







点击上方“Linux随笔录”,选择“置顶/星标公众号”
- 前言
- perf与ftrace差别
- perf
- perf 是什么
- perf可以做哪些事情
- perf 安装
- perf 的使用用法
- 生成火焰图
- 总结
前言
前面两篇有讲 ftrace的使用,
我们知道 ftrace 是 Linux 内核的调试追踪工具,主要用于追踪内核函数的调用和事件。它非常适合用于调试内核和跟踪内核态的执行情况。 不过不能够详细分析 CPU 性能、内存使用,采样等,那有没有什么工具可以全面分析CPU性能,内存,答案是有的,Linux内核自带了一个性能分析工具perf,能够进行函数级与指令级的热点查找, 它不但可以分析指定应用程序的性能问题,也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。所以本篇讲讲 perf的使用。
perf与ftrace差别
ftrace适合对于特定耗时函数进行更细的分析,能看调用关系。
perf适合无需源代码通过CPU时钟进行采样就能找到CPU占用高的热点函数,也能看调用关系
perf
perf 是什么
perf是Linux系统提供的一个强大的性能分析工具,它能帮助开发者优化应用程序的性能,可以收集各种性能数据,如CPU使用率、内存访问、函数调用等。
perf可以做哪些事情
- perf 能够追踪硬件事件,如指令执行次数、缓存未命中、分支预测失败等。
- perf 能够追踪系统软件级事件,如上下文切换、页错误、任务调度等
- perf 采用采样法进行性能分析,通过大量的采样数据,可以得出热点函数或代码段,从而找出导致性能瓶颈的部分
- perf 可以实时或事后分析记录的数据。它可以创建统计数据报告,展示CPU使用率、上下文切换、内存访问统计等信息,还可以生成调用图(火焰图)以直观地显示函数调用层级和耗时情况。
perf 安装
用perf前,首先安装Linux下的 perf
sudo apt-get install linux-tools-common
其次要安装具体kernel的安装包
sudo apt-get install linux-tools-5.4.0-107-generic
perf 的使用用法
直接执行perf,查看他的用法
forlinx@ubuntu20:~/test/perf# perf --help
usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS]
The most commonly used perf commands are:
annotate Read perf.data (created by perf record) and display annotated code
archive Create archive with object files with build-ids found in perf.data file
bench General framework for benchmark suites
buildid-cache Manage build-id cache.
buildid-list List the buildids in a perf.data file
data Data file related processing
diff Read perf.data files and display the differential profile
evlist List the event names in a perf.data file
inject Filter to augment the events stream with additional information
kmem Tool to trace/measure kernel memory properties
kvm Tool to trace/measure kvm guest os
list List all symbolic event types
lock Analyze lock events
mem Profile memory accesses
record Run a command and record its profile into perf.data
report Read perf.data (created by perf record) and display the profile
sched Tool to trace/measure scheduler properties (latencies)
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics
test Runs sanity tests.
timechart Tool to visualize total system behavior during a workload
top System profiling tool.
trace strace inspired tool
See 'perf help COMMAND' for more information on a specific command.
perf 是一个包含31种子工具的工具集,我来介绍最常用以下5种:
1、perf-list: 列出perf所有支持的性能监控事件
2、perf-stat: 统计程序运行时的性能事件
3、perf-top: 实时显示CPU占用最高的函数和指令
4、perf-record:收集性能数据并保存到文件
5、perf-report:分析和查看收集的性能数据
perf list
perf list用来列出系统中可以监测的所有性能事件,其中包括硬件性能事件,软件性能事件,tracepoints。
命令格式
perf list [hw | sw | tracepoint]
我们在开发机上敲命令查看下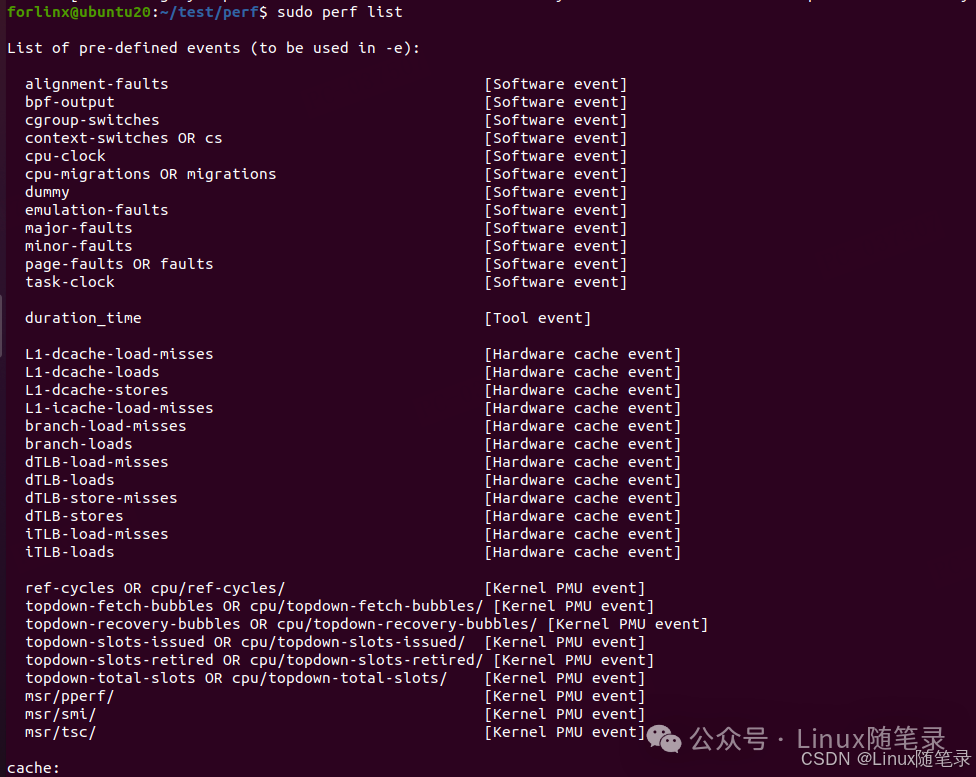
上述这些事件可以包括但不限于:
-
硬件性能事件:由 CPU 硬件提供,通常包括 CPU 时钟周期、指令计数、缓存命中和未命中等,像我的开发机就不支持硬件性能事件采样
例如:
cycles:CPU 时钟周期计数instructions:执行的指令数cache-references:缓存引用计数cache-misses:缓存未命中计数
软件性能事件:由内核软件提供,通常包括上下文切换、进程调度、tick数等。
例如:
context-switches:上下文切换的次数page-faults:页面错误的次数cpu-migrations:CPU 迁移的次数
3、tracepoints :内核中静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等;
这里有点类似ftrace里的/sys/kernel/debug/tracing/available_filter_functions的节点
perf stat
perf stat主要用于在执行指定命令或进程时,收集和显示性能计数器统计信息。此命令分析特定进程在某一时间段内的性能特征
命令格式
perf stat [options] [<command>]
可以在开发机敲入perf stat -h命令来查看
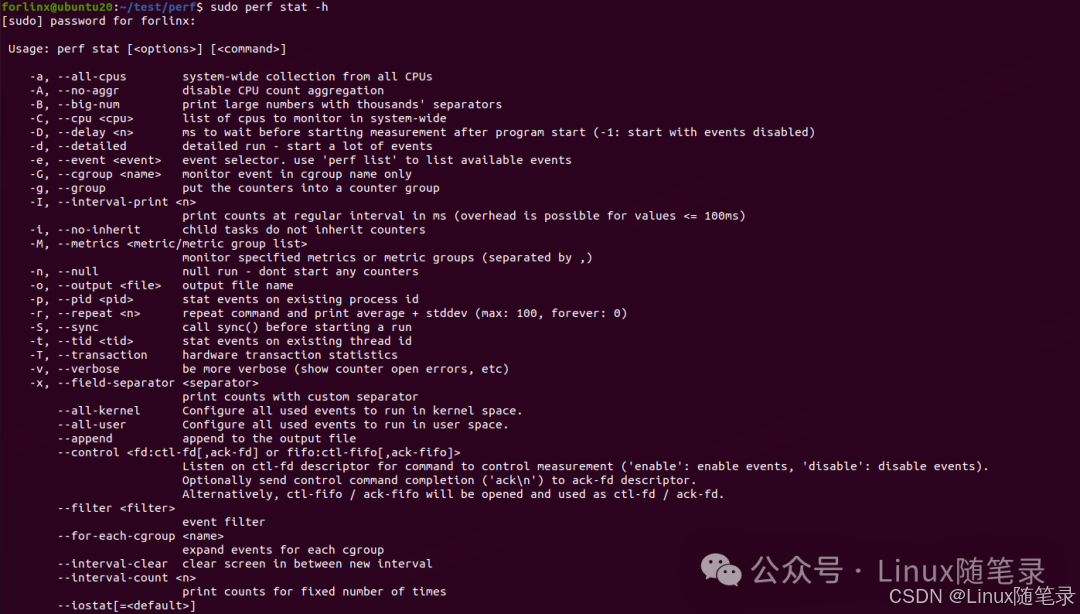
常用选项包括:
- -e
<event>:指定要显示统计的性能事件,类似于perf record中的选项 - -p
<pid>:统计指定进程的性能数据 - a 或 --all-cpus : 显示所有CPU的统计数据
- d 或 --detailed :显示更详细的统计数据
- r 或 --repeat=N : 重复执行命令N次,并统计平均性能数据
- l 或 --interval=N : 以固定间隔重复采样
常用命令解释
perf stat -p $pid -d #进程级别统计
perf stat -a -d sleep 5 #系统整体统计
perf stat -p $pid -e 'syscalls:sys_enter' sleep 10 #分析进程调用系统调用的情形
perf stat -a sleep 5 #收集整个系统的性能计数,持续5秒
perf stat -C 0 #统计CPU 0的信息
通过一个例子来理解下perf stat的使用例子:
#include <stdio.h>
void longa()
{
int i,j;
for (i = 0; i < 1000000; i++)
j=i;
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
int main(void)
{
foo1();
foo2();
}
开发机编译下
gcc -o perf_test -g perf_test.c
下面用perf stat针对程序perf_test的输出统计性能信息
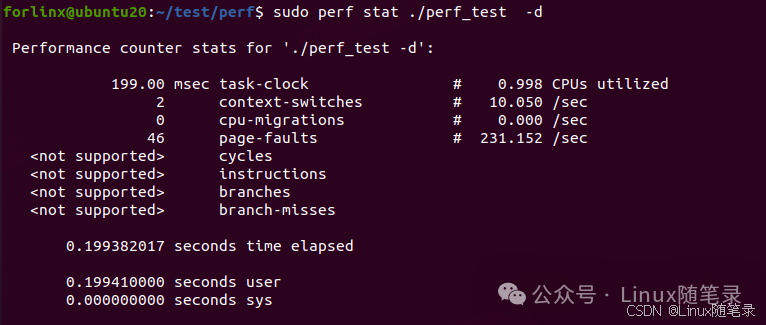
对上面输出信息进行解释:
- Task-clock-msecs:CPU 利用率,该值高说明
perf_test程序的多数时间花费在 CPU 计算上而非 IO,所以本程序是CPU bound型 - Context-switches:进程切换次数,记录了
perf_test程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的。 - CPU-migrations:表示进程
perf_test运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。 - page-faults: 表示进程
perf_test运行过程中发生了多少次页面错误 - instructions:机器指令数目
- Cycles:CPU时钟周期,一条机器指令可能需要多个 cycles
perf top
perf top可以实时显示系统中最消耗 CPU 资源的函数或代码行或某个用户进程。它能够帮助用户识别性能瓶颈并优化代码。
命令格式:
perf top
可以在开发机敲入perf top -h命令来查看
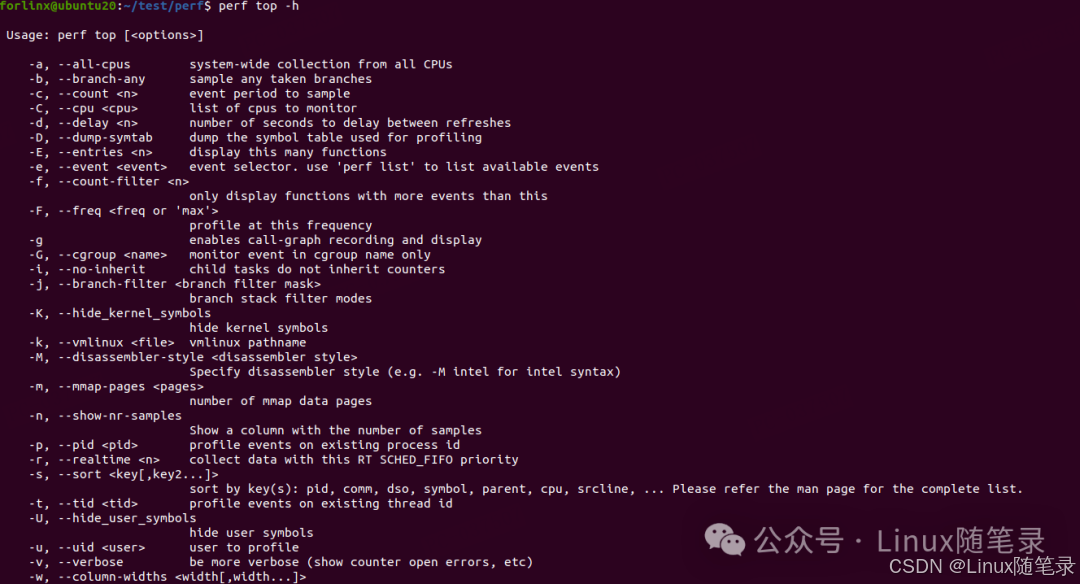
常用选项包括:
- -e:指定要分析的性能事件
- -p:仅分析目标进程
- -k:指定带符号表信息的内核映像路径
- -K:不显示内核或者内核模块的符号
- -U:不显示属于用户态程序的符号
- -g:显示函数调用关系图
通过一个例子来理解下perf top的使用
#include <stdio.h>
int main(void)
{
int i;
while(1) i++;
}
编译下这个程序
gcc -o perf_test -g perf_test.c
运行这个perf_test程序,然后在另外一个窗口运行perf top查看
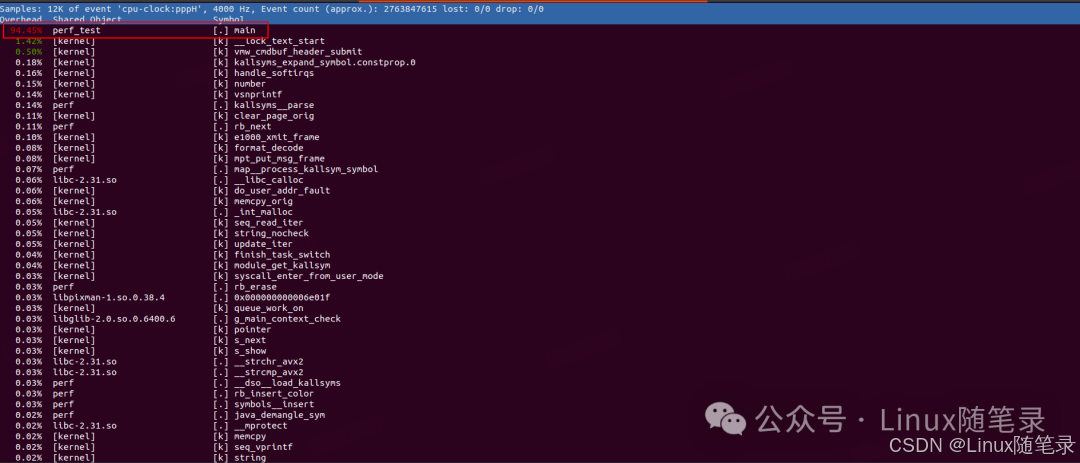 从上述图中可以看到四列数据。
从上述图中可以看到四列数据。
第一列Overhead: 代表该进程/内核/动态库占用的CPU-clock比例以百分比的形式来显示.
第二列Shared Object: 代表动态共享对象,这可能是应用程序本身、Linux内核、动态链接库(.so文件)或内核模块
第三列Symbol:代表动态共享对象的类型标记,方括号中的内容提供了符号所属的代码区域信息,例如,[.]表示该符号属于用户态的ELF(Executable and Linkable Format)文件,这可能是一个动态库或者进程;而[K]则表示该符号源自内核或内核模块代码。
第四列:代表进程名的具体函数,内核里的具体函数,动态库映射的具体符号,如果映射不出来则用地址来显示
这里我们可以看出是 perf_test进程里的main函数占用最高。
或者用perf top -p pid也能看占用最高
perf record
perf record用于收集性能数据。它可以记录特定事件的数据
perf record
常用选项命令解释:
- -e:选择一个事件,可以是硬件事件也可以是软件事件
- -F:设置采样频率,每秒采样多少次
- -p:指定一个进程的ID来采集特定进程的数据
- -o:指定要写入采集数据的数据文件
- -g:使能函数调用图功能,通常使用 DWARF 调试信息:-g --call-graph dwarf
- -C:只采集某个CPU的数据
使用案例:
sudo perf record -F 100 -p 1200 -g -- sleep 60
这条命令的组成部分及其功能解释如下:
- sudo: 以超级用户权限执行命令,
perf需要访问受保护的内核资源。 - perf record:
perf工具的子命令,用于执行性能数据记录。它会在指定条件下收集有关系统或进程的性能数据,并将其保存到一个数据文件中(默认为perf.data)。 - -F 100: 设置采样频率为每秒100次,这意味这每隔大约10毫秒就会一次采样数据
- -p 1200: 指定监控进程的ID(PID)为1200。
perf将会收集这个进程的性能数据 - -g: 启用调用栈收集(call graph)。这意味着在每次采样时,
perf不仅记录当前执行的指令地址,还会记录当时的函数调用栈,这对于分析函数间的调用关系和性能瓶颈非常有用。 - --: 表示命令行选项的结束,之后的参数会被当作非选项参数传递给命令。在这种情况下,后面跟的是
sleep 60命令。 - sleep 60: 休眠60秒, 在此期间,
perf会记录PID为1200的进程的性能数据。
所以,整个命令的目的是休眠60秒内,以每秒100次的频率,对PID为1200的进程进行性能数据采样
perf report
perf report用于查看和分析之前使用 perf record 收集的性能数据
perf report
常用选项解释:
- --stdio: 指定报告输出至标准输出(stdout),而不是默认的交互式TUI模式。这意味着报告将以纯文本的形式直接打印到终端窗口,适合自动化脚本处理或直接查看简单报告,而非通过图形界面浏览详细报告。
通过一个例子来理解下perf record和perf report的使用
#include <stdio.h>
void longa()
{
int i,j;
for (i = 0; i < 1000000; i++)
j=i;
}
void foo2()
{
int i;
for(i=0 ; i < 10; i++)
longa();
}
void foo1()
{
int i;
for(i = 0; i< 100; i++)
longa();
}
int main(void)
{
foo1();
foo2();
}
编译下这个程序
gcc -o perf_test -g perf_test.c
对perf_test程序进行record和report
sudo perf record -g --call-graph dwarf ./perf_test
sudo perf report -n --stdio
用函数调用图看下输出结果
forlinx@ubuntu20:~/test/perf$ sudo perf report --stdio
addr2line: DWARF error: section .debug_info is larger than its filesize! (0x93f189 vs 0x531098)
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
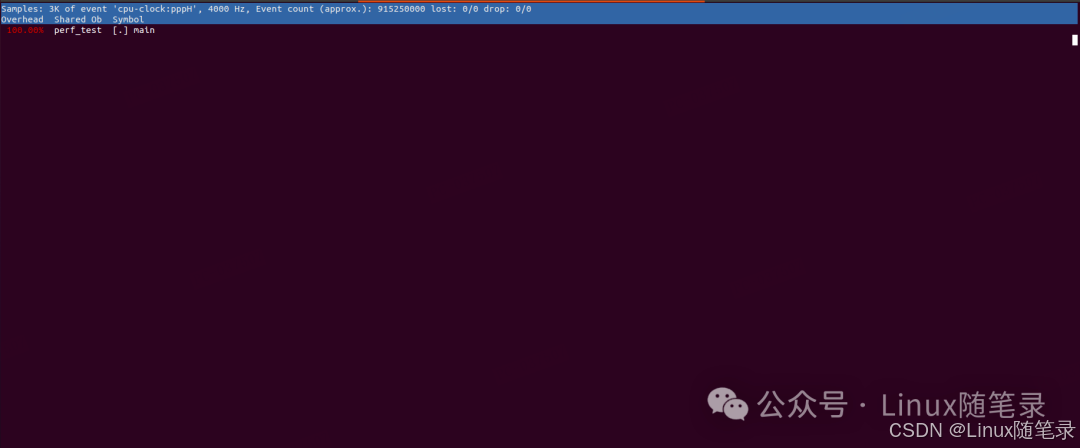
# Samples: 209 of event 'cpu-clock:pppH'
# Event count (approx.): 52250000
#
# Children Self Command Shared Object Symbol
# ........ ........ ......... ............. .....................
#
100.00% 100.00% perf_test perf_test [.] longa
|
---_start
__libc_start_main
main
|
|--91.39%--foo1
| longa
|
--8.61%--foo2
longa
100.00% 0.00% perf_test perf_test [.] _start
|
---_start
__libc_start_main
main
|
|--91.39%--foo1
| longa
|
--8.61%--foo2
longa
100.00% 0.00% perf_test libc-2.31.so [.] __libc_start_main
|
---__libc_start_main
main
|
|--91.39%--foo1
| longa
|
--8.61%--foo2
longa
100.00% 0.00% perf_test perf_test [.] main
|
---main
|
|--91.39%--foo1
| longa
|
--8.61%--foo2
longa
91.39% 0.00% perf_test perf_test [.] foo1
|
---foo1
longa
8.61% 0.00% perf_test perf_test [.] foo2
|
---foo2
longa
#
# (Cannot load tips.txt file, please install perf!)
#
可以看到各级函数的占用的开销
Children :是这个符号调用的其他符号(可以理解为子函数,包括直接和间接调用)占总采样数比例之和。
Self:是最后一列的符号(可以理解为函数)本身采样数占总采样数的百分比
[.]:代表该调用属于用户态,若自己监控的进程为用户态进程,那么这些即主要为用户态的cpu-clock占用的数值,[k]代表属于内核态的调用。
调用关系是
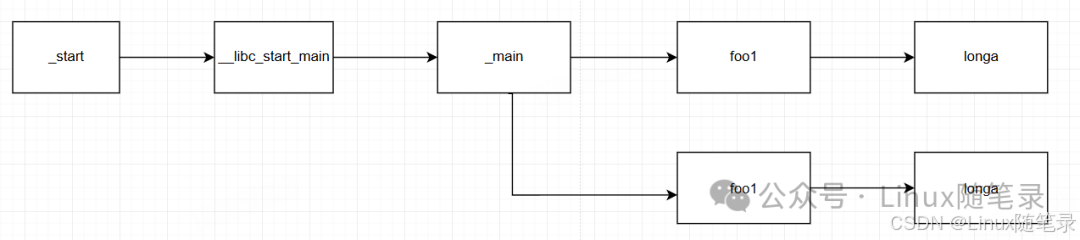
我们可以看到longa符号占用了perf_test程序的100%的CPU资源。
生成火焰图
on-cpu火焰图可以用于分析cpu是被哪些线程、哪些函数占用的,可以方便的找到热点代码便于后续分析优化。
还是用上面的例子,下面我们介绍下火焰图的生成和使用方法。
使用方法:
- 下载
FlameGraph工具
git clone https://github.com/brendangregg/FlameGraph.git
- 用
perf record采集CPU信息。
sudo perf record -e cpu-clock -g ./perf_test
- 用
perf script工具对perf.data读取并显示详细的采样数据
sudo perf script > out.perf
- 将
perf.unfold中的符号进行折叠
./FlameGraph/stackcollapse-perf.pl out.perf > out.folded
- 最后生成
svg图
./FlameGraph/flamegraph.pl out.folded > out.svg
最后out.svg 文件用浏览器就可以打开
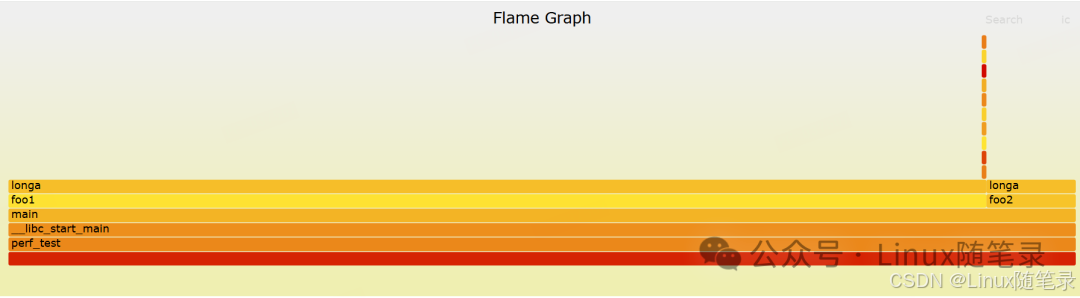
- y轴表示调用栈,每一层都是一个函数,调用栈越深,火焰就越高
- x轴表示抽样数,如果一个函数在x轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"平顶"(plateaus),就表示该函数可能存在性能问题。比如图中的longa()函数正是问题所在点。想看火焰图的文件,可以公众号后台回复“perf火焰图”即可拿到
总结
本文学习到了如何用perf进行耗时分析生成火焰图,如果有疑问的话可以在评论区留言,对本篇文章学废的同学,可以一键三连!欢迎关注公众号[Linux随笔录],不定期分享Linux小知识
往期推荐

















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









