







目录
一、perf安装
1.安装perf
# Ubuntu系统
sudo apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`
# Centos系统
yum install -y perf2.查看perf版本
$ perf --version
perf version 5.4.443.perl和FlameGraph安装
利用这个开源工具可以将报告生成可视化的svg图片,更容易查看对应的CPU开销时间和调用栈深度。
git clone --depth 1 https://github.com/brendangregg/FlameGraph.git
# 安装perl
yum install -y perl
# Ubuntu
apt install -y perl二、快速上手指南
1.perf指令详解
让我们从 perf 命令(performance 的缩写)讲起,它是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
通常,它的执行频率是 99Hz(每秒99次),如果99次都返回同一个函数名,那就说明 CPU 这一秒钟都在执行同一个函数,可能存在性能问题。
sudo perf record -F 99 -p 13204 -g -- sleep 30上面的代码中,perf record表示记录,-F 99表示每秒99次,-p 13204是进程号,即对哪个进程进行分析,-g表示记录调用栈,sleep 30则是持续30秒。
运行后会产生一个庞大的文本文件。如果一台服务器有16个 CPU,每秒抽样99次,持续30秒,就得到 47,520 个调用栈,长达几十万甚至上百万行。
2.测试代码
#include <stdio.h>
#include <stdlib.h>
void long_test() {
int i, j;
for (i = 0; i < 1000000; i++) j = i;
}
void long_test2() {
int i, j;
for (i = 0; i < 10000; i++) j = i;
}
void foo2() {
int i;
for (i = 0; i < 1000; i++) long_test2();
}
void foo1() {
int i;
for (i = 0; i < 1000; i++) long_test();
}
int main(void) {
foo1();
foo2();
}3.使用perf对系统CPU事件做采样
采样60s,会生成一个perf.data文件。
# 方式一:对一个正在运行的进程,进行采样
perf record -p PID -g -- sleep 60
# 方式二:全新运行一个二进制文件main,进行采样
sudo perf record -F 99 -g ./test -- sleep 604.打印调用栈
为了便于阅读,perf record命令可以统计每个调用栈出现的百分比,然后从高到低排列。
sudo perf report -n --stdio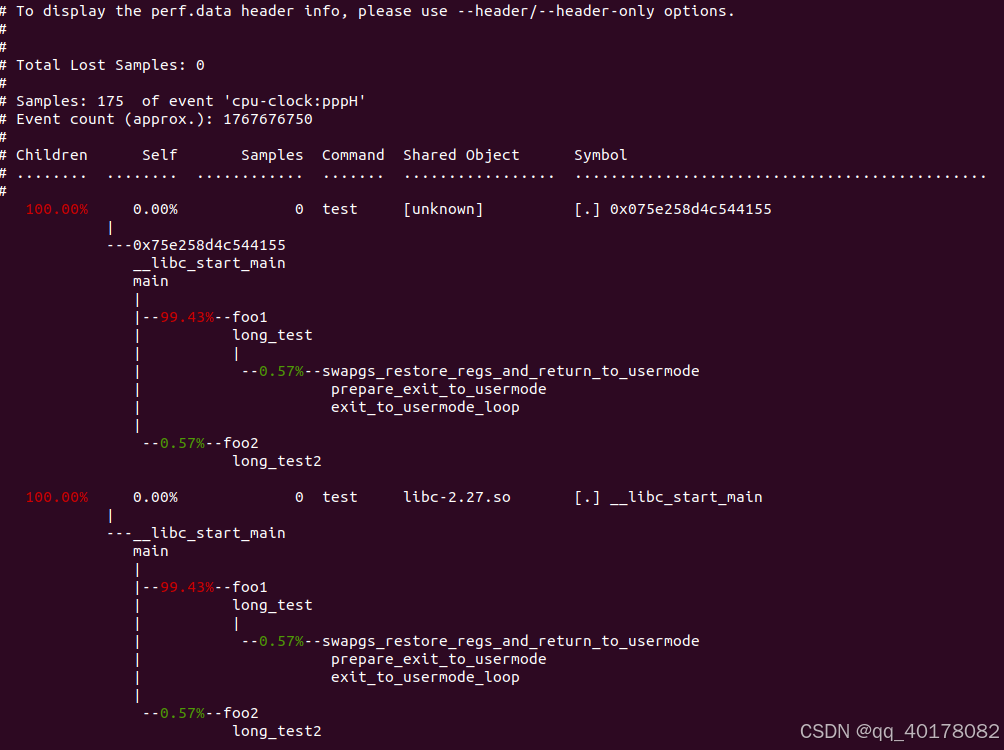
5.生成火焰图
生成火焰图的脚本
对二进制文件main进行10秒的采样,然后生成火焰图
非root用户需要加sudo
perf script -i perf.data &> perf.unfold
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
./FlameGraph/flamegraph.pl perf.folded > perf.svg在浏览器中打开

三.火焰图含义
1.基本概念
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
2.鼠标悬停
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。下面是一个例子。
Function:fool(1757575740 samples, 99.43%)
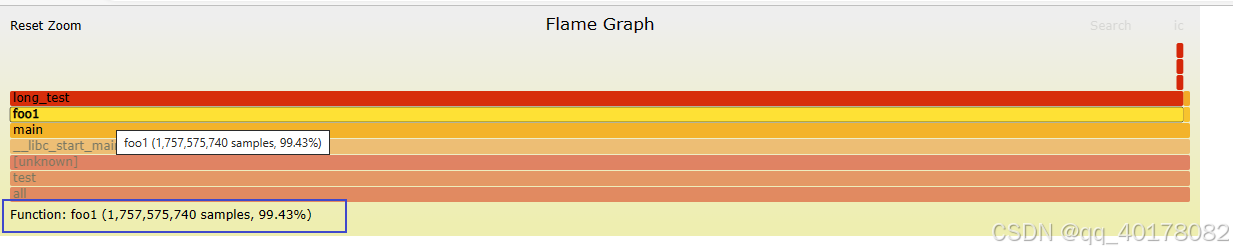
3.点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息。
左上角会同时显示"Reset Zoom",点击该链接,图片就会恢复原样。
四、局限性
两种情况下,无法画出火焰图,需要修正系统行为。
(1)调用栈不完整
当调用栈过深时,某些系统只返回前面的一部分(比如前10层)。
(2)函数名缺失
有些函数没有名字,编译器只用内存地址来表示(比如匿名函数)。

















 2162
2162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









