







针对海量大文本查重检测,Google常用的网页去重算法(Simhash)是值得学习的,详见《Similarity estimation techniques from rounding algorithms》。
从实际应用出发,结合论文资料,记录一下这个算法。【目前状态:整理中…】
下面图片来自:https://www.cnblogs.com/Hugh-Locke/p/16984094.html
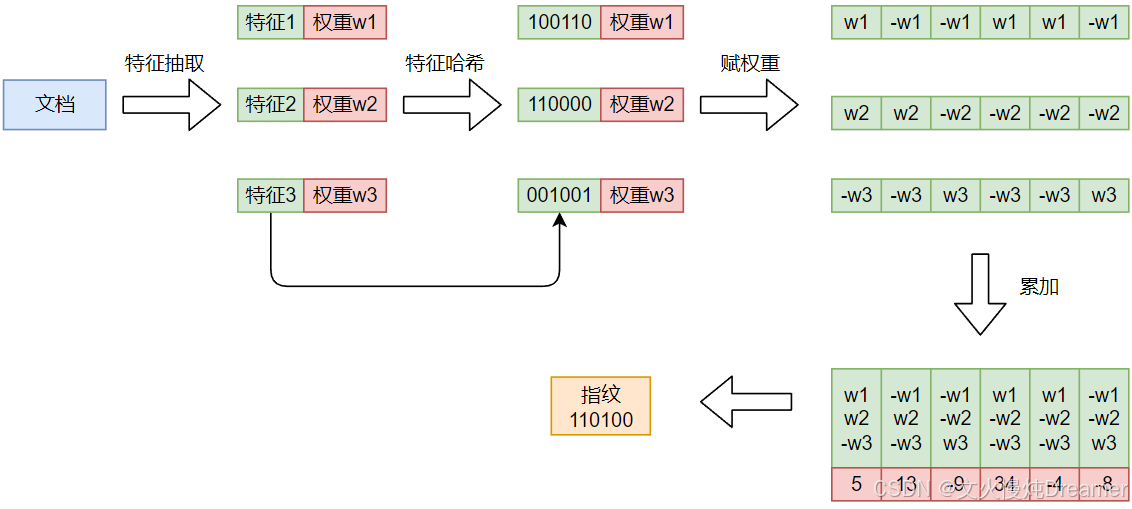
网上有很多相关理论介绍,就算图文并茂也很难彻底理解,技术工作者还是喜欢实践出真知。
找到一个Go项目:github.com/mfonda/simhash,一位佬据论文自实现的Simhash算法。先来学习学习这份算法的实现过程,再来谈谈缺陷与改进。
Simhash算法
一、算法实现过程
1、源码
从项目案例出发,先贴作者提供的代码
package main
import (
"fmt"
"github.com/mfonda/simhash"
)
func main() {
var docs = [][]byte{
[]byte("this is a test phrase"),
[]byte("this is a test phrass"),
[]byte("foo bar"),
}
hashes := make([]uint64, len(docs))
for i, d := range docs {
hashes[i] = simhash.Simhash(simhash.NewWordFeatureSet(d))
fmt.Printf("Simhash of %s: %x\n", d, hashes[i])
}
fmt.Printf("Comparison of `%s` and `%s`: %d\n", docs[0], docs[1], simhash.Compare(hashes[0], hashes[1]))
fmt.Printf("Comparison of `%s` and `%s`: %d\n", docs[0], docs[2], simhash.Compare(hashes[0], hashes[2]))
}
//Output:
//Simhash of this is a test phrase: 8c3a5f7e9ecb3f35
//Simhash of this is a test phrass: 8c3a5f7e9ecb3f21
//Simhash of foo bar: d8dbe7186bad3db3
//Comparison of `this is a test phrase` and `this is a test phrass`: 2
//Comparison of `this is a test phrase` and `foo bar`: 29
很简单的接口,把文本变成64位数值,将文本相似度转换成数值距离计算。
文本数据→simhash值
NewWordFeatureSet方法是初始化方法,旨在文本预处理,作者将所有文本转为小写,生成一个WordFeatureSet结构的实例。
// WordFeatureSet is a feature set in which each word is a feature,
// all equal weight.
type WordFeatureSet struct {
b []byte
}
func NewWordFeatureSet(b []byte) *WordFeatureSet {
fs := &WordFeatureSet{b}
fs.normalize()
return fs
}
func (w *WordFeatureSet) normalize() {
w.b = bytes.ToLower(w.b)
}
Simhash方法包括三步:1、特征值提取和计算64位hash;2、所有特征hash进行加权、合并计算;3、结果降维至[0,1]。
// Returns a 64-bit simhash of the given feature set
func Simhash(fs FeatureSet) uint64 {
return Fingerprint(Vectorize(fs.GetFeatures()))
}
具体参见源码,后面几节会从理论层面详述。✨这里仅关注第一个步骤,这是我们开发者可以参与的工作✨。
GetFeatures方法也是抽象出来的,这里调用的是WordFeatureSet的结构内部函数。(源码中还可以找到UnicodeWordFeatureSet结构的实例)
// Returns a []Feature representing each word in the byte slice
func (w *WordFeatureSet) GetFeatures() []Feature {
return getFeatures(w.b, boundaries)
}
可以发现整个初始化及特征值提取过程是完全抽象出来的,我们应用时可以按需实例化自己想要的,下面会简述。
先看下作者源码,函数实际调用的是getFeatures方法:
// Splits the given []byte using the given regexp, then returns a slice
// containing a Feature constructed from each piece matched by the regexp
func getFeatures(b []byte, r *regexp.Regexp) []Feature {
words := r.FindAll(b, -1)
features := make([]Feature, len(words))
for i, w := range words {
features[i] = NewFeature(w)
}
return features
}
// Returns a new feature representing the given byte slice, using a weight of 1
func NewFeature(f []byte) feature {
h := fnv.New64()
h.Write(f)
return feature{h.Sum64(), 1}
}
第一个参数是输入文本,第二个参数是正则过滤条件,返回[]Feature(64位hash及权重的集合)。
显然,作者先通过正则分词,再对每个词计算64-bit FNV-1 hash。
实现的比较简单,给定的正则条件是很基础的,匹配类似word、word//path这样的模式或者Unicode连续字符,且每个词的权重被硬编码为1。
simhash值→不相似度
Compare方法计算两个64位simhash值的汉明距离。
这里实现的很简单,直接比较的汉明距离,主要是因为simhash值已经体现出局部敏感了,从整体汉明距离上就可以很直观的得到一个估值。
// Compare calculates the Hamming distance between two 64-bit integers
//
// Currently, this is calculated using the Kernighan method [1]. Other methods
// exist which may be more efficient and are worth exploring at some point
//
// [1] http://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetKernighan
func Compare(a uint64, b uint64) uint8 {
v := a ^ b
var c uint8
for c = 0; v != 0; c++ {
v &= v - 1
}
return c
}
论文里有更复杂的比较算法,用以大大减轻计算负担,之后再谈这个事情吧。
2、自定义分词算法
从源码中可以看出,作者并没有给出一个很完善的分词,且所有分词等权重。
了解一点相关知识的朋友应该明白,分词越精确,权重分配越精准,数据语义越完整,即文本影射成数字所反应的信息越准确。
从代码中我们可以找到两个接口Feature、FeatureSet ,这是我们可以自定义实例化的地方。
// Feature consists of a 64-bit hash and a weight
type Feature interface {
// Sum returns the 64-bit sum of this feature
Sum() uint64
// Weight returns the weight of this feature
Weight() int
}
// FeatureSet represents a set of features in a given document
type FeatureSet interface {
GetFeatures() []Feature
}
我们可以模仿着写一个自定义的实现
type MyFeatureSet struct {
b []byte
}
func NewMyFeatureSet(text []byte) *MyFeatureSet {
return &MyFeatureSet{b: bytes.ToLower(text)}
}
func (w *MyFeatureSet) GetFeatures() []simhash.Feature {
lines := customeSegment(w.b) // 你想要的分词模式,比如按空格分词:bytes.Split(w.b, []byte(" "))
features := make([]simhash.Feature, len(lines))
for i, w := range lines {
features[i] = customeFeature(w) // 也可以直接调用等权重方案 simhash.NewFeature(w)
}
return features
}
你可以自己定义你想要的分词customeSegment方法和特征值提取customeFeature方法。建议使用64-bit FNV-1 hash,如果要使用更多比特的哈希,那记得同步改掉库中的加权合并降维算法。
使用时直接将最前面提到的项目案例中的simhash.NewWordFeatureSet(d)替换成你的NewMyFeatureSet方法就可以啦~
二、分词
英文分词相对容易,毕竟有空格分隔,中文分词是一个比较麻烦的点,目前还没有一个绝对完美的实现。
nlp有很多分词算法,笔者还在学习中,有机会出一期分词的研究,这里简述我针对Go库的调研,找了三类GitHub收藏量过千的库:
sego
- 功能:
- 支持两种分词模式:普通和搜索引擎
- 支持用户词典、词性标注
- 可运行JSON RPC服务
- 主要设计算法:
- 基于双数组trie(Double-Array Trie)实现词典;
- 基于动态规划,词频最短路径,实现分词器算法。
- 分词速度
- 单线程9MB/s
- goroutines并发42MB/s(8核Macbook Pro)。
- 相关库
- Go:https://github.com/huichen/sego
jieba 应用最广的主流库
- 功能:
- 支持三种模式:精确模式、全模式、搜索引擎模式。
- 精确模式:试图将句子最精确地切开,适合文本分析;
- 全模式:扫描句子中所有的可以成词的词语,速度非常快,但是不能解决歧义;
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- 支持繁体分词
- 支持自定义词典,添加新词
- 核心算法底层由C++实现,性能高效。
- 主要涉及算法:
- 基于前缀词典实现高效词图扫描;
- 生成所有可能成词情况所构成的有向无环图 (DAG);
- 采用动态规划查找最大概率路径, 找出基于词频的最大切分组合;
- 基于汉字成词能力的 HMM 模型(隐马尔可夫模型),采用Viterbi算法识别未登录词;
- 相关库
- Python:https://github.com/fxsjy/jieba
- 还支持paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。同时支持词性标注。paddle模式使用需安装paddlepaddle-tiny,pip
install paddlepaddle-tiny==1.6.1。目前paddle模式支持jieba v0.40及以上版本。jieba
v0.40以下版本,请升级jieba,pip install jieba --upgrade 。- Go:https://github.com/yanyiwu/gojieba
- Go:https://github.com/wangbin/jiebago
- Java:https://github.com/huaban/jieba-analysis?tab=readme-ov-file
gse 新库,基于jieba分词,增添NLP功能和更多属性
- 功能:
- 支持多种分词模式:普通、搜索引擎、全模式、精确模式和 HMM 模式
- 支持自定义词典、embed 词典、词性标注、停用词、整理分析分词
- 支持多语言分词: 英文, 中文, 日文等
- 支持繁体分词
- NLP 和 TensorFlow 支持 (进行中)
- 命名实体识别 (进行中)
- 支持接入 Elasticsearch 和 bleve
- 可运行 JSON RPC 服务
- 主要设计算法:
- 基于双数组trie(Double-Array Trie)实现词典;
- 生成DAG
- 动态规划查找词频最短路径,实现分词器算法
- HMM 算法分词, viterbi 算法
- 分词速度:
- 单线程 9.2MB/s
- goroutines 并发 26.8MB/s.
- HMM 模式单线程分词速度 3.2MB/s.(双核 4 线程 Macbook Pro)。
- 相关库
大家可以参考学习,简单一点实现分词的话,就模仿作者的正则,或者bytes.Split个性化分割吧🤪
三、加权
我去年也写了一些网页相似度检测算法,无论是动态规划还是特征向量,性能都很一般,用上递归就是很吃性能。
1、TF-IDF算法
网上有文章建议TF-IDF算法:
TF——词频。衡量一个词在一个文档中出现的频率,计算方法是该词在文档中出现的次数除以文档总词数。这反映了词在文档中的相对频率,有助于识别出文档中最常用的词汇。
IDF——逆文档频率。衡量一个词在整个文档集中的普遍程度,计算方法是对文档总数除以包含该词的文档数,然后取对数。这个步骤确保了即使在文档中频繁出现的通用词汇也不会获得过高的权重,因为它们在大多数文档中都可能出现。
TF-IDF值:最终的tf-idf值是通过将词频与逆文档频率相乘得出的。这种方法综合考虑了词在特定文档中的重要性和在整个文档集中的独特性,使得那些在特定文档中频繁出现但又不太常见的词获得更高的权重。
假设一份文档,我们对其按行分组,再对每一行分词。词频(TF)就是全文档统计每个词出现的频率,逆文档频(IDF)就是基于行统计每个词出现的行普遍性。
T F w = 某个词 w 的个数 所有词的个数 TF_w= \frac{某个词w的个数}{所有词的个数} TFw=所有词的个数某个词w的个数
I D F w = l o g ( 行总数 含 w 的行数 + 1 ) IDF_w= log(\frac{行总数}{含w的行数+1}) IDFw=log(含w的行数+1行总数)
上述分母的加1是为了避免分母为0的情况
某个词w的重要程度是:
[ T F w − I D F w ] = T F w ∗ I D F w [TF_w-IDF_w]= TF_w*IDF_w [TFw−IDFw]=TFw∗IDFw
我参考网上代码尝试复现了一下这个算法,效果并不太好:
type wordTfIdf struct {
nworld string
value float64
}
type wordTfIdfs []wordTfIdf
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
func (us wordTfIdfs) Len() int {
return len(us)
}
func (us wordTfIdfs) Less(i, j int) bool {
return us[i].value > us[j].value
}
func (us wordTfIdfs) Swap(i, j int) {
us[i], us[j] = us[j], us[i]
}
func FeatureSelect(list_words [][]string) wordTfIdfs {
docFrequency := make(map[string]float64, 0) //每个词的个数统计
sumWorlds := 0 //所有词的个数统计
wordTf := make(map[string]float64) //每个词的词频(IF)
docNum := float64(len(list_words)) //文档行总数统计
wordDoc := make(map[string]float64, 0) //每个词的行计数
wordIdf := make(map[string]float64) //每个词的逆文档频(IDF)
/*IF计算*/
for _, wordList := range list_words {
for _, word := range wordList {
docFrequency[word] += 1
sumWorlds++
}
}
for k, _ := range docFrequency {
wordTf[k] = docFrequency[k] / float64(sumWorlds)
}
/*IDF计算*/
for _, wordList := range list_words {
for _, word := range wordList {
if _, ok := docFrequency[word]; ok {
wordDoc[word] += 1 //该行有词即可计数,不需统计有几个词
break
}
}
}
var wordifS wordTfIdfs //写map结构可能更方便,但当时就是写了这种结构。。。
for k, _ := range docFrequency {
wordIdf[k] = math.Log(docNum / (wordDoc[k] + 1))
// 可以直接算IF-IDF
var wti wordTfIdf
wti.nworld = k
wti.value = wordTf[k] * wordIdf[k]
wordifS = append(wordifS, wti)
}
sort.Sort(wordifS)
fmt.Println(wordifS)
return wordifS
}
这个算法是存在缺陷的,一个词在文档中分布更普遍,并不代表它不重要。
2、DOM树衰减
对于网页结构相似度,我觉得可以采用我之前的文章建议:定义衰减因子,DOM节点在DOM树中的重要程度作为权重。(虽然但是,递归确实耗性能的)
/*Dom树生成与权重递减赋值*/
const Decay = 0.45 //递减因子
func GetDomTree(htmlContent []byte) map[string]float64 {
//htmlContent为空时也能解析html,解析出三个元素:html,head,body;也会参与simhash计算。需要确定需求。
doc, err := html.Parse(bytes.NewReader(htmlContent))
if err != nil {
logger.Error("Failed to parse HTML document: ", err)
return nil
}
a := make(map[string]float64)
traverse(doc, 1, a)
return a
}
func traverse(node *html.Node, val float64, highWeight map[string]float64) {
if node.Type == html.ElementNode {
tag := node.Data
//fmt.Println("Tag:", tag)
var v float64
if v_, ok := highWeight[tag]; !ok {
v = v_
}
highWeight[tag] = v + val
}
for child := node.FirstChild; child != nil; child = child.NextSibling {
traverse(child, val*Decay, highWeight)
}
}
相对而言,这个算法评估网站结构相似度是要更精确一点的。
原理就是类似的网站在外形上看起来一致,我们更在乎整个网页结构的大框架,而对于具体内容是数字、表格还是图片啥的不是很关心,参考:不同人写的新浪文章。
你要是想评估文章内容的相似度,或许IF-IDF算法更合适一点。
上述递减因子定义为多少合适,还是需要多做尝试。多次测试来评估:递减因子为多少时,可以让相似网页和不相似网页控制在一个较稳定的区间内。(我自己测试新浪、网易、博客园等等网页,0.45还可以,最终simhash的compare结果在5以内的是相似页面)
3、其他
或许还有更好的做法,后续收集到会补充。
4、如何加权?
我们分词后,会对每个词做hash,得到64位的01字符串。
加权前,我们会将字符串中所有的1视为正数,所有的0视为负数,让他们乘上权重。
借网友案例:比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
四、合并
现在,我们得到了所有词的64位字符串,我们要合并成一个64位字符串,即按位累加。
借网友案例:比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4±5 -4+5 4±5 -4+5 4+5” ==> “9 -9 1 -1 1 9”。
五、降维
现在,我们得到了唯一的64位字符串来局部反应整个文档的信息熵。
为了便于计算,我们对该数据降维,得到一个64位的01字符串。
主要工作是:大于0的数映射为1,小于0的数映射为0
借网友案例:比如 “9 -9 1 -1 1 9” 降维为:“1 0 1 0 1 1”。
六、汉明距离
论文里有提到Jaccard相似度,很有意思。
百度百科:杰卡德距离(Jaccard Distance)是用来衡量两个集合差异性的一种指标,它是杰卡德相似系数的补集,被定义为1减去Jaccard相似系数。而杰卡德相似系数(Jaccard similarity coefficient),也称杰卡德指数(Jaccard Index),是用来衡量两个集合相似度的一种指标。
Jaccard相似指数用来度量两个集合之间的相似性,它被定义为两个集合交集的元素个数除以并集的元素个数:
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B)=\frac{| A \cap B |}{| A \cup B |} J(A,B)=∣A∪B∣∣A∩B∣
Jaccard距离用来度量两个集合之间的差异性,它是Jaccard的相似系数的补集,被定义为1减去Jaccard相似系数:
d J ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ d_J(A,B)=1-J(A,B)=\frac{| A \cup B |-| A \cap B |}{| A \cup B |} dJ(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
给定两个集合A,B,jaccard值越大说明相似度越高。
在信息理论中,Hamming Distance 表示两个等长字符串在对应位置上不同字符的数目,我们以d(x, y)表示字符串x和y之间的汉明距离。从另外一个方面看,汉明距离度量了通过替换字符的方式将字符串x变成y所需要的最小的替换次数。(来源:【深度好文】simhash文本去重流程)
七、hash与simhash区别
关于哈希算法没啥好提的,我们主要目的就是想把文字变成数字处理,而一点点改动都会使得文本的hash值大相径庭,所以我们才会想到局部敏感哈希算法(Locality Sensitive Hashing),最具代表性的就是simhash算法。对于网上提到过的Shingling算法、I-Match算法等,以后再提,效果不算好。
工程里作者使用了64-bit FNV-1 hash,你也可以使用更多比特的哈希算法(比如128bit、256bit),那记得同步改掉库中的加权合并降维算法,因为库里是按64bit计算的。
数字越长,信息熵越大,相对的就是计算成本会高,具体还是看实际需求,某些文本计算需求或许不在乎微小的计算成本,但对于更海量的文本数据,你需要花更多地心思去权衡考量。
[Algorithm] 使用SimHash进行海量文本去重,这篇解释得就挺好的:

【注】文档不完整,还会继续补充…
参考
《Similarity estimation techniques from rounding algorithms》
海量数据相似度计算之simhash和海明距离
这就是搜索引擎(8) 网页去重
【深度好文】simhash文本去重流程
[Algorithm] 使用SimHash进行海量文本去重
基于局部敏感哈希的协同过滤算法之simHash算法
https://github.com/mfonda/simhash

















 3225
3225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









