







 GFS通过命名空间锁确保原子性,不支持硬链接和符号链接,使用读写锁避免并发操作冲突。Chunk位置信息由Master在启动时获取,不持久化。Chunk内容一致性通过三副本和RecordAppend操作保证,RecordAppend避免了并发写入导致的数据不确定状态。过期副本通过版本号检测并由Master进行回收。
GFS通过命名空间锁确保原子性,不支持硬链接和符号链接,使用读写锁避免并发操作冲突。Chunk位置信息由Master在启动时获取,不持久化。Chunk内容一致性通过三副本和RecordAppend操作保证,RecordAppend避免了并发写入导致的数据不确定状态。过期副本通过版本号检测并由Master进行回收。
目录
一、命名空间修改的原子性——命名空间锁保障原子性和正确性
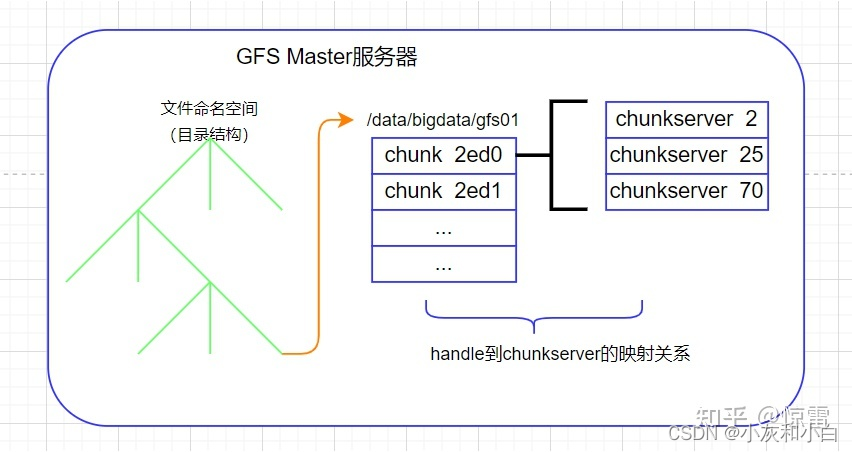
文件命名空间:
不同于许多传统文件系统,GFS没有针对每个目录实现能够列出目录下所有文件的数据结构。GFS也不支持文件或者目录的链接(即Unix术语中的硬链接或者符号链接)。在逻辑上,GFS的命名空间就是一个全路径和元数据映射关系的查找表。利用前缀压缩,这个表可以高效的存储在内存中。在存储命名空间的树型结构上,每个节点(绝对路径的文件名或绝对路径的目录名)都有一个关联的读写锁。
如上图所示,文件命名空间叶子节点是一个文件的全路径,指向了该文件的元信息。
例子:我们演示一下在/home/user被快照到/save/user的时候,锁机制如何防止创建文件/home/user/foo。快照操作获取/home和/save的读取锁,以及/home/user和/save/user的写入锁。文件创建操作获得/home和/home/user的读取锁,以及/home/user/foo的写入锁。这两个操作要顺序执行,因为它们试图获取的/home/user的锁是相互冲突。文件创建操作不需要获取父目录的写入锁,因为这里没有”目录”,或者类似inode等用来禁止修改的数据结构。文件名的读取锁足以防止父目录被删除。

采用这种锁方案的优点是支持对同一目录的并行操作。比如,可以再同一个目录下同时创建多个文件:每一个操作都获取一个目录名的上的读取锁和文件名上的写入锁。目录名的读取锁足以的防止目录被删除、改名以及被快照。文件名的写入锁序列化文件创建操作,确保不会多次创建同名的文件。
因为名称空间可能有很多节点,读写锁采用惰性分配策略,在不再使用的时候立刻被删除。同样,锁的获取也要依据一个全局一致的顺序来避免死锁:首先按名称空间的层次排序,在同一个层次内按字典顺序排序。
二、Chunk位置信息的改变
上图右侧即Chunk位置信息,Master不持久化保存,只是在启动时轮询Chunk服务器获取位置信息——Chunk服务器来维护这些信息。
三、Chunk内容的一致性
GFS一般是三副本,所以当同一份数据要写入不同的ChunkServer服务器时,会遇到部分写入失败的问题,这就是数据写入一致性的问题。

Table1中的第一行Write和Record Append指的是两种数据修改方式,第一列Serial success 、Concurrent successes、Failure指的是三种写入的结果。对应两种数据修改方式和三种结果,产生了四种不同的状态。
(1)数据修改方式
Write:是传统的写入方式,客户程序会指定数据写入的偏移量。对同一个region的写入操作不是串行的:region尾部可能会包含多个不同客户端写入的数据片段。
Record Append:是将客户端要写入的数据追加到由GFS指定的位置,追加完成后GFS返回这个偏移量给客户端。GFS保证至少有一次原子的写入操作成功执行(即写入一个顺序的byte流),即At Least Once”。
(2)写入结果和状态
consistent:一致的,多个副本Replica读出来的数据都是一样的。
defined:确定的,就是客户端写入的数据能够完整地被读到。即:每个客户端写入指定offset的数据 和 再从offset读出来的数据是相同的。(不会被其他客户端写入的内容覆盖)
(consistent指的是多副本之间的数据是否一致,defined指的是客户端到服务器写入的数据和读出的数据是否一样)
inconsistent:不一致的,如果数据写入是失败的(部分副本成功,部分副本失败也是写入失败),那么GFS中的数据必然是不一致的inconsistent。
Serial success-Write-defined:(如果是顺序写入,写入成功,那么文件中的数据就是确定的defined,客户端读到的数据也是确定的defined。)串行写入成功,不会有不同客户端写入的内容交叉,即undefined的状态出现。

Concurrent successes-Write-consistent but undefined:并发写入,由于多个客户端并发地向同一个文件中写入数据,三副本都写入成功了,如果多个客户端写入的数据有可能出现交叉。
例子:
客户端A写入数据范围[50, 80],客户端B写入数据范围[70, 100],就会出现下面的情况:客户端A写入成功后,客户端B有可能会覆盖了客户端A的数据;也可能是客户端B写入成功后,客户端A可能覆盖了客户端B的数据。但是客户端A和客户端B都写成功了,其3个副本都是按同样的顺序写的数据,客户端无论从哪个副本读,数据都是一致的consistent,但是客户端去读自己写入的数据,就会出现读出来的数据有部分交叉的内容,这部分内容是客户端A写入的,还是客户端B写入的是不确定的undefined。
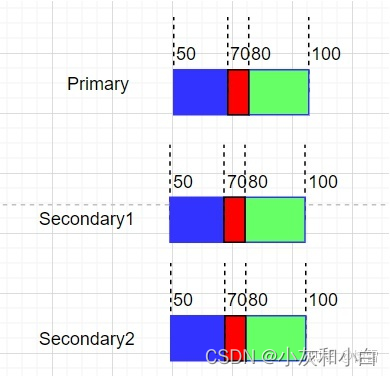
为什么并发写入成功时会出现consistent but undefined的状态呢?
一是,数据的写入顺序并不需要通过Master来协调,而是直接发送给ChunkServer,由ChunkServer来管理数据的写入顺序;二是,随机写操作大概率会横跨多个Chunk。这就导致一个Chunk可能既包含数据A,又包含数据B。随机数据的写入并非原子性的,也没有事务性保证,因此需要客户端在写入数据时是顺序写入的,避免并发写入的出现。那么问题也来了,GFS允许几百个客户端读写访问,那该怎么避免这种一致但非确定的状态呢?GFS设计了记录追加Record Append来解决这个问题。
为什么Record Append可以避免consistent but undefined的状态?
GFS的Record Append操作:写操作时,GFS并不指定在Chunk的哪个位置offset写入数据,而是告诉Chunk的主副本Primary Replica服务器“我要追加记录”,由主副本ChunkServer根据当前Chunk位置决定写入的offset,在写入成功后将该offset返回给客户端,客户端根据offset确切知道写入结果,无论是串行写入,还是并发写入,其结果都是确定的defined。(从根本上避免了不同客户端写入内容的覆盖)
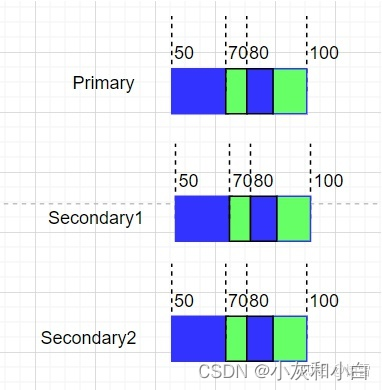
(3)Record Append具体的处理流程:
1)首先,主副本ChunkServer会校验当前的Chunk能否容纳下要追加的数据,如果能,主副本ChunkServer就将数据追加到当前Chunk中,然后给次副本ChunkServer发送指令,次副本ChunkServer也将数据追加到副本Chunk中。
2)如果当前的Chunk不能容纳,主副本ChunkServer就把当前Chunk剩余空间填充空数据,然后发送给次副本ChunkServer也把副本Chunk剩余空间填充空数据;然后主副本ChunkServer回复客户端“在下一个Chunk上写入”,客户端重新从Master节点获取新的Chunk位置,数据传输完毕后,再次向新的Chunk所在的主副本ChunkServer发起写指令。
3)因为数据写入的顺序是由主副本来控制的,且数据写入只有追加操作,因此主副本ChunkServer会将并发写入的数据进行排队,然后依次追加写入,这样就不会出现相互覆盖的情况了。
4)为了确保Chunk剩下的空间能存的下需要追加的数据,GFS限制了一次记录追加的数据大小为16MB,而Chunk大小默认是64MB,所以当空间不足需要补空数据时,最多也就是16MB,也就是最多也就浪费1/4的空间,不至于浪费太多。
defined interspersed with inconsistent:确定的但夹杂着不一致的数据
当某一副本写失败的时,会在失败的Chunk offset处填充空数据,三个副本一起重新写入一次,这就是“At Least Once”
例子1:
无并发的Record Append
客户端追加了一个数据a,第一次执行一半Secondary2失败了,那么此时这个Chunk的副本情况如下:
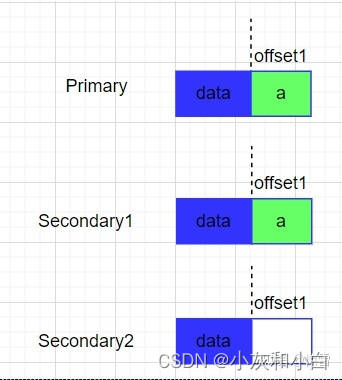
于是,客户端重新发起一次追加写操作,Primary先操作offset2后再将请求发给Secondary操作offset2,由于Secondary2上次操作offset1未成功,所以会先补空数据,然后再从offset2处写数据,那么此时副本情况如下:

并返回给客户端offset2。于是中间的offset1部分就是不一致的inconsistent,但对于新追加的数据就是确定的defined,客户端读offset2,就可以确定的读到a,这就是“defined interspersed with inconsistent确定的但夹杂着不一致的数据”。
例子2:并发记录追加
两个客户端分别向同一个文件追加数据a和数据b,Client1追加数据a,Client2追加数据b。假如Primary排序b,a。然后执行追加写操作,假如执行一半Secondary2失败了,同理,Client2会再次追加一遍,那么这个Chunk的副本情况如下:
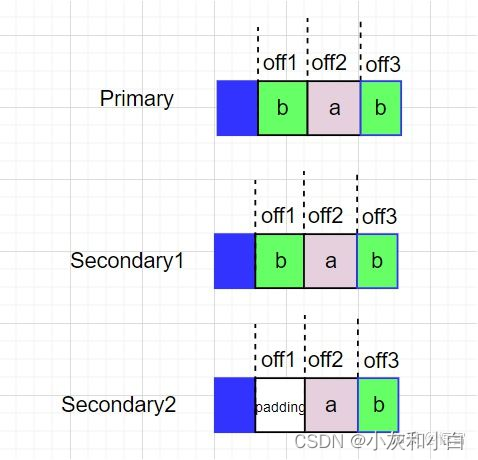
于是Client1收到offset2,Client2收到offset3,offset2和offset3都是确定的defined,而offset1是不一致的inconsistent,同样是“defined interspersed with inconsistent确定的但夹杂着不一致的数据”。
不同的副本中可能被追加了不同的次数,但“至少一次”是确定的defined,这就是“At Least Once”,这就是GFS承诺的一致性。可见GFS对写入数据的一致性保障相当低,它只是保障了所有数据追加至少被写入一次。
GFS将校验和去重的工作交给了客户端,GFS在客户端自带了对写入的数据去添加校验和(checksum),在读取数据的时候计算验证数据的完整性功能。而对于重复写入多次的问题,也可以对每一条要写入的数据生成一个唯一的ID,带上时间戳,那么即便数据顺序不对,有重复,也很容易在数据处理中根据ID进行排序和去重。
经过了一系列的成功的修改操作之后,GFS确保被修改的文件region是已定义的,并且包含最后一次修改操作写入的数据。GFS通过以下措施确保上述行为:
(a) 对Chunk的所有副本的修改操作顺序一致,
(b)使用Chunk的版本号来检测副本是否因为它所在的Chunk服务器宕机而错过了修改操作而导致其失效。
失效的副本不会再进行任何修改操作,Master服务器也不再返回这个Chunk副本的位置信息给客户端。它们会被垃圾收集系统尽快回收。
(4)过期失效的副本检测
如上文所说,当Chunk服务器失效时,Chunk的副本有可能因错失了一些修改操作而过期失效。Master节点保存了每个Chunk的版本号,用来区分当前的副本和过期副本。
无论何时,只要Master节点和Chunk签订一个新的租约,它就增加Chunk的版本号,然后通知最新的副本。Master节点和这些副本都把新的版本号记录在它们持久化存储的状态信息中。这些发生在任何客户端向Chunk写入数据之前。如果某个副本所在的Chunk服务器失效,那么他就持有一个过期的版本号。Master节点在这个Chunk服务器重新启动,并且向Master节点报告它拥有的Chunk的集合以及相应的版本号的时候,就会检测出它包含过期的Chunk。如果Master节点看到一个比它记录的版本号更高的版本号,Master节点会认为它和Chunk服务器签订租约的操作失败了,因此会选择更高的版本号作为当前的版本号。
(每个Chunk都有一个版本号)
Master节点在例行的垃圾回收过程中移除所有的过期失效副本。在此之前,Master节点在回复客户机的Chunk信息请求的时候,简单的认为那些过期的块根本就不存在。另外一重保障措施是,Master节点在通知客户机哪个Chunk服务器持有租约、或者指示Chunk服务器从哪个Chunk服务器进行克隆时,消息中都附带了Chunk的版本号。客户机或者Chunk服务器在执行操作时都会验证版本号以确保总是访问当前版本的数据。
参考文章:
05| GFS论文解读(2)
分布式系统论文精读2:GFS

















 7855
7855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









