







 本文详细解析了Kafka中数据查找的过程,包括如何通过offset定位数据在具体segment的位置,以及offset查找的具体机制。同时介绍了KafkaMessage的物理结构,帮助读者深入理解Kafka的数据存储和检索方式。
本文详细解析了Kafka中数据查找的过程,包括如何通过offset定位数据在具体segment的位置,以及offset查找的具体机制。同时介绍了KafkaMessage的物理结构,帮助读者深入理解Kafka的数据存储和检索方式。
一.kafka查找数据:
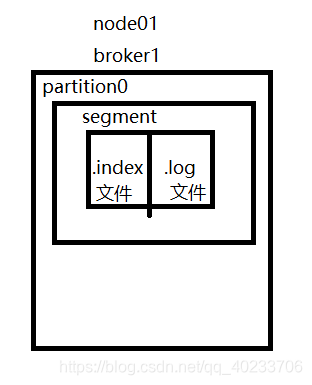
kafka里面一个topic有多个partition组成,每一个partition里面有多个segment组成,每个segment都由两部分组成,分别是.log文件和.index文件 。一旦.log文件达到1GB的时候,就会生成一个新的segment
.log文件:顺序的保存了我们的写入的数据
.index文件:索引文件,使用索引文件,加快kafka数据的查找速度
总结:查找数据的过程:
第一步:通过offset确定数据保存在哪一个segment里面了,
第二部:查找对应的segment里面的index文件 。index文件都是key/value对的。key表示数据在log文件里面的顺序是第几条。value记录了这一条数据在全局的标号。如果能够直接找到对应的offset直接去获取对应的数据即可
如果index文件里面没有存储offset,就会查找offset最近的那一个offset,例如查找offset为7的数据找不到,那么就会去查找offset为6对应的数据,找到之后,再取下一条数据就是offset为7的数据
二.kafka的offset查找过程:

三.kafka Message的物理结构及介绍:



















 84
84

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











