







机器学习之特征选择
1. 特征选择原理
特征选择:是在原始数据中选取有效特征以降低数据维度,提高模型性能。
模型效果与特征维数关系如下图所示,不是说特征数量越多模型效果越好。

特征选择优势:
- 提高精度
- 降低过拟合风险
- 加快训练速度
- 改进数据可视化
- 增加模型可解释性
特征选择类似于降维技术,其目的是减少特征的数量,但是从根本上说,它们是不同的。区别在于特征选择会从数据中选择要保留的特征,而降维会采用映射函数,将数据特征投影到新的维度上,从而产生全新的输入特征,如PCA。
2. 特征选择分类
2.1 过滤法
对特征进行预处理,去除与模型无关的特征。如我们可以计算出每个变量与响应变量之间的相关性或者互信息,然后过滤掉那些在某个阈值之下的特征。此方法没有考虑我们所使用的模型,因此无法为模型选择出正确的特征。此方法慎用,以免在有用特征进入到模型训练阶段之前被过滤掉或删除了。
2.2 打包法
此法使用机器学习模型作为其评估标准(例如,向前/向后/双向/递归特征消除)。我们一些特征输入机器学习模型,评估它们的性能,然后决定是否添加或删除特征以提高精度,即将模型视为一个能推荐特征子集给出合理评分的黑盒子。因此,这种方法可以比滤波更精确,但计算成本更高,不会意外的删除那些本身不提供什么信息但和其他特征组合起来却非常有用的特征。
2.3 嵌入法
此法将特征选择作为模型训练的一部分,例如特征选择是决策树与生俱来的一种功能,因为它在训练阶段都要选择一个特征对树进行分割。另一个例子是L1正则项,它添加到任意线性模型中,L1正则项建议使用较少的特征,又称为模型的稀疏性约束。此方法根据每个特征对 ML 模型训练的贡献程度对每个特征的重要性进行排序。他不如打包法强大,但成本低,与过滤法相比,此法可以选择出适合某种模型的特征。嵌入法在计算成本和结果质量之间实现了平衡。
3. 特征选择常见的实现方式
3.1 方差阈值特征选择(过滤法)
原理:具有较高方差的特征表示该特征内的值变化大,较低的方差意味着特征内的值较相似,而零方差意味着特征取值都一样。
方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
适用范围:离散型特征和连续型特征都可,和标签类型无关。
实现方式:sklearn中的VarianceThreshold类
– Variance Threshold中重要参数 threshold(方差的阈值),表示删除所有方差小于threshold的特征,不填默认为0——删除所有记录相同的特征。
import pandas as pd
import numpy as np
np.random.seed(7) # 设置随机种子,实现每次生成的随机数矩阵都一样
a = np.random.randint(0, 100, 10)
b = np.random.randint(0, 100, 10)
c = np.random.randint(0, 100, 10)
d = [10, 10, 10, 10, 10, 10, 10, 10, 10, 10]
data = pd.DataFrame({"A": a, "B": b, "C": c, "D": d})
print('row_data\n',data.head())
from sklearn.feature_selection import VarianceThreshold
sel = VarianceThreshold()
sel.fit_transform(data) # 获取删除不合格特征之后的新特征矩阵
print('after feature selection\n', pd.DataFrame(sel.fit_transform(data), columns=['A','B','C']).head()) #获取删除不合格特征之后的新特征矩阵

D列被删除了。
3.2 相关性过滤法(过滤法)
方法一:卡方检验
原理:计算每个非负特征与标签之间的卡方值,每一个卡方值对应一个p值,用p值判断特征和标签之间的相关性。大众经验,p值选择0.05或0.1。如P<=0.05就说明两组数据相关。
适用范围:离散型标签(即适用分类问题),只能捕捉线性相关。
实现方式:sklearn中的 chi2类和类SelectKBest连用
– SelectKBest使用方法见:https://www.jianshu.com/p/488a4f39493b
import pandas as pd
import numpy as np
np.random.seed(7)
a= np.random.randint(0, 100,10)
b= np.random.randint(0, 100,10)
c= np.random.randint(0, 100,10)
d= [10,10,10,10,10,10,10,10,10,10]
x=pd.DataFrame({"A" : a,"B" : b,"C" : c,"D" : d})
y=[0,0,1,0,1,1,0,1,0,1]
from sklearn.feature_selection import chi2
# 卡方值,p值
chivalue,pvalue=chi2(x,y)
# 确定要保留几个特征
k=chivalue.shape[0]-((pvalue>0.05).sum())
# 结合SelectKBest筛选出来过滤特征后的数据集
from sklearn.feature_selection import SelectKBest
x_new=SelectKBest(chi2,k=k).fit_transform(x,y)
x_new
SelectKBest函数使用方法
参数:SelectKBest(score_func= f_classif, k=10)
score_func:特征选择要使用的方法,默认适合分类问题的F检验分类:f_classif。
k :取得分最高的前k个特征,默认10个。
属性:fit(x,y)方法后才能调用
scores_ :返回每个特征的得分
pvalues_ : 返回每个特征得分对应的p_value值。如果score_func只返回分数,则pvalues_返回空。
常用方法
fit(x,y):传入特征集x和标签y 拟合数据。
transform(x):fit(x,y)后使用,转换数据,返回特征过滤后保留下的特征数据集。
get_support(indices=True):fit(x,y)后使用,返回特征过滤后保留下的特征列索引。
fit_transform(x,y):拟合数据+转化数据,返回特征过滤后保留下的特征数据集。
说明:以上是常用的方法,还有其他方法,详见sklearn官网。sklearn.SelectKBest官网
#鸢尾花数据集
from sklearn.datasets import load_iris
iris = load_iris()
x, y = iris.data, iris.target
# 导入 SelectKBest,和要使用的卡方过滤法chi2类
from sklearn.feature_selection import SelectKBest,chi2
# 实例化selectKBest对象
skb=SelectKBest(chi2,k=2)
# 调用fit方法
skb=skb.fit(x,y)
#调用属性scores_,获得chi2返回的得分
skb.scores_
# 调用属性pvalues_ ,获得chi2返回的P值
skb.pvalues_
#返回特征过滤后保留下的特征列索引
skb.get_support(indices=True)
# 转换数据,得到特征过滤后保留下的特征数据集
x_new=skb.transform(x)
x_new
#拟合数据加转化数据一步到位:
x_new=skb.fit_transform(x,y)
x_new
方法二:互信息
互信息法
原则:互信息法返回每个特征与标签之间的互信息量的估计,值越大越相关:0表现特征和标签完全独立。
适用范围:
– 可以捕捉任意关系(线性关系和非线性关系)
– sklearn官方有提到:(互信息)能够计算任何种类的统计相关性,但是作为非参数的方法,互信息需要更多的样本来进行准确的估计。(线下测试结果:如果样本量很小,每次运行的结果波动很大)
– 既可以做回归(连续型标签,互信息回归feature_selection.mutual_info_regression)又可以做分类(离散型标签,互信息分类feature_selection.mutual_info_classif)
from sklearn.feature_selection import SelectKBest, mutual_info_regression
#Select top 2 features based on mutual info regression
selector = SelectKBest(mutual_info_regression, k =2)
selector.fit(X, y)
X.columns[selector.get_support()]
#鸢尾花数据集测试
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import mutual_info_classif
iris = load_iris()
x, y = iris.data, iris.target
# result=mutual_info_classif(x,y,random_state=666)
#mutual_info_classif是有一定的随机性的
result=mutual_info_classif(x,y)
#返回每个特征与标签的互信息估计量
result
#假设需要筛选出来互 信息量估计量 最大的前2个特征
x_new = SelectKBest(mutual_info_classif, k=2).fit_transform(x, y)
方法三:F检验
原则:和卡方的原理相似,计算特征和标签的F值,根据F值对应的p值(p<0.05)确定SelectKBest中的k值。
适用范围:
– 对正态分布的效果好(建议先对数据进行标准化处理)。
– 只能捕捉线性关系。
– 既可以做回归(连续型标签,F检验回归feature_selection.f_regression),又可以做分类(离散型标签,F检验分类feature_selection.f_classif)。
3.3 递归特征消除法(打包法)
- RFE
原理:是打包法的一种,递归删除法不断训练模型,每次训练完成后删除特征重要性低的N个特征,然后对新的特征再次进行训练,又一次得到特征重要性,再次删除N个重要性低的特征,直到满足预先设定的特征数量为止。
此函数在调用时,需要基模型有“coef_ ”属性 或者 “feature_importances_ ”
参数:
estimator : 基模型
n_features_to_select : int or None (default=None),指定最终要保留的特征数量,None时表示选取一半的特征
step为整数时设置每次要删除的特征数量,当小于1时,每次去除权重最小的百分之几的特征。
输出特性:
n_features_ : 最后选取的特征数量
support_ : 输出与特征数一致的列表,选取的特征显示为True,未选取的特征显示为False
ranking_ : 对特征重要性的排序
estimator_ : 输出降维后的数据模型
import warnings
warnings.filterwarnings('ignore') #忽略warning的输出
import pandas as pd
from sklearn import datasets
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
all = datasets.load_iris()
rfe=RFE(estimator=LogisticRegression(),step=1)
rfemodel=rfe.fit(all.data,all.target)
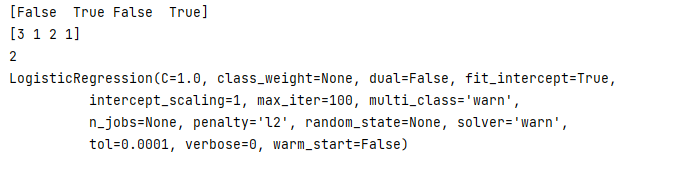
print(rfe.support_)
print(rfe.ranking_)
print(rfe.n_features_)
print(rfe.estimator_)
- RFECV
通过交叉验证来找到最优的特征数量,这里的交叉验证与我们经常见到的不同,不是不同行组合然后求平均,而是不同列的组合求均值,得到最优的特征数量。如果减少特征会造成性能损失,那么将不会去除任何特征。
这个方法用以选取单模型特征相当不错,但是有两个缺陷,一,计算量大,运行一次需要很久时间。二,随着学习器(评估器)的改变,最佳特征组合也会改变,有些时候会造成不利影响。因此适合在模型确定后进行特征再次选择。三、更改最小特征数,运行结果会发生变化(都没有达到最小特征数的情况下)。
首先计算没有删除任何特征的score;接着每次计算删除“step“个特征的情况,会计算所有组合情况,得到平均的score;以此类推,一直重复,直到到达最小删除特征数。然后会给出每个特征的评分,以及选出最优特征子集。
参数说明:
step整数时,每次去除的特征个数,小于1时,每次去除权重最小的百分之几的特征;
scoring字符串类型,选择sklearn中的scorer作为输入对象;cv默认为3;
min_features_to_select:设定最少的特征数,默认是1。
输出:
grid_scores_:每个值代表了此次迭代所有特征组合得到的score的平均值。
ranking_:每个特征的得分。
support_:此特征是否入选最后特征。
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_selection import RFECV
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=25, n_classes=2, random_state=0) #生成样本数据
# Create the RFE object and compute a cross-validated score.
svc = SVC(kernel="linear")
rfecv = RFECV(estimator=svc, step=1, cv=StratifiedKFold(2),
scoring='roc_auc')
rfecv.fit(X, y)
print("Optimal number of features : %d" % rfecv.n_features_)
print(rfecv.ranking_)
print(rfecv.support_)
print(rfecv.grid_scores_)
print(rfecv.estimator_)

3.4 SelectFromModel 特征选择(打包法)
Scikit-Learn 的 SelectFromModel 用于选择特征的机器学习模型估计,它基于重要性属性阈值。默认情况下,阈值是平均值。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
from sklearn.feature_selection import RFE
import pandas as pd
import warnings
warnings.filterwarnings('ignore') #忽略warning的输出
all = datasets.load_iris()
X = pd.DataFrame(all.data)
y = pd.DataFrame(all.target)
sfm_selector = SelectFromModel(estimator=LogisticRegression())
sfm_selector.fit(X, y)
print(X.columns[sfm_selector.get_support()])
print(sfm_selector.estimator_)
print(sfm_selector.threshold_)

3.5 顺序特征选择(SFS)(打包法)
顺序特征选择是一种贪婪算法,用于根据交叉验证得分和估计量来向前或向后查找最佳特征,它是 Scikit-Learn 版本0.24中的新增功能。方法如下:
SFS-Forward 通过从零个特征开始进行功能选择,并找到了一个针对单个特征训练机器学习模型时可以最大化交叉验证得分的特征。
一旦选择了第一个功能,便会通过向所选功能添加新功能来重复该过程。当我们发现达到所需数量的功能时,该过程将停止。
from sklearn.feature_selection import SequentialFeatureSelector
sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select = 3, cv =10, direction ='backward')
sfs_selector.fit(X, y)
X.columns[sfs_selector.get_support()]















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









