯定是有问题的,让人不想读也不敢改。
至少我现在还没见到过有什么主流程需要两百行代码才能讲清的。
最小访问权限
严格控制单个类中方法和属性的访问权限,优先使用更为严格的修饰符。
private protected public
一般抽象出来的public方法应该是一个精简的脉络,或者是进行一层简单转换,private 方法负责具体每个步骤的实现,或者核心的方法。
public 把大象放进冰箱(大象){
冰箱 = 找一个冰箱();
把大象放到指定的冰箱里(冰箱,大象);
};
public 把一群大象放进冰箱(一群大象){
for(大象 in 一群大象){
把大象放进冰箱(大象);
}
};
private 找一个冰箱(){};
private 把大象放到指定的冰箱里(冰箱,大象){};
**
**
编码时容易犯的低级错误
自己CR时要特别注意
- 关键语句没有return ,已经犯过多次了,功亏一篑。这种问题别人比较难发现。发现的时候代码可能已经上线了。
- 不同类的对象进行比较,比如枚举类和Integer直接对比。这个可以多注意idea编译器标黄提示。如果拿到的是一个object引用, 那就强转一下再比较。
字符串专栏
简单字符串拼接
String name = "小明";
int age = 18;
System.out.println(String.format("我是%s,今年%d岁", name, age));
System.out.println(MessageFormat.format("我是{0},今年{1}岁", name, age));
输出:
我是小明,今年18岁
我是小明,今年18岁
更复杂的情况可结合StringBuilder等食用
分割合并字符串
Splitter.on(";").omitEmptyStrings().splitToList(string); // 分割
Joiner.on(";").join(Iterable<?> parts); // 合并
其他
BigDecimal初始化
BigDecimal初始化不能使用double传值的构造函数,生成的值是不精确的
假设要初始化一个bigDecimal类型的小数2.99,
System.out.println(new BigDecimal(2.99D));
System.out.println(new BigDecimal("2.99"));
System.out.println(BigDecimal.valueOf(299, 2));
输出:
2.9900000000000002131628207280300557613372802734375
2.99
2.99
判断
单个对象判空
obj != null;
Objects.isNull(obj); // PS 这里使用工具类的意义不大,还让代码变长了
两方比较,当无法确定哪一方可能为null的时候
Objects.equals(new Object(), new Object());
集合判空
CollectionUtils.isNotEmpty(Lists.newArrayList());
CollectionUtils.isEmpty(Lists.newArrayList());
true Or false (使用前最好看一下该方法对null值是如何判别的)
BooleanUtils.isFalse(obj);
BooleanUtils.isTrue(obj);
BooleanUtils.isNotTrue(obj);
.....
工具类优先级问题
一般来说工具类都是久经考验的代码,但是不同组织开发的工具类实际上是有差异的。
排名一是为了统一,二是确保代码的健壮。
以下排名有先后
- java.util
- org.apache.commons
- com.google.common
- 其他工具类
序列化问题
现有的序列化工具 优先使用 Jackson, Gson。 不推荐使用FastJson,虽然FastJson更符合国人的使用习惯。
给前端返回时可以开启null字段隐藏功能,节省带宽。
校验
推荐使用 **Preconditions,**不满足表达式则抛出异常
Preconditions.checkState(true, "状态非法");
Preconditions.checkArgument(a != null, "非法入参");
为null时取默认值
注意入参不能都为空
MoreObjects.firstNonNull(obj, Collections.emptyList());
Optional.of(obj).orElse(Collections.emptyList());
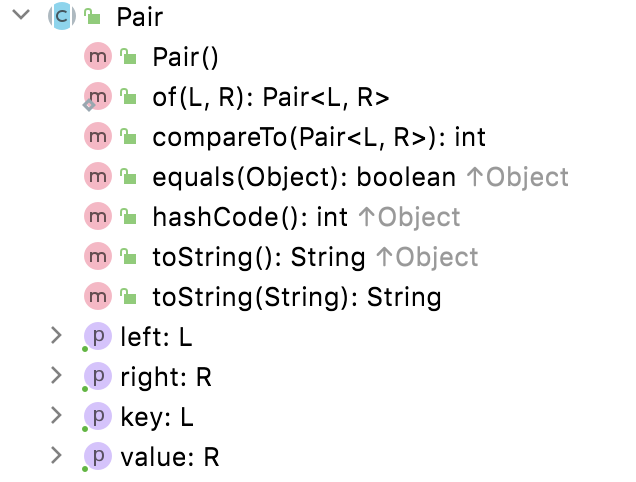
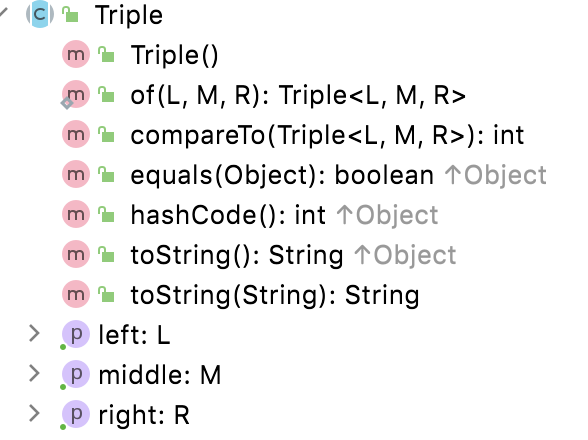
Pair 和 Triple
可以视为一种特殊的容器,不建议多用,原因和用Map返回对象一个道理,但是有些情况下也有奇效。
Stream的一些用法
# 转化为map 注意如果key是有可能冲突的最好利用第三个参数提供一个合并器 不然会直接抛出异常
stream().collect(Collectors.toMap(keyMapper, valueMapper, mergeFunction))
# 分组
stream().collect(Collectors.groupingBy(classifier));
# 拍平 把二维集合合并为一维集合
stream().flatMap(Collection::stream).collect(Collectors.toList())
# 最值
stream().max(Ordering.natural()).orElse(null)
.....
值得一提的是,guava中也提供了一些关于流好用的方法
# 多个流合并
public static <T> Stream<T> concat(Stream<? extends T>... streams)
# 流打包 接收A B两个流中同一个index的对象,返回一个新的合并对象
public static <A, B, R> Stream<R> zip(
Stream<A> streamA, Stream<B> streamB, BiFunction<? super A, ? super B, R> function);
函数式编程 不推荐修改函数入参
这是对系统的一种保护,
比如java8 Stream是很好的的函数式编程工具。不会改变原集合或数组的数据
常见的函数式接口
在方法设计的时候,可以较多将参数设置为函数式接口,这样相当于一种回调,将核心的处理逻辑暴露于更上层,也能够更专注于核心方法的实现。
下面这几种jdk提供的FunctionalInterface其实已经能满足大部分场景。
另外能用方法引用的地方最好用方法引用代替,写出精简的代码也是能力的一部分。
public interface Function<T, R>; 接收T 返回R
public interface BiFunction<T, U, R>; 接收TU 返回R
public interface Consumer<T>; 接收T,无返回
public interface Predicate<T>; 接收T 返回boolean
...
代码性能问题
现有的代码大多数情况下是可以用空间换时间的。
O(n)乃至O(1)的代码是我们不懈追求的。
O(n2)的勉强可以接受,再往上的时间复杂度肯定是有问题的。
一般来说优化是比较简单的,比如下面这种方法,复杂度是O(n2)的,优化到O(n)很简单。















 644
644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









