







目录
一、Bigtable 中的 SSTable
Bigtable 内部采用 SSTable 的格式存储数据,子表的持久化状态信息保存在 GFS 上。那么 SSTable 的含义是什么?
论文中这样进行描述:An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings. Operations are provided to look up the value associated with a specified key, and to iterate over all key/value pairs in a specified key range. Internally, each SSTable contains a sequence of blocks (typically each block is 64KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks; the index is loaded into memory when the SSTable is opened. A lookup can be performed with a single disk seek: we first find the appropriate block by performing a binary search in the in-memory index, and then reading the appropriate block from disk. Optionally, an SSTable can be completely mapped into memory, which allows us to perform lookups and scans without touching disk.
论文没有指出 SSTable 的缩写,但是通常认为其为 Sorted String Table 的缩写。SSTable 有如下的特点:
- 持久化存储:强调 SSTable 存储在硬盘上而不是存储于内存中;
- 有序性:SSTable 中的数据根据 key 进行排序;
- 不可变性;
- 纯文本存储:key 以及 value 都是以文本的形式进行存储;
- 映射式查找:通过 key 来查找 value,通过 key range 来进行范围查找;
- 分 block(块)存储:每一个 SSTable 内部分为多个 block 进行存储,默认情况下 block 大小为 64 KB(可配置);
GFS 论文描述,GFS 中固定大小的 chunk 内部也分为 64 KB 的 block 进行存储管理,这一点是类似的。
- 块索引机制:在 SSTable 内部每一个 block 的索引,索引在打开 SSTable 时被加载到内存中。
将索引或者索引的一部分加载到内存中能够提高查询效率,因此今后对该索引的查询不涉及磁盘 I/O,这一点类似于 MySQL 中将 B+ 树的部分索引加载入内存中。可以选择将 SSTable 作为整体一次性加载进内存中,不过这显然会导致内存吃紧,但是好处是通过单次磁盘 I/O 的方式进索引数据读取。
SSTable 的本质实际上就是 a set of sorted key-value pairs,SSTable 中存储的其他数据以及拥有的机制都是为了这些键值对服务。
二、LevelDB 对 SSTable 的具体实现
Bigtable 论文远远没有 GFS 论文写得具体,论文中并没有给出 SSTable 的具体结构,不过我们可以学习 SSTable 的开源实现,由 Google 开发并开源的 LevelDB。
下图是 LevelDB 中 SSTable 的数据结构,如下图所示:
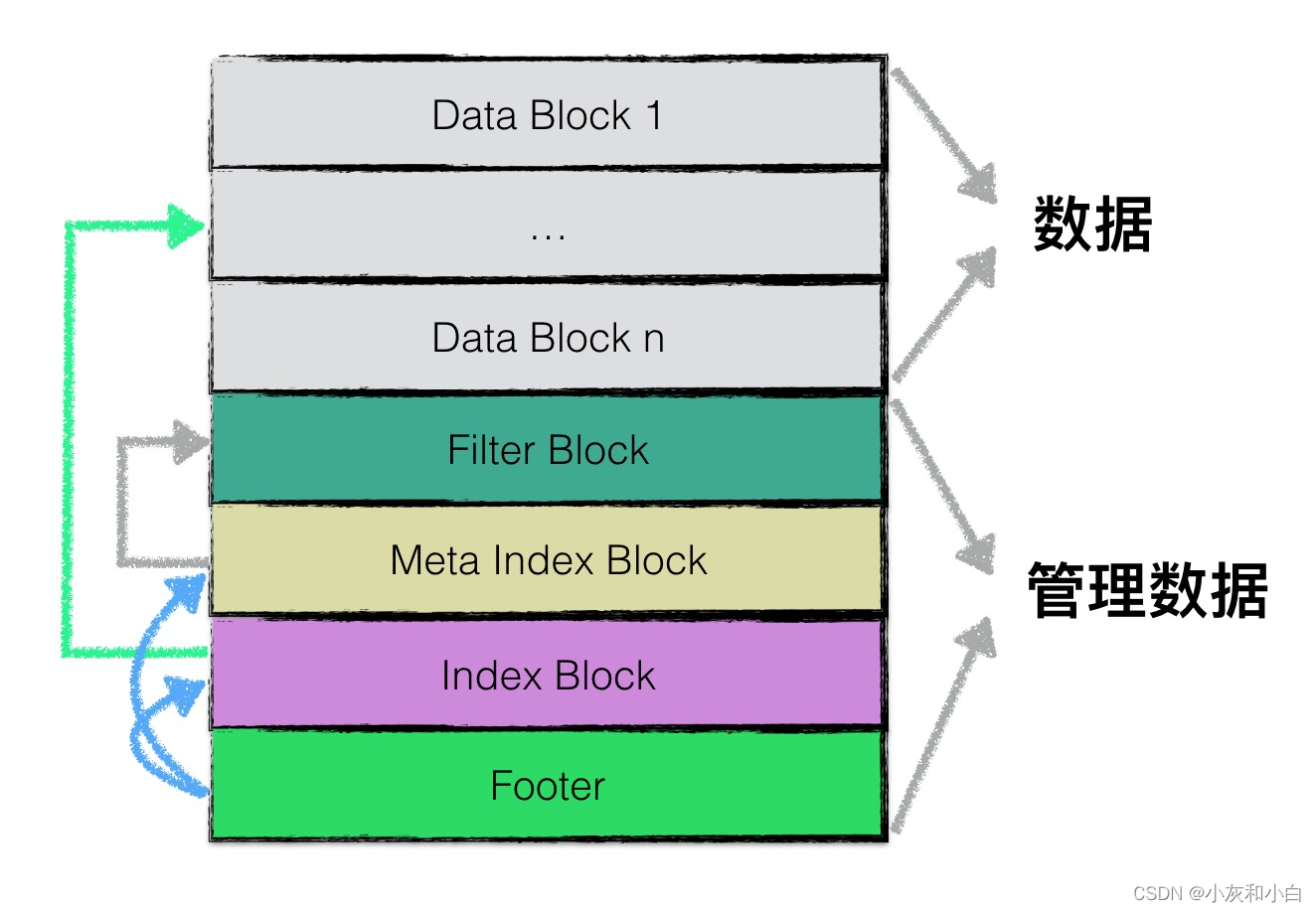
各个分块的作用为:
- data block: 用来存储 key value 数据对;
- filter block: 用来存储一些过滤器相关的数据(布隆过滤器),但是若用户不指定 leveldb 使用过滤器,leveldb 在该 block 中不会存储任何内容;
- meta Index block: 用来存储 filter block 的索引信息(索引信息指在该 sstable 文件中的偏移量以及数据长度);
- index block:index block 中用来存储每个 data block 的索引信息;
1.data block 数据结构
(1)对于 data block 的数据结构则如下(对于 LevelDB 而言):
为了提高整体的读写效率,一个 sstable 文件按照固定大小进行块划分,默认每个块的大小为 4KB(这个大小比 Bigtable 论文中所说的 64KB 要小上不少)。每个 Block 中,除了存储数据以外,还会存储两个额外的辅助字段:1.压缩类型 2.CRC校验码

由上可见,data block 有如下的特性:
- 数据压缩:压缩类型说明了 Block 中存储的数据是否进行了数据压缩,若是,采用了哪种算法进行压缩。leveldb 中默认采用 Snappy 算法 进行压缩。
- 校验码:CRC 校验码是循环冗余校验校验码,校验范围包括数据以及压缩类型。
GFS 中每一个 block 也采用校验码,不过仅仅使用简单的 checksum,可以把 CRC 校验码看做应有层的额外校验方式。
(2)但是我们在之前有提到,SSTable 本质上存储着一些列字符串键值对,因此上图的 Data 本质上为纯文本的 key-value 键值对。如果单独将 Data 数据列拿出来(不包括压缩类型、CRC 校验码),按逻辑又以下图进行划分:
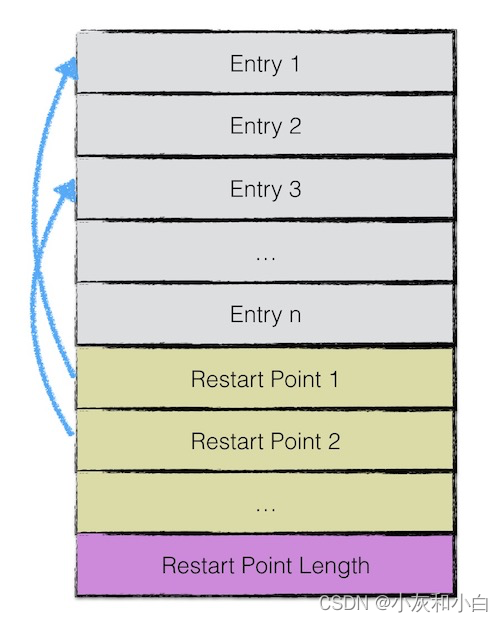
第一部 Entry 部分用来存储 key-value 数据。由于 SSTable 中所有的 key-value 对都是严格按序存储的,为了节省存储空间,leveldb 并不会为每一对 key-value 对都存储完整的 key 值,而是存储与上一个 key 非共享的部分,避免了 key 重复内容的存储。
每间隔若干个 key-value 对,将为该条记录重新存储一个完整的 key。重复该过程(默认间隔值为 16),每个重新存储完整 key 的点称之为 Restart point。Restart point 实际上连续存储,如上图的连续黄色块所示。
leveldb 设计 Restart point 的目的是在读取 SSTable 内容时,加速查找的过程。由于每个 Restart point 存储的都是完整的 key 值,因此在 SSTable 中进行数据查找时,可以首先利用 restart point 点的数据进行键值比较,以便于快速定位目标数据所在的区域;
当确定目标数据所在区域时,再依次对区间内所有数据项逐项比较 key 值,进行细粒度地查找;
在相同 key 规模不大的情况下这种方式查询效率不差,如果规模巨大,使用树状结构应当要好一点。
该思想有点类似于跳表中利用高层数据迅速定位,底层数据详细查找的理念,降低查找的复杂度。
(3)每一个 Entry 的数据结构如下图所示:

一个 entry 分为 5 部分内容:
- Shared key length:与前一条记录 key 共享部分的长度;
- Unshared key length:与前一条记录 key 不共享部分的长度;
key lenth = Shared key length + Unshared key length
- Value length:value 长度;
- Unshared key content:与前一条记录 key 非共享的内容;
- Value:value 内容;
例如:
restart_interval=2
entry one : key=deck,value=v1
entry two : key=dock,value=v2
entry three: key=duck,value=v3
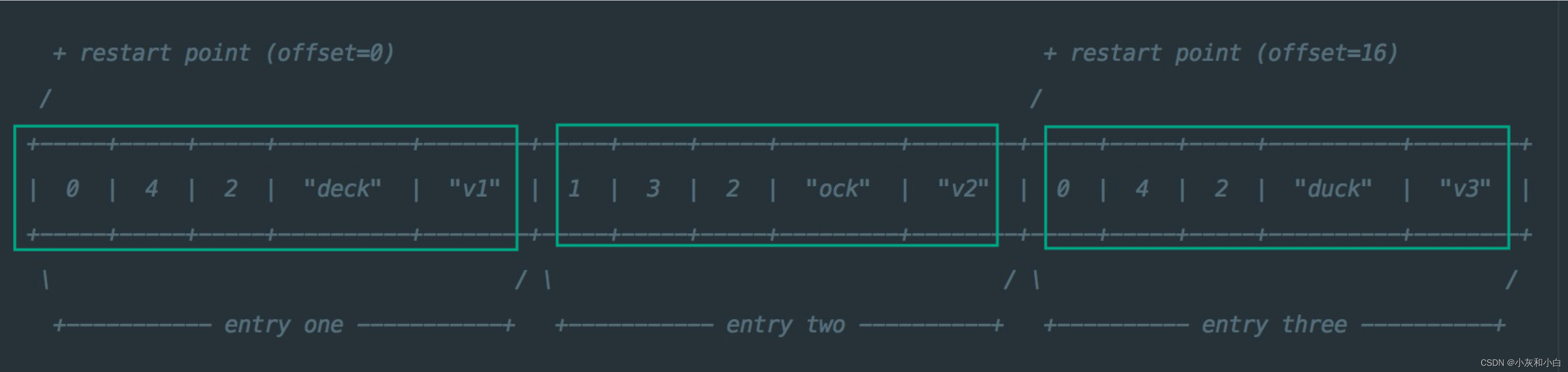
为什么能这么存储?这得益于 key value 均为纯字符串。在数据量非常大的情况下,按照字典顺序排序的 key 通常有如下性质:前面多个字符重复。比如这里的 deck dock duck 至少 d 都是重复的,在数据量大的情况下,重复的字符数要更多,比如 Google Map、Google Images、Google Search,“Google” 为相同的长字符串。
三组 entry 按上图的格式进行存储。值得注意的是,这里的 restart_interval 为 2,因此每隔两个 entry 都会有一条数据作为 restart point 点的数据项来存储完整 key 值。因此 entry3 存储了完整的 key。
2.filter block 数据结构
为了加快 SSTable 中数据查询的效率,在直接查询 datablock 中的内容之前,leveldb 首先根据 filter block 中的过滤数据判断指定的 datablock 中是否有需要查询的数据,若判断不存在,则无需对这个 datablock 进行数据查找。
filter block 存储的是 data block 数据的一些过滤信息。这些过滤数据一般指代布隆过滤器的数据,用于加快查询的速度。
布隆过滤器在很多场合都有使用,比如 Redis 利用布隆过滤器防止利用不存在数据的恶意攻击。布隆过滤器实现简单(基于 bitmap),虽然不能确定数据一定存在,但是精确判定数据是否不存在。
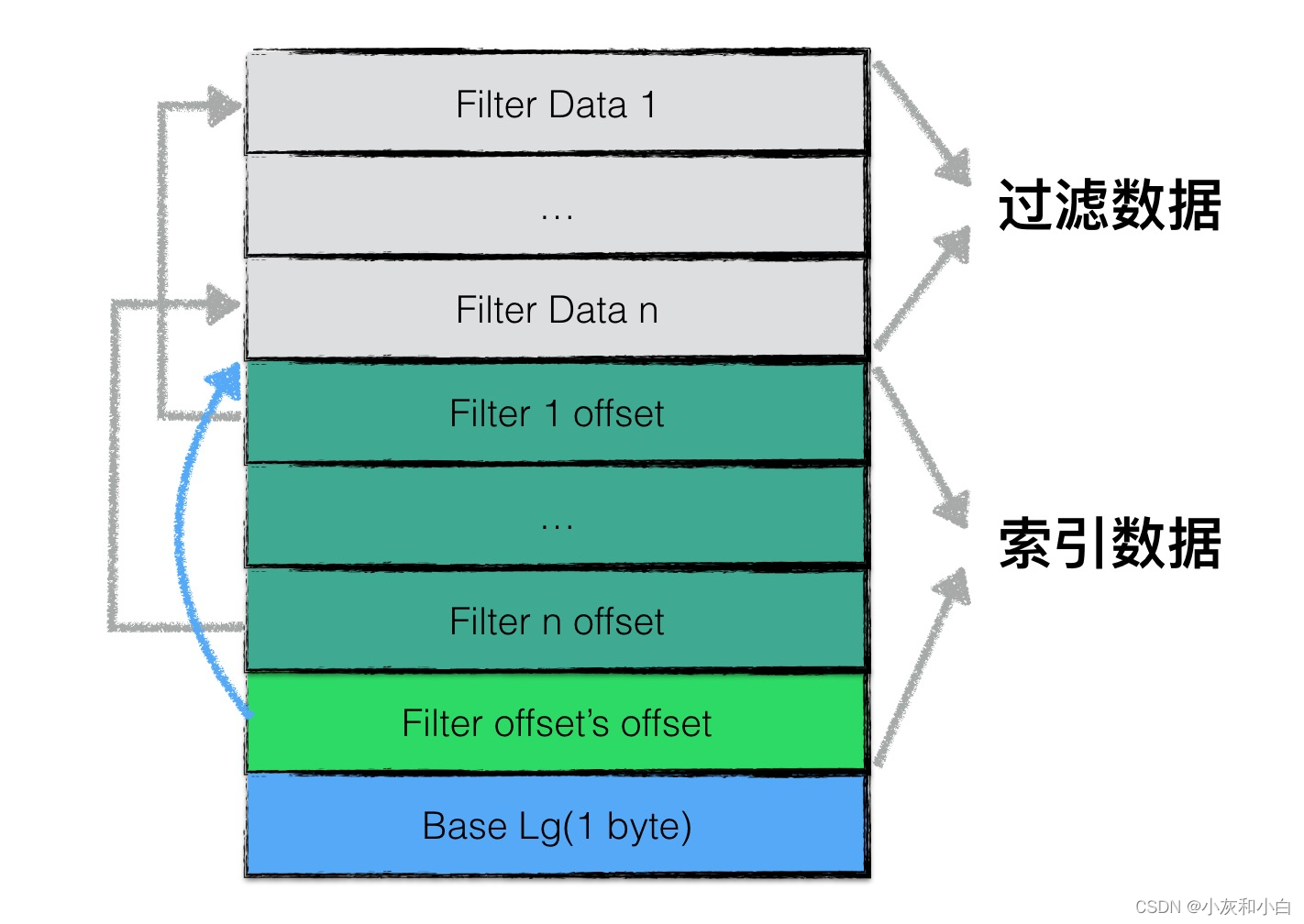
filter block 存储的数据主要可以分为两部分:过滤数据;索引数据;
其中索引数据中,filter i offset 表示第 i 个 filter data 在整个 filter block 中的起始偏移量,filter offset’s offset 表示 filter block 的索引数据在 filter block 中的偏移量。
在读取 filter block 中的内容时,可以首先读出 filter offset’s offset 的值,然后依次读取 filter i offset,根据这些 offset 分别读出 filter data。
Base Lg 默认值为 11,表示每 2KB 的数据,创建一个新的过滤器来存放过滤数据。
一个 SSTable 只有一个 filter block,其内存储了所有 block 的 filter 数据。具体来说,filter_data_k 包含了所有起始位置处于 [basek, base(k+1)] 范围内的 block 的 key 的集合的 filter 数据,按数据大小而非 block 切分主要是为了尽量均匀,以应对存在一些 block 的 key 很多,另一些 block 的 key 很少的情况。
leveldb 中,特殊的 SSTable 文件格式设计简化了许多操作,例如:索引和 BloomFilter 等元数据可随文件一起创建和销毁,即直接存在文件里,不用加载时动态计算,不用维护更新。
3.meta index block 数据结构
meta index block 用来存储 filter block 在整个 SSTable 中的索引信息。
meta index block 只存储一条记录:
- 该记录的 key 为:filter.+过滤器名字组成的常量字符串;
- 该记录的 value 为:filter block 在 SSTable 中的索引信息序列化后的内容,索引信息包括:
- 在 SSTable 中的偏移量;
- 数据长度;
4.index block 数据结构
与 meta index block 类似,index block 用来存储所有 data block 的相关索引信息。
indexblock 包含若干条记录,每一条记录代表一个 data block 的索引信息。
一条索引包括以下内容:
- data block i 中最大的 key 值;
- 该 data block 起始地址在 sstable 中的偏移量;
- 该 data block 的大小;
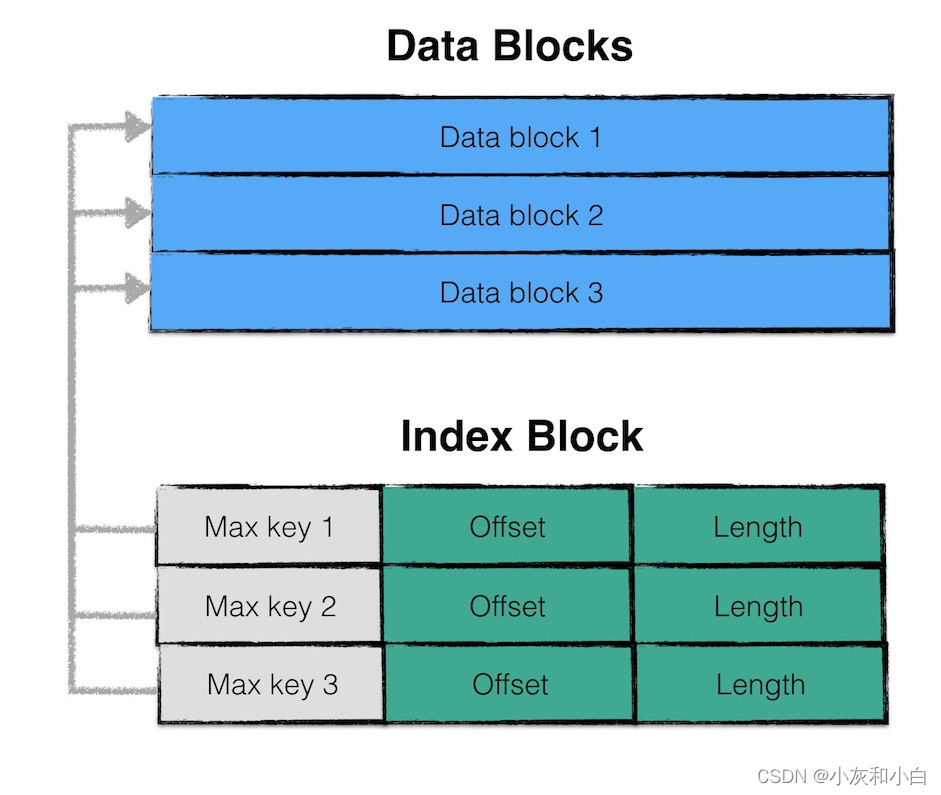
其中,data block i 最大的 key 值还是 index block 中该条记录的 key 值。如此设计的目的是,依次比较 index block 中记录信息的 key 值即可实现快速定位目标数据在哪个 data block 中。
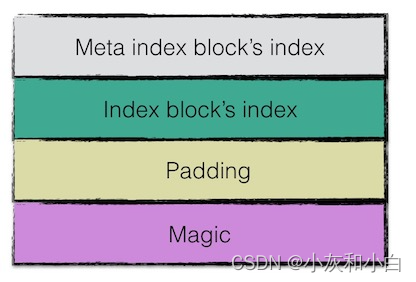
5.footer 数据结构
footer 大小固定,为 48 字节,用来存储 meta index block 与 index block 在 SSTable 中的索引信息,另外尾部还会存储一个 magic word,内容为:“http://code.google.com/p/leveldb/" 字符串 sha1 哈希的前 8 个字节。















 1243
1243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









