







用了很久的声码器,但是细节一直似懂非懂,详细看一下
附上一篇写得很好的文章https://zhuanlan.zhihu.com/p/54952637
abstract
LPCNet,是wavenet的变种,把线性预测和循环神经网络结合在一起,大大提升了合成的效率。证明:(1)同样网络尺寸时,LPCNet比Wavenet的合成质量好;(2)LPCNet可以在3 GFLOPS的算力下实现很好的合成质量。
introduction
- Wavenet网络声码器的弊端:算力消耗比较大
- 传统声码器:使用线性预测建模谱包络(spectral envelope , vocal tract response声道响应激励);但是对于激励(excitation)就没有这么简单的模型,尽管对于此有一些研究,但是并不理想。
- LPCNet,网络用来单独建模激励,谱包络建模的部分用线性预测做,因此可以用更少的神经元达到好的效果。
WaveRNN
LPCNet是基于WaveRNN改进的,wavernn主要包括一个GRU,两层全连接,还有一层softmax。
输入是上一帧语音
s
t
−
1
s_{t - 1}
st−1,conditioning parameter
f
f
f,输出离散的概率分布
P
s
t
P_{s_t}
Pst
16bit model: 8bit粗划分,8bit细划分,本文没有继续采用,所以没有细说

还有进一步通过使WaveRNN矩阵稀疏以及0-1话的操作都可以进一步提升效率。
LPCNet

网络分成两部分,从语音提取特征的frame-rate network,输入(10ms,160样点)提取到embedding之后,语音合成只基于样点进行的,在sample-rate network中进行。
补充
训练时既有语音,又有特征输入,预测的时候只有特征输入,为了缓解这种mismatch,(1)加噪;(2)
p
t
p_t
pt是从特征中恢复的LPC,而不是直接从wav中得到的

e
t
=
s
t
−
p
t
e_t=s_t-p_t
et=st−pt也是残差训练的由来
训练和测试的两点mismatch
(1)训练的时候sample rate net的$ s_{t-1}
输
入
的
是
真
实
数
据
,
而
不
是
预
测
的
数
据
,
输入的是真实数据,而不是预测的数据,
输入的是真实数据,而不是预测的数据,p_t
是
预
测
的
数
据
;
而
测
试
的
时
候
没
有
真
实
数
据
。
这
一
点
会
有
一
些
不
匹
配
(
是预测的数据;而测试的时候没有真实数据。这一点会有一些不匹配(
是预测的数据;而测试的时候没有真实数据。这一点会有一些不匹配(p_t$的使用方法会减少mismatch);
(2)测试时仅有特征输入,通过零初始化的历史语音样值循环生成激励样值和语音样值,显然不一致,因此对输入语音做加噪处理以缓解 mismatch
此外为了增加训练数据的多样性(能量分布更多样),让原始语音反复经过一些随机的二阶 IIR 滤波器(零极点均在单位圆内的最小相位系统),这些滤波器的 gain 是随机的
特征提取

单独考虑声码器,特征从原始语音中提取。
特征包含18维的BFCC+1维picth(F0倒数)+1维互相关系数
BFCC 通过如下过程获得(和 MFCC 提取非常一致,二者仅在频带划分有差异)
- 波形数据通过 FFT 到频谱
- 频谱按 Bark 频率分成 18 个频带,计算每个频带内的能量(通过三角窗加权,也可以理解为三角滤波获取频谱包络)
- Log 压缩动态范围得到倒谱
- DCT 去相关得到最终的 BFCC
pitch 参数通过一个基于互相关函数的 open-loop search 获得
3.1 Conditioning Parameters
经过frame-rate network的输出,见上图细节。
3.2 Pre-emphasis and Quantization
像WaveNet会用8-bit的 μ l a w \mu law μlaw将输出数值规整到256以内。 但是对于语音,通常会更关注低频段, μ l a w \mu law μlaw的白量化噪声在高频段通常时候可以听到的,尤其对于16k有一个更大的高频倾斜。因此,有的工作会用16 bit的量化。
- 本文用一阶预增强滤波器 E ( Z ) = 1 − α z − 1 E(Z)=1-\alpha z^{-1} E(Z)=1−αz−1, 实验论证 α = 0.85 \alpha =0.85 α=0.85时效果最好,
- 最终合成输出时再经过一个反转 D ( Z ) = 1 1 − α z − 1 D(Z)=\frac{1}{ 1-\alpha z^{-1}} D(Z)=1−αz−11,de-emphasis
这样操作的使得噪声在奈奎斯特频率下的能量降低了16dB。大大减少了感知噪声并且将8-bit的 μ l a w \mu _{law} μlaw用于高质量的语音合成。
3.3 Linear Prediction
网络声码器没有对语音做任何先验假设,直接用网络建模<glottal pulses, noise excitation, the response of the vocal tract>。
其中vocal tract response可以通过一个全极点滤波器建模
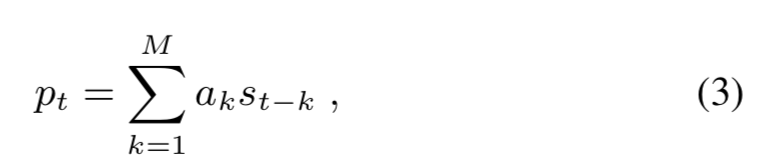
其中
s
t
s_t
st是
t
t
t时刻的语音信号;
a
k
a_k
ak是当前帧
M
t
h
M^{th}
Mth的线形预测系数(LPC)
-
a k a_k ak的计算方式—首先将18-d Bark频谱转成线性频域功率谱密度PSD(去filter),然后PSD用逆傅立叶变换IFFT转成自相关。然后用LD算法从自相关中算predictor(求解LPC自相关系数,在数据比较大,矩阵求逆比较困难时用)。从谱中计算predictor,确保不会迁移额外的信息。尽管这种方式计算的LPC分析不够精确(因为谱的低分辨率),但是在输出的影响是比较小的,因为网络能够去补偿。这是优于open-loop filter方法的地方。
-
用网络声源震动而不是采样值的方式,不仅降低了建模的难度,而且会轻微缓解 μ l a w \mu_{law} μlaw量化带来的噪声,因为生成激励的幅度远小于预增强之后的信号。输入包括上一时刻的激励 e t − 1 e_{t-1} et−1,上一个信号 s t − 1 s_{t-1} st−1。还有当前的prediction p t p_t pt。把 p t p_t pt和 s t − 1 s_{t-1} st−1包含在内是因为open-loop 在仅基于 e t − 1 e_{t-1} et−1合成时效果比较差
3.4 output layer
为了能够更好的计算输出层的概率,同时不把前一层搞得很复杂,作者提出了Dual-FC,定义是(4),将两个全连接层的输出element-wise相加。
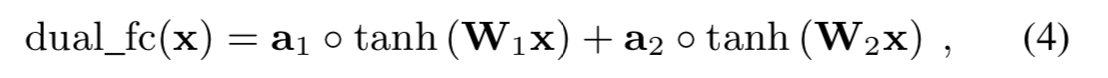
在把DualFC和一个常规的很复杂的全连接层相比时,质量会有改进。这在理论上也是可以解释的:确定一个值是否在特定区域内下降(
μ
l
a
w
\mu_law
μlaw的量化间隔)需要两次比较,每一个全连接层的tanh完成一次。并且把网络层的输出打印出来,也是支持这个分析的。
最后经过一个softmax处理,得到
e
t
e_t
et的概率
P
(
e
t
)
P(e_t)
P(et)。
3.5 Sparse Matrices
element-by-element的稀疏会阻碍有效的向量化,我们用的是block稀疏。首先是dense matric,然后强制有最小幅度的块数值为0,直到达到想要的稀疏性。发现16*1的块精度最好,同时向量化也容易。
除了非零块,我们还包括稀疏矩阵中的所有对角项,因为它们最有可能是非零的。即使它们不是水平或垂直对齐的,对角线项也很容易向量化,因为它们会导致元素与向量操作数的乘法。引入对角线项可以避免仅对对角线上的一个元素强制16x1非零块。
3.6 Embedding and Algebraic Simplifications
代数简化
3.7 Sampling from Probability Distribution
从输出分布中直接采样会产生较多的噪声,做一个处理
(1)step 1: 从pitch correlation( 0 < g p < 1 0<g_p<1 0<gp<1)得到c,
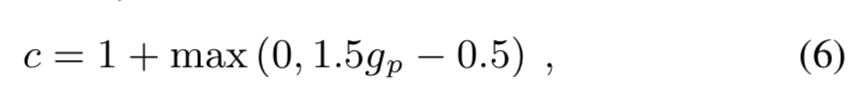
(2) step2: 从概率中提取一个常数,确保常数阈值T以下的都是0,避免低概率的引发impulse noise。 发现:T=0.002时可以在impulse noise和合成语音自然度之间去一个折衷。
R
(
∗
)
R(*)
R(∗)代表denormalize操作
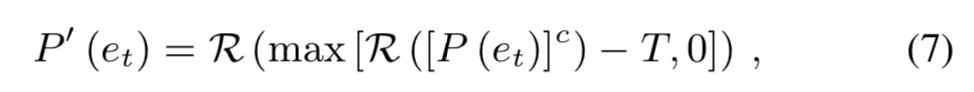
3.8 Training Noise Injection

合成语音的时候,处理的语音和训练集不同,这个不匹配会造成很大的失真,为了增强模型的鲁棒性,在训练的时候插入噪声。
线性预测使得插入噪声的细节非常重要:当在语音中插入噪声,但是网络用干净的激励训练时,发现系统会生成和合成滤波器形状一样的噪声,按照图2方式添加时,网络可以在信号上很好的建模,因为尽管它的输出和是预测的残差,输入之一是用于计算residual的。和CELP很像,极大减少了合成的artifacts.
为了使得噪声和信号幅度成比例,在u_law域添加,分布从没有噪声到【-3,3】。
4. evaluation
复杂度比较:LPCNet的复杂度主要来源于两个GRU和DualFC,计算是在2.8GFLOPS
WaveNet是在16GFLOPS; WaveRNN,10GFLOPS;SampleRNN 50GFLOPS
source-filter model
source-filter模型是假设声源独立。信源部分就是声带震动,发清音时没有震动就用白噪声建模,发浊音时喉咙有震动就用脉冲串建模;信道部分就是发不同音时口腔、鼻腔、舌头、嘴唇这些配合形成的通道,filter。这是上世纪70年代的东西,也是 LPC10、CELP、MELP 等 codec 的理论基础。

glottal spectrum/pulse声门脉冲
vocal tract response 声道响应
参考:
【1】知乎https://zhuanlan.zhihu.com/p/54952637















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









