







tf.newaxis在深度学习,尤其是输入数据的维度与神经网络要求的输入维度不匹配时,有很大的用处,下面代码展示一下tf.newaxis的具体作用:
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
new_1 = x_train[tf.newaxis,...]
new_2 = x_train[...,tf.newaxis]
# 打印出训练集输入特征的第一个元素形状
print("x_train[0]:\n", x_train[0].shape)
# 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)
# 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 打印出newaxis后的形状
print("new_1 shape:\n", new_1.shape)
print("new_2 shape:\n", new_2.shape)
#打印出newaxish后单张图片的形状
print('new_1[0]:\n',new_1[0].shape)
print('new_2[0]:\n',new_2[0].shape)
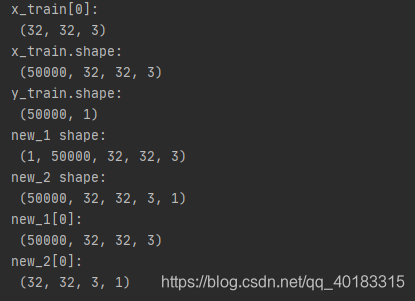
结果如上,可见tf.newaxis的主要用途是增加一个维度,位置不同,增加的维度是第几维也相对不一样,可以解决用训练好的神经网络模型进行预测时的维度不匹配问题。以tf自带的数据集cifar10为例。搭建一个神经网络。
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5),
activation='sigmoid')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.f1 = Dense(120, activation='sigmoid')
self.f2 = Dense(84, activation='sigmoid')
self.f3 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.p1(x)
x = self.c2(x)
x = self.p2(x)
x = self.flatten(x)
x = self.f1(x)
x = self.f2(x)
y = self.f3(x)
return y
model = LeNet5()经过compile,fit和summary之后,调用model.predict(x_test[0])则会出现以下错误

图片自身是(32,32,3)的维度,但是喂入神经网络的数据是按照batch_size喂入的,因此相当于我们的输入数据应当是4维。因此我们合理调用tf.newaxis解决问题
x_pre = x_test[15]
x_predict = x_pre[tf.newaxis,...]
result = model.predict(x_predict)
pred = tf.argmax(result, axis=1)
tf.print('tf print', pred)如此一来,等待预测的输入维度变成(1,32,32,3)满足要求,成功预测。

预测是第8类别,具体是什么就不去关注了。以此记录,方便往后查看。

















 2561
2561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









