







整理的比较清楚的博客
- 人工智能+音乐的探索:从洛天依到小冰初窥歌唱合成
,以学术论文为例说明歌唱合成各家的技术 - 声乐基础理论/音高
- 歌唱合成基础知识非非非常详细的介绍
虚拟歌姬现状
| 形象 | 所属公司 | 技术 |
|---|---|---|
| 洛天依 | 海禾念(雅马哈), bilibili | 人声驱动(山新、鹿乃),参数拼接 |
| 小冰 XiaoIceSing | 微软 | WORLD声码器,论文链接 |
| HIFISINGER | 微软 | 针对质量较差的数据,用到了multi-band的思想,论文链接 |
| DeepSinger | 微软 | 网上爬取的数据用于合成,论文链接 |
| 艾灵 | 腾讯 | 预测mel,DURIAN论文链接,DURIAN-SVC |
| ByteSinger | 字节 | mel预测,论文链接 |
XiaoiceSing–WORLD
会议:2020 interspeech
单位:微软小冰
作者:Peiling Lu
阅读链接
文章链接
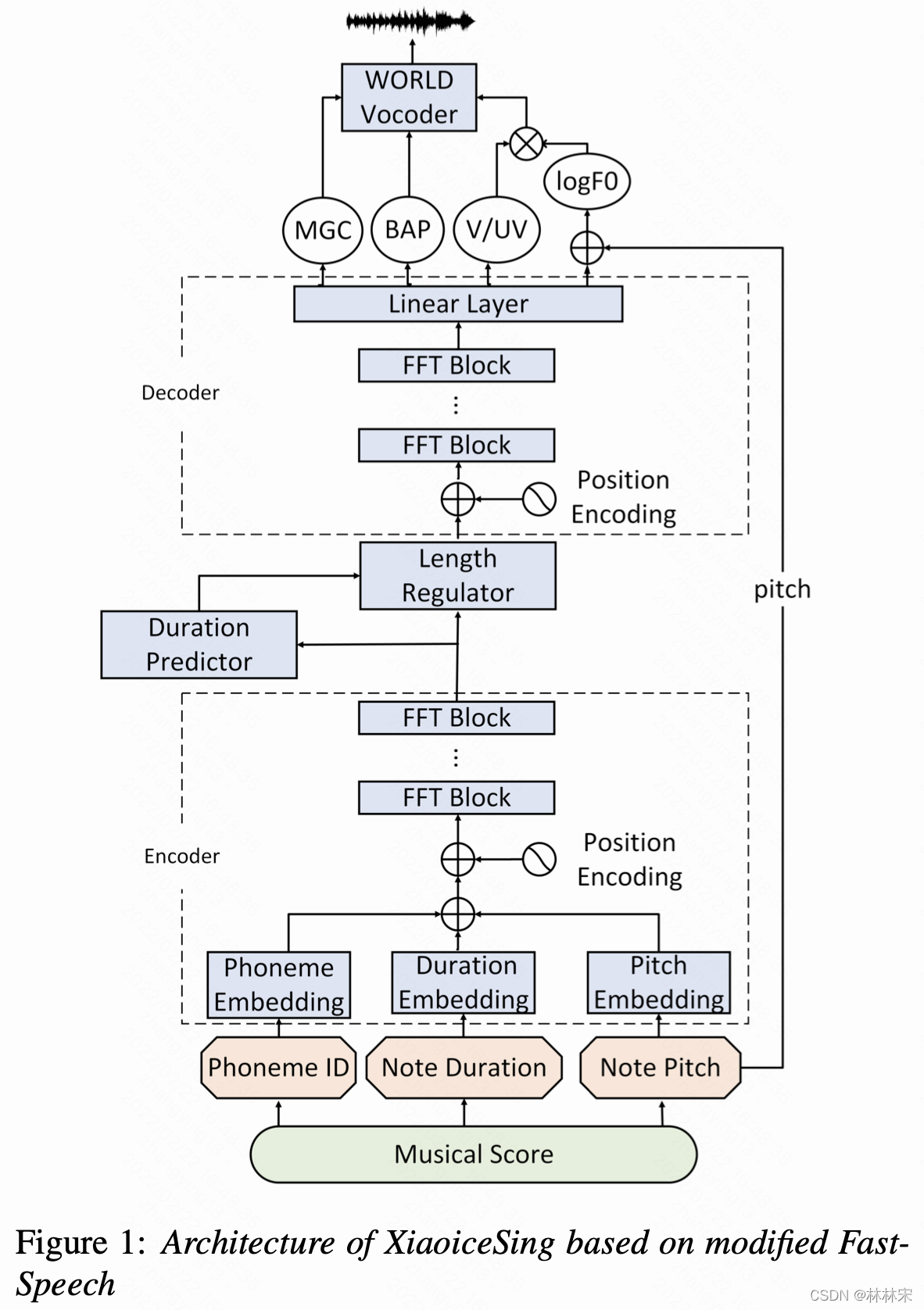
基于WORLD vocoder
- 基频显式可调节,预测pred_picth和note pitch的残差;
- duration 预测phone loss + syllabel loss
- MGC+BAP:预测的时候一起预测,计算loss的时候分开计算;
HiFiSinger
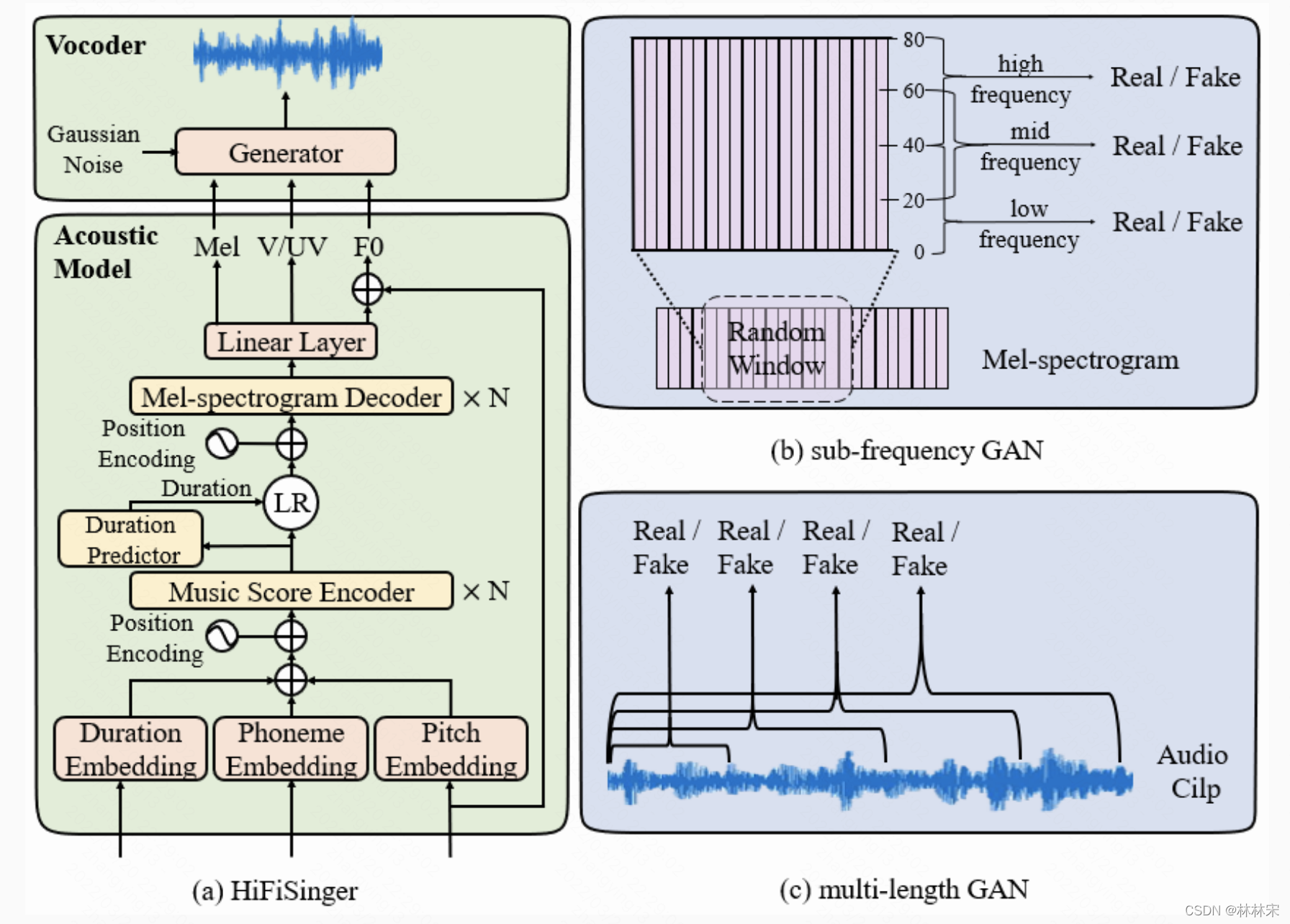
DeepSinger
- 优点:从网上爬虫拿到的数据,使用noise/clean embedding进行比较干净语音的infer生成;
- 大量的篇幅在讲拿到的数据是怎么处理的,force_align,标pitch,etc;
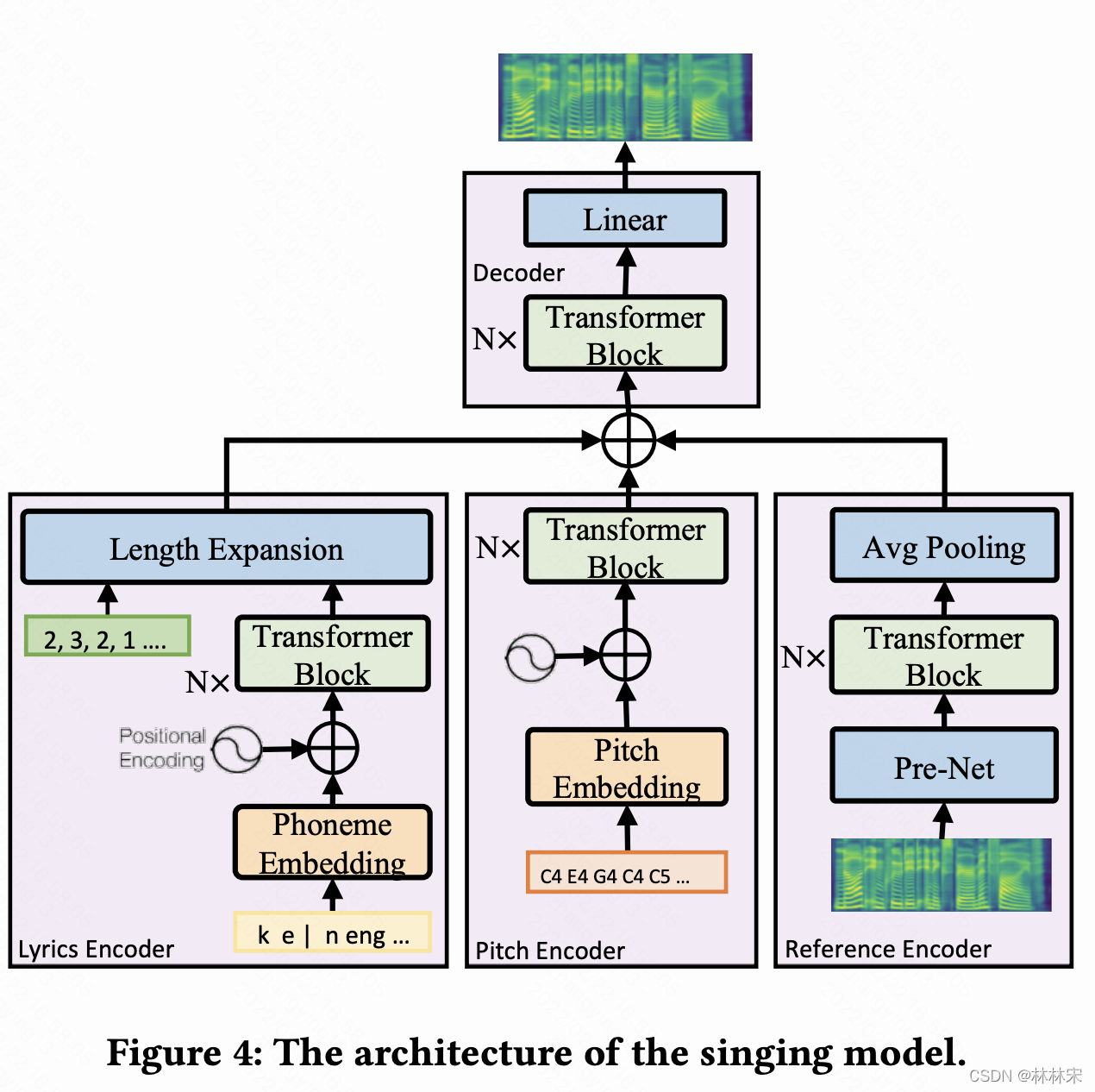
DurIAN

- 生成歌唱语音,也同步生成表情数据
ByteSing
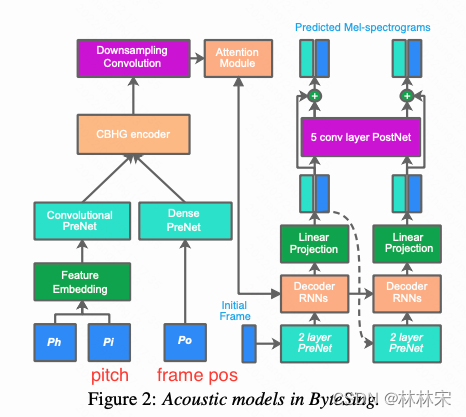
技术路线:
- Tacotron-like的模型结构做encoder-decoder,额外的phoneme prediction module进行时长预测;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









