







记录看到的一篇 百度 在2009年发明的专利:网页结构相似性确定方法及装置
【目的】用于批量查找具有相似模板特征向量的作弊网站
【中心思想】
专利中的图示:
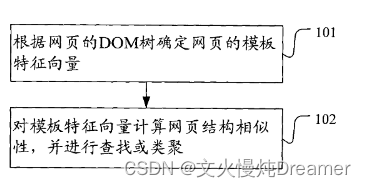
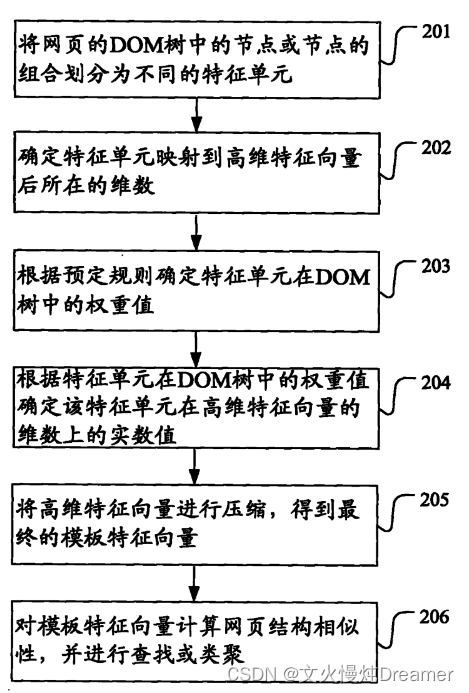
【注】根据个人理解(也可能是曲解,毕竟专利大家都懂,不会写的很准确),我暂且记录我理解的部分:
一、提取“特征单元”
对于特征单元的定义,专利并没有给出明确标准:
特征单元 = { 单个 D O M 节点 D O M 节点组合 { 当前 D O M 节点 + 其兄弟节点 当前 D O M 节点 + 其父节点 特征单元 = \begin{cases} 单个DOM节点 \\ DOM节点组合 \begin{cases} 当前DOM节点 + 其兄弟节点 \\ 当前DOM节点 + 其父节点 \\ \end{cases} \\ \end{cases} 特征单元=⎩ ⎨ ⎧单个DOM节点DOM节点组合{当前DOM节点+其兄弟节点当前DOM节点+其父节点
二、映射“高维特征向量”
关键有三点:
- 拼接字符串(即把上面特征单元的HTML标签名称及其相关属性拼接,属性包括但不限于id、class、name、style…)
- 哈希运算(借助hash函数,将字符串转换为哈希值)
- 确定高维特征向量的维数(即哈希值)
三、确定“权重”
权重即为该DOM节点在DOM树中的重要程度。
这里提到一个定义——衰减因子。确定权重需要定义初始值和衰减因子,然后根据“预定规则”进行权重衰减或累加。原文中的“预定规则”包括:
- 随深度递减。原文认为内层内容差异不重要,为提高效率,需确定有限深度(即忽略低权重部分)
- 随兄弟节点重复递减。原文估计觉得同级节点只重点关注前面的即可。
- 随无关性递减。原文认为应忽略注释语句、换行语句等不重要的排版
累加是指重复维数(节点)
四、对应高维特征向量的“实数值”
专利视 权重值 为高维特征向量对应维数的 实数值
个人理解为确定【维数:权重】键值对
专利中的图示:
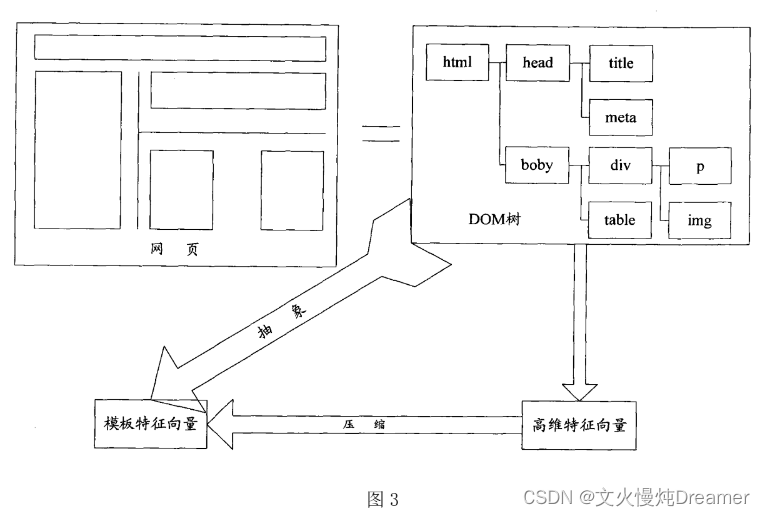
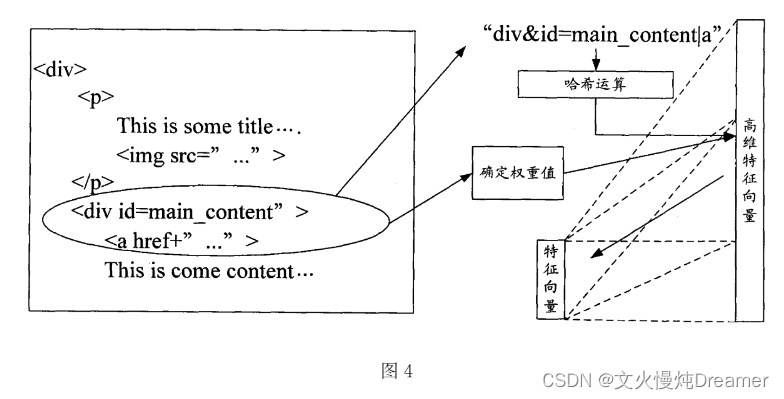
五、维数压缩,得到“模板特征向量”
这里主要解决维数取值过大问题,毕竟过大也是为了解决哈希冲突,但不利于最终计算。
关键思想:维数取模,权重叠加
将M维降到N维,1<=N<M;
模运算后余数相同的高维特征向量的实数值(权重)相加
个人理解为确定【维数余数:权重和】键值对
六、快速处理
将实数值离散至网格。
这一步没太看懂,个人理解为L:把这些值分布在网格中(然后小数向上或者向下取整)。
最后计算伪距离:
d
i
s
t
(
U
,
V
)
=
∑
i
(
∣
U
i
−
V
i
∣
)
∑
i
(
min
{
U
i
,
V
i
}
)
dist(U,V)= {\sum_i(|U_i-V_i|) \over \sum_i(\min \lbrace U_i,V_i \rbrace)}
dist(U,V)=∑i(min{Ui,Vi})∑i(∣Ui−Vi∣)
(所有维的差值和/所有维的共同部分和)
浅试一下
按照权重初值为1,递减因子为0.9,暂不忽略低权重(因为很多元素都比较深,不好划定深度),暂不做网格处理,浅试一下。
func HighDimensionalEigenvector(root *cdp.Node, val float64, highWeight map[int]float64) {
//高维特征向量的维数及权重
if root.NodeName == "#text" || root.NodeName == "#comment" || root.ChildNodeCount == 0 {
val *= global.Decay //无关性递减
}
hash := int(tools.FNVHash(root.NodeName + strings.Join(root.Attributes, "") + root.NodeValue))
var v float64
if v_, ok := highWeight[hash%100]; !ok {
v = v_
}
highWeight[hash%100] = v + val
for _, child := range root.Children {
//if i > 20 {
// break
//}
HighDimensionalEigenvector(child, val*global.Decay, highWeight) //深度递减
val *= global.Decay //兄弟递减
}
}
func Compute(highWeight1, highWeight2 map[int]float64) float64 {
var count, same float64
for i := 0; i < 100; i++ {
var v1, v2 float64
var ok bool
if v1, ok = highWeight1[i]; !ok {
count += v1
continue
}
if v2, ok = highWeight2[i]; !ok {
count += v2
continue
}
count += math.Abs(v1 - v2)
if v1 == v2 {
same += math.Min(v1, v2)
}
}
fmt.Println("差值和:", count)
fmt.Println("共同部分和:", same)
return count / same
}
注:由于实现方法和原文结果有出入,所以结果也有出入,浮点精度计算容易不准确。
其他内容和之前写的算法差不多,写法肯定是和原专利有很多不同的,也肯定有理解错误的地方,还请大佬指正!!
即便如此不同页面和相同页面还是有差距的:
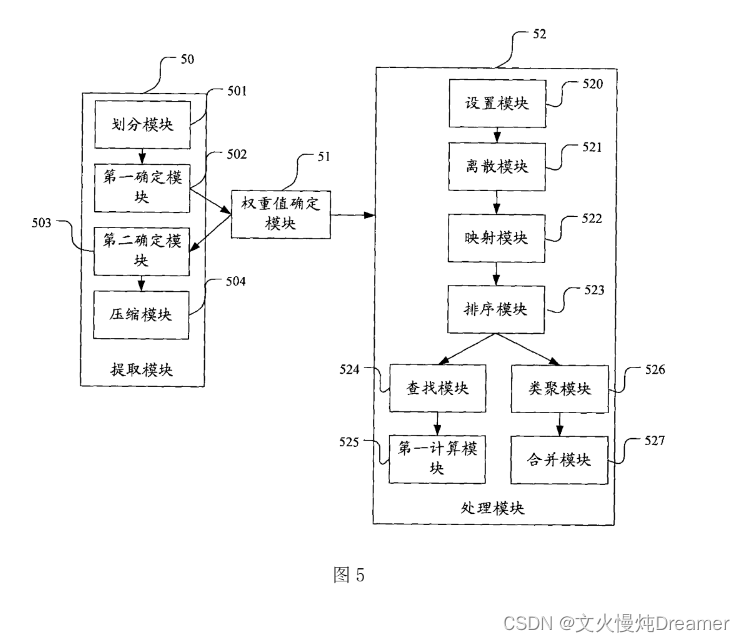
【相似页面】
Url1 =
https://blog.csdn.net/qq_40119224/article/details/132446697?spm=1001.2014.3001.5502
Url2 =https://blog.csdn.net/qq_40119224/article/details/132598415?spm=1001.2014.3001.5502
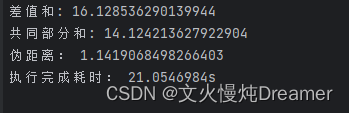
【不相似页面】
Url1 =
https://blog.csdn.net/qq_40119224/article/details/132446697?spm=1001.2014.3001.5502
Url2 =https://www.sina.com.cn/
【求知若渴】

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









