






- b站
- 2025.2
- 多音字测试数据集
abstract
- character-pinyin 混合编码,解决多音字问题;
- FSQ 代替VQ,提升码本利用率;
- BigVGAN2 作为decoder;
method
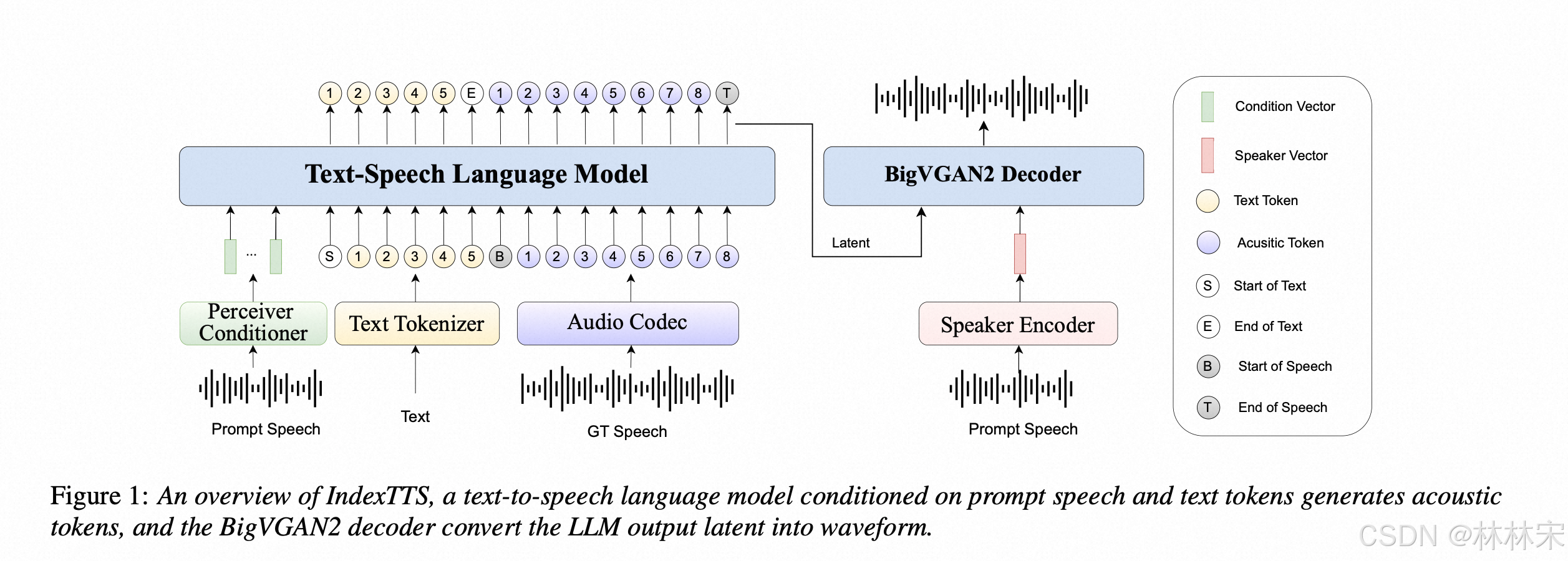
- speech-to-codec VQVAE
- text2codec LLM
- codec2latent, latent2wav BigVGAN2
Text tokenizer
- The vocabulary size of the text tokenizer is 12,000. It encompasses 8,400 Chinese characters along with their corresponding 1,721 pinyin, English word pieces, and several special symbols.
Neural Speech Tokenizer
- 码本数8192 codes,24 kHz, 比特率 25 Hz,输入是mel
- VAE encoder 参数量:50M
LLM
- transformer 替换成Conformer encoder , subsample rate of 2,这个替换可以增强音色相似度和训练稳定性
- 输入序列
- seq1 : [BT], prompt text, text, [ET], [BA], prompt audio, audio, [EA]
- seq2: [BT], text, [ET], [BA], audio, [EA]
- seq3: speaker info, [BT], text, [ET], [BA], au- dio, [EA]
其中,seq1 和seq2 推理阶段是[BT], prompt text, text, [ET], [BA], prompt audio,seq3 推理阶段是“speaker info, [BT], text, [ET], [BA]”,省略了prompt text和prompt audio
- seq3 的优点:简短推理长度;解决asr识别prompt audio不准的问题;跨语言copy,多语言asr 的难度较高;
- Conformer-based Perceiver 提取speaker embedding 的效果更好(是这个意思??)
SpeechDecoder
- 因为速度问题,没有选择diffusion+hifi_vocoder
- 选择BigVGAN2,将speechLLM 的最后一个hidden state +speaker embedding 转换成wav。
- latent的采样率是25hz,差值为100hz,送给BigVGAN2还原24k音频。
Codec Quantizer
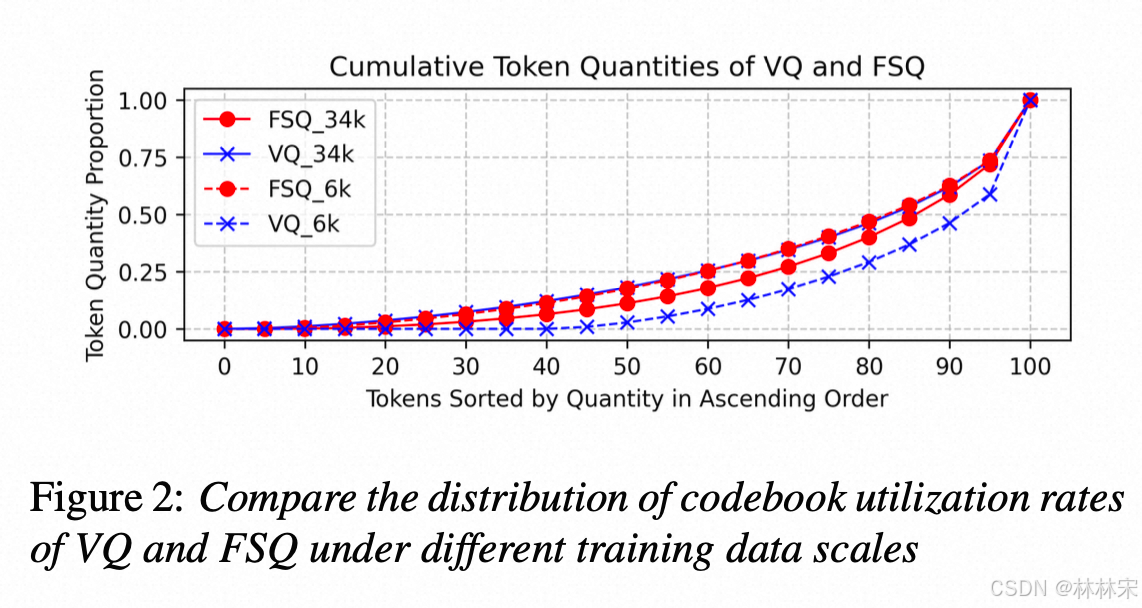
- FSQ的量化效率更高:VQ数据量增至34k 时,和FSQ 6k的量化效率几乎一致
- 数据的多样性会影响量化效率:数据量越多,FSQ 34k的数据量化结果,略差于6k 的结果;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









