







2.3.1知识概述
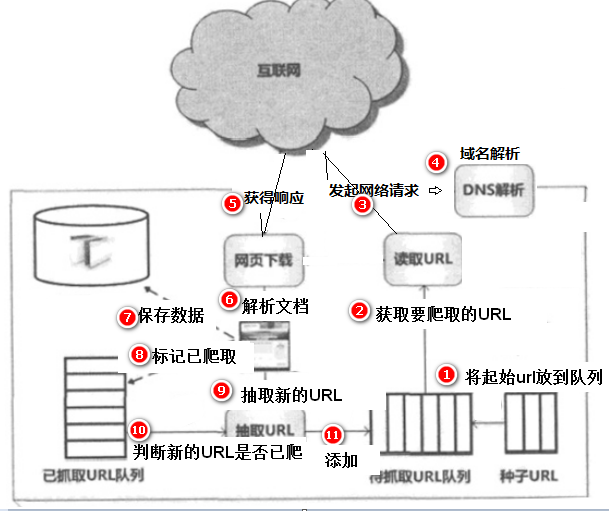
① 指定一个种子url放入到队列中
② 从队列中获取某个URL
③ 使用HTTP协议发起网络请求
④ 在发起网络请求的过程中,需要将域名转化成IP地址,也就是域名解析
⑤ 得到服务器的响应,此时是二进制的输入流
⑥ 将二进制的输入流转换成HTML文档,并解析内容(我们要抓取的内容,比如标题)。
⑦ 将解除出来的内容保持到数据库
⑧ 记录当前URL,并标记为已爬取,避免下次重复爬取。
⑨ 从当前的HTML文档中,解析出页面中包含的其它URL,以供下次爬取
2.3.1知识概述
① 指定一个种子url放入到队列中
② 从队列中获取某个URL
③ 使用HTTP协议发起网络请求
④ 在发起网络请求的过程中,需要将域名转化成IP地址,也就是域名解析
⑤ 得到服务器的响应,此时是二进制的输入流
⑥ 将二进制的输入流转换成HTML文档,并解析内容(我们要抓取的内容,比如标题)。
⑦ 将解除出来的内容保持到数据库
⑧ 记录当前URL,并标记为已爬取,避免下次重复爬取。
⑨ 从当前的HTML文档中,解析出页面中包含的其它URL,以供下次爬取
 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















