






从零开始搭建Hadoop集群,开启大数据之旅
准备工作
1.安装VMware 和Linux操作系统
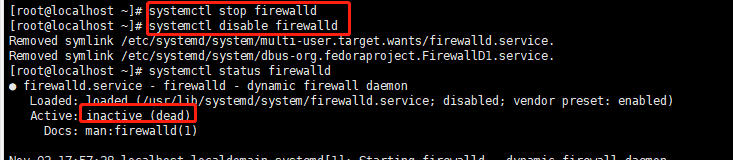
为了能够通过远程连接linux,首先关闭防火墙,开启时为running/active 关闭时为dead

查看防火墙状态: firewall-cmd --state或systemctl status firewalld
停止防火墙:systemctl stop firewalld
开机禁用:systemctl disable firewalld
hadoop底层使用的是Java语言,因此先安装Java环境
2.安装JDK
使用sftp上传jdk文件

解压文件到某个目录:
tar -zxvf jdk-8u141-linux-x64.tar.gz -C training/
配置环境变量作用:不用进入指定目录下启动脚本,可以在任意位置启动
.bash_profile 存放在/root目录下
编辑环境变量:vi .bash_profile(隐藏文件)
按下i键,进入编辑模式
配置环境变量:
JAVA_HOME=/root/training/jdk1.8.0_141
export JAVA_HOME
PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:PATH
export PATH

保存退出:键盘esc键(退出编辑模式)+:wq
生效环境变量:source .bash_profile
检验Java安装环境:java -version

java环境安装完成
3.安装Hadoop环境
上传文件

解压文件:tar -zxvf hadoop-2.8.4.tar.gz -C training
配置环境变量:
HADOOP_HOME=/root/training/hadoop-2.8.4
export HADOOP_HOME
PATH=
J
A
V
A
H
O
M
E
/
b
i
n
:
JAVA_HOME/bin:
JAVAHOME/bin:HADOOP_HOME/bin:
H
A
D
O
O
P
H
O
M
E
/
s
b
i
n
:
HADOOP_HOME/sbin:
HADOOPHOME/sbin:PATH
export PATH
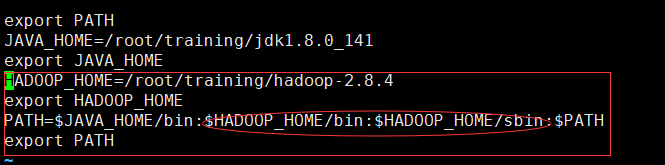
sbin目录下存放的是集群启动的可执行文件
生效环境变量:source .bash_profile
检验Hadoop:hadoop version

hadoop安装完成
搭建伪分布环境:
pwd:查看当前所在位置

vi core-site.xml

设置主节点名称(名称或ip地址)和端口:
fs.defaultFS
hdfs://bigdata112:9000
设置主节点元信息与数据存放位置:
hadoop.tmp.dir
/root/training/hadoop-2.7.3/tmp
vi hdfs-site.xml

设置冗余度大小:伪分布只有一个节点,设置为1
dfs.replication
1
设置是否需要检查权限:默认为true
dfs.permissions
false
由于没有此文件,需要先复制或重命名
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
设置任务调度框架为yarn
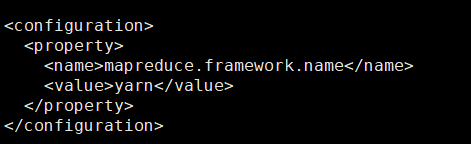
vi yarn-site.xml
设置yarn的主节点ResourceManager
yarn.resourcemanager.hostname
bigdata112
NodeManager的执行任务的核心是shuffle
yarn.nodemanager.aux-services
mapreduce_shuffle
格式化hdfs:hdfs namenode -format

格式化成功
vi hadoop-env.sh

export JAVA_HOME=/root/training/jdk1.8.0_141
启动hdfs:strat-dfs.sh
启动yarn:start-yarn.sh
启动hdfs和yarn:start-all.sh

需要输入4次密码,一次yes
查看hadoop进程:jps

HDFS:
NameNode:名称节点,主节点
SecondaryNameNode:第二名称节点
DataNode:数据节点
YARN:
ResourceManager:主节点
NodeManager:从节点
看到5个节点,说明hadoop启动成功
搭建bigdata集群
设置主机名
vi /etc/hostname
例如:
hadoop111
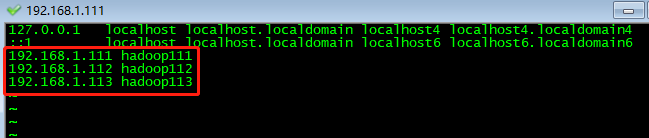
配置映射关系(为了简化配置,ip可以由主机名代替)
vi /etc/hosts
例如:
192.168.1.111 hadoop111
192.168.1.112 hadoop112
192.168.1.113 hadoop113
vi hdfs-site.xml
设置冗余度大小:全分布有两个数据节点,一个主节点,此处设置为数据节点=2
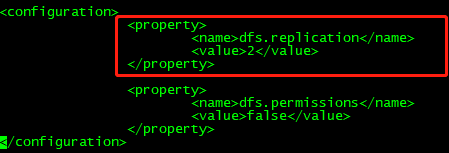
dfs.replication
2
vi slaves

设置数据节点:
hadoop112
hadoop113
将伪分布克隆成集群----->创建完整克隆
分别设置克隆的两台机器的hostname文件为hadoop112,hadoop113
配置网卡:

编辑ifcfg-*文件,不一定是ens33
vi /etc/sysconfig/network-scripts/ifcfg-ens33

ONBOOT=“yes”
IPADDR=192.168.1.111 网段必须是inet的192.168.1.x
GATEWAY=192.168.1.255 必须是192.168.1.x,不能与IPADDR冲突
DNS1=8.8.8.8
三台机器重启网卡:service network restart
克隆完在主节点执行start-all.sh,然后在主节点按照提示依次输入密码和yes,执行完成后
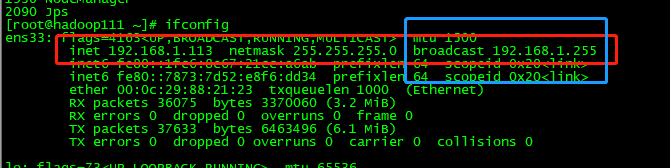
3台机器分别使用jps查看进程
看到如图所示,恭喜集群安装成功
















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









