






- 2023interspeech
- congyahuan,
- bytedance
- demo page,效果还挺好的
abstract
- 通常TTS收集的数据都是单语种,单风格的,也就是说语言和音色绑定,风格和音色绑定。为了解决这些问题,作者提出GenerTTS,(1)hubert-based bottleneck解耦音色和发音/风格,(2)使用互信息,mutual info,最小化style和语言之间的关系;
introduction
- 常用的解耦方法包括:(1)gradient reversal layer (GRL),缺点是不稳定;(2)数据增广,比如使用VC,但是链路复杂,而且增广数据作为gt,可能会损失生成质量;
- 作者对比各种特征(ppgs/bn/wav2vec/hubert),发现特定层的hubert特征+合适的channel size可以实现比较好的保留了风格和发音信息,解耦音色信息。
- huebrt训练过程:MFCC特征用kmeans 聚类,结果作为第一阶段的训练target;第一阶段的结果重新kmeans聚类,作为第二阶段的结果;第三阶段如此重复,得到比较好的acoustic pseudo-label 。
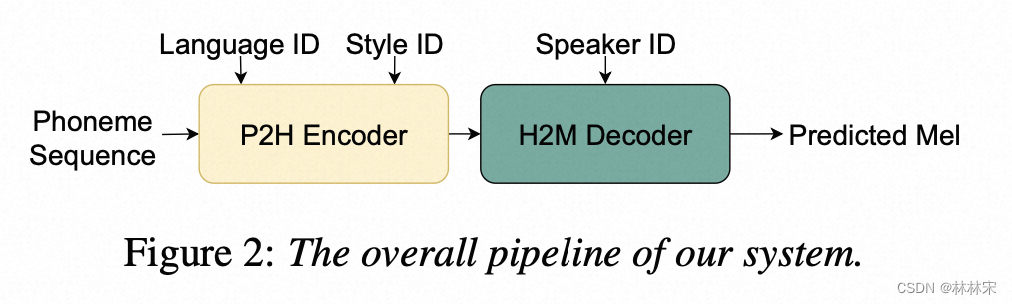
methods
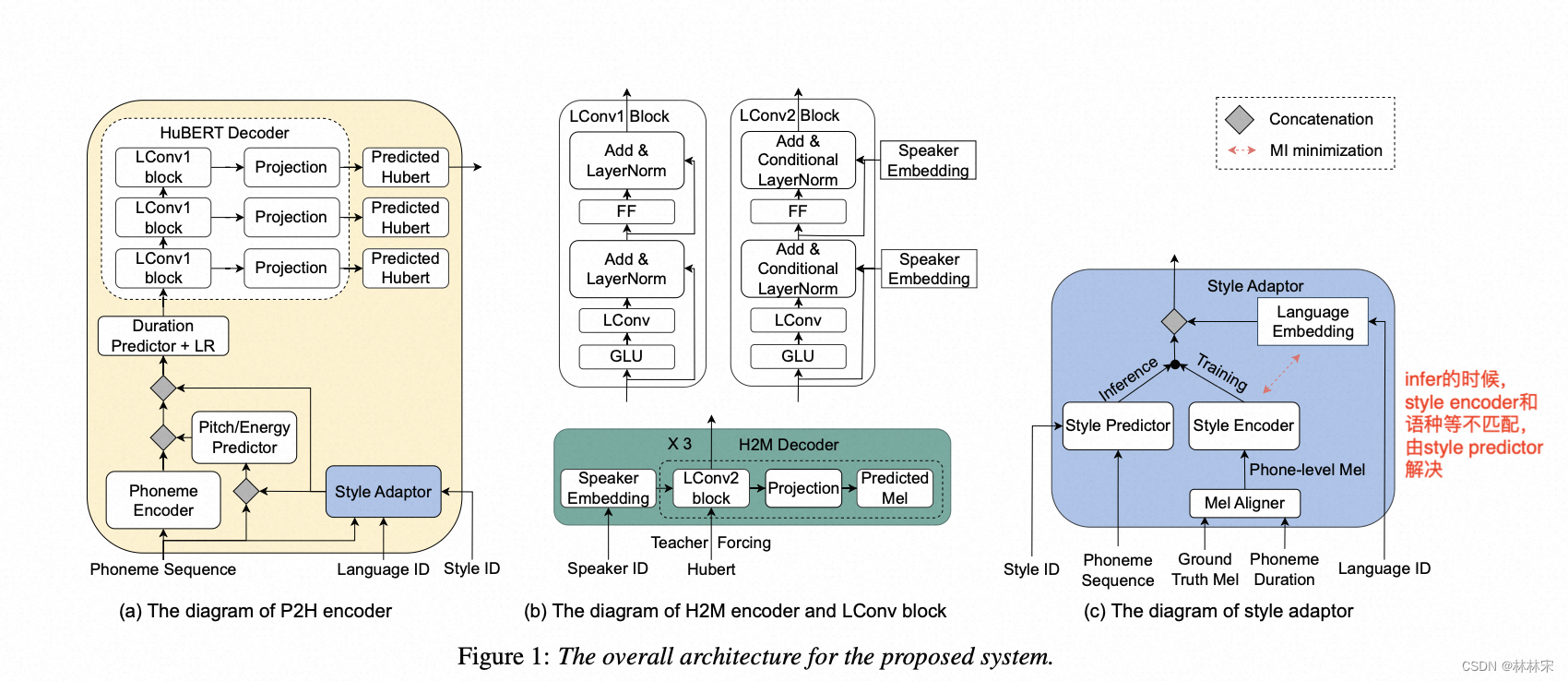
- 使用了hubert embedding作为中间预测的目标特征【连续域】;
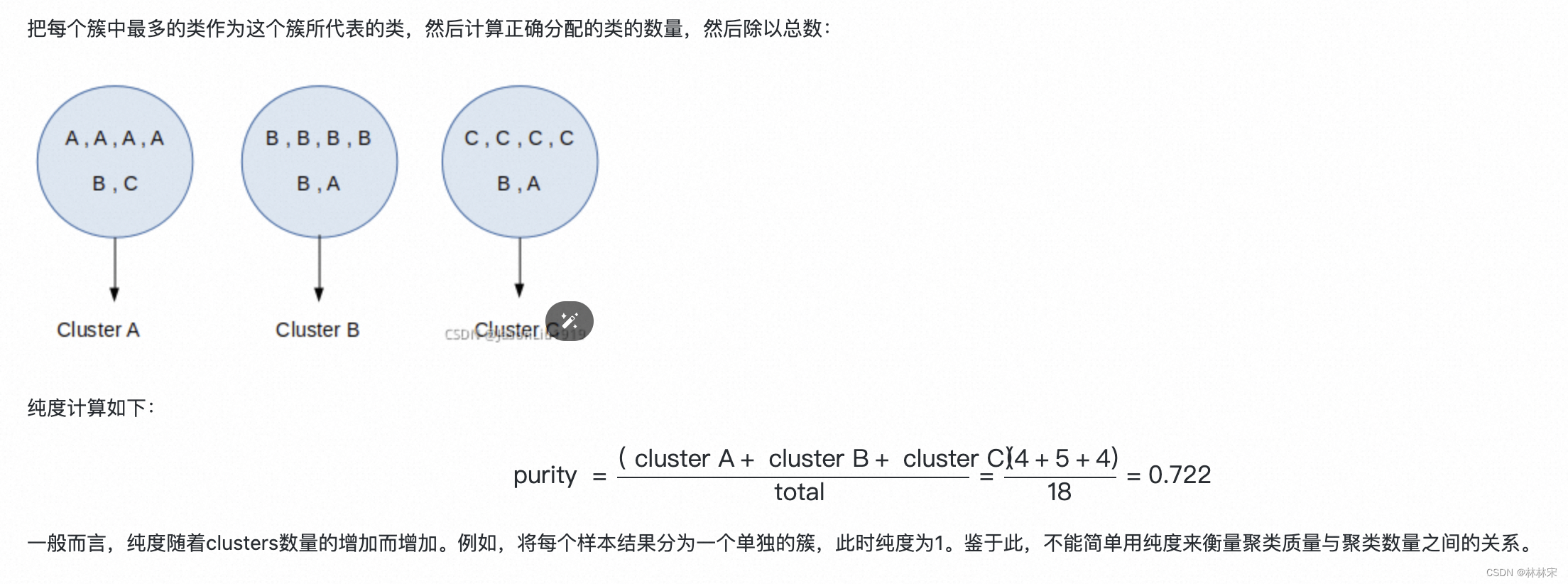
- 为了对比不同层的hubert 信息剩余的发音/风格/音色信息,对13层特征进行kmeans聚类,分别200/500/1000类,计算Cluster Purity 和 Phone-Normalized Mutual Information (PNMI) 【参考hubert & CLUB论文提出的设计】;
- Cluster Purity: 计算聚类的纯度,数值越高越好,说明每个簇中包含其他类别的概率比较低;
- PNMI:音素归一化互信息,
- style adaptor:预测音素级别的style 风格,和语言的embedding求互信息。
- 互信息约束作为风格解耦的任务也用在VC中,比如git代码,Speech Representation Disentanglement with Adversarial Mutual Information Learning for One-shot Voice Conversion
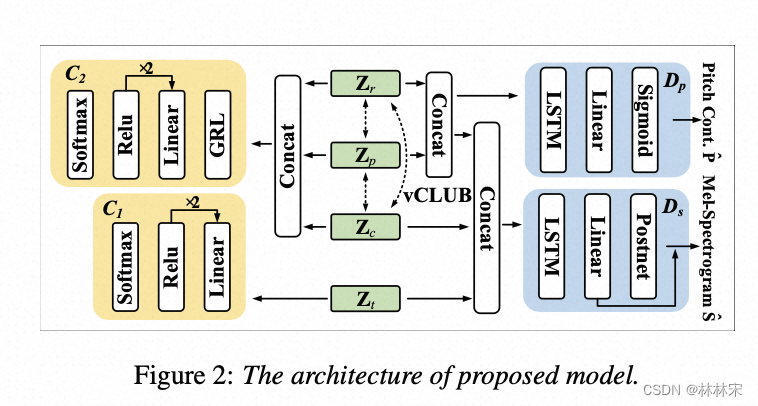
- pitch和content,韵律分别求互信息;
- 代码实现
# x: content, y: pitch
def mi_est(self, x_samples, y_samples):
mu, logvar = self.get_mu_logvar(x_samples)
# log of conditional probability of positive sample pairs
# 正样本:两个分布的kl 距离,负数,分布越远数值越小;
positive = - (mu - y_samples) ** 2 / 2. / logvar.exp()
prediction_1 = mu.unsqueeze(1) # shape [nsample,1,dim]
y_samples_1 = y_samples.unsqueeze(0) # shape [1,nsample,dim]
# log of conditional probability of negative sample pairs
# 负样本:y随机取一个数和x分布的kl 距离,随机取的数应该是距离比较远;
negative = - ((y_samples_1 - prediction_1) ** 2).mean(dim=1) / 2. / logvar.exp()
# mi_est相比于单纯的kl 损失优点:x,y 绝对独立的时候,positive-negtive=0,而单纯计算kl 会很大;
return (positive.sum(dim=-1) - negative.sum(dim=-1)).mean()
熵 和 互信息
熵
- 信息论中表示事件的不确定性:事件的发生有几种可能,几种事件的概率越均衡,说明信息的不确定性越高,熵越大;
- 系统复杂性:在给定能量下,系统可能状态的数量越多,熵越大。

互信息 mutual info
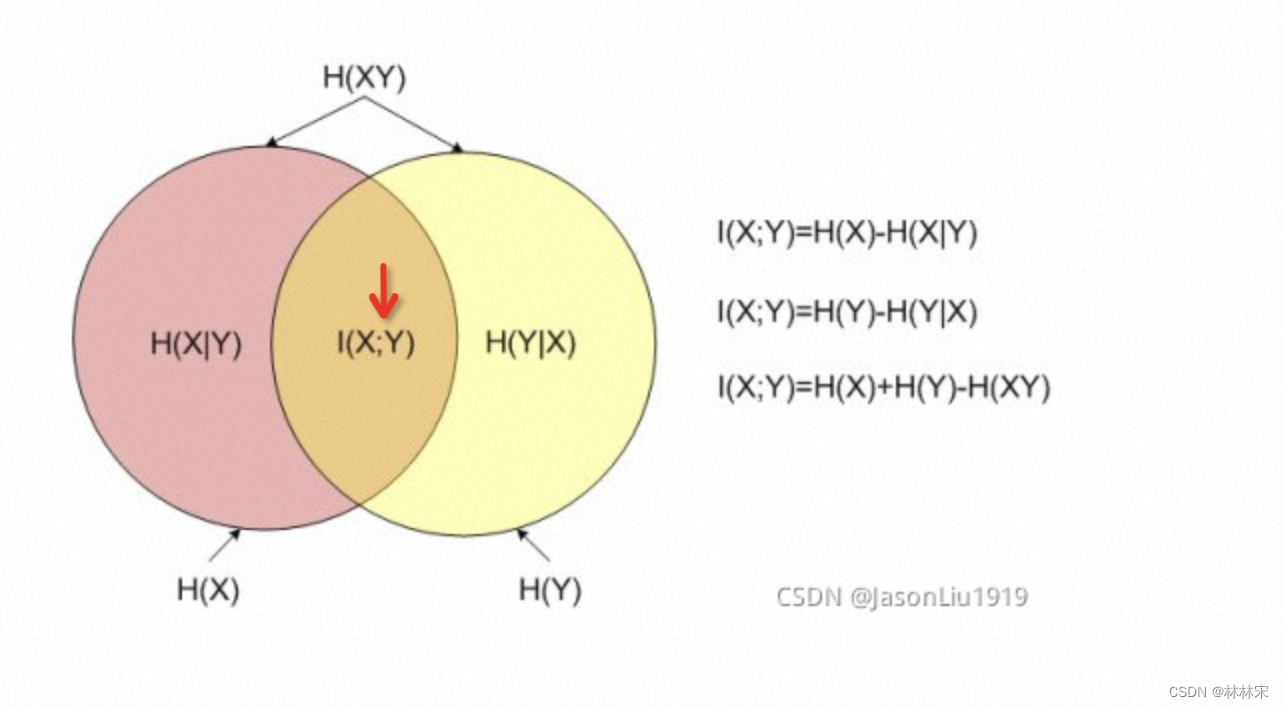
- 互信息越大,两个变量共享的信息量越多,相关性越高;
- 一般优化互信息,是优化互信息的下届,希望预测目标和真实目标的相关度更高;
- 对于特征解耦任务,预测任务变成最小化互信息上界;
- MI 损失估计


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









