










序言
- 前段时间看了cdqa,所以自己顺手也把这个给看了看,没有细看,源码也只是大致浏览了下.
- 由于cdqa是继承drqa的关系,所以两者框架思路很很多trick都是通的.
- 下面先简单介绍一下这个项目,然后介绍一下他的retriever和reader.
简介
-
官方github
https://github.com/facebookresearch/DrQA/#machine-reading-at-scale
-
项目对应论文( 竟然是陈丹琪的一作…)
https://arxiv.org/abs/1704.00051 -
基本简单通读一遍论文,就知道他们在干什么了,具体细节读读源码就好了
进入正题:
- cdqa是闭源的,那drqa就是开源的,这里开源就是不针对某一个领域,因此他的documents库是wiki百科(涉及很多领域).但是使用维基百科作为文档的唯一知识来源,为和DeepQA区别故意点出.
- DrQA将维基百科视为文章的一般集合,不依赖其内部的图结构(wiki百科内部文档之间是有关联结构的)。因此,DrQA可以被直接应用于任何文档的集合.
- 文档检索器( retriever )通过wikipedia训练出来的TF-IDF模型( We use the 2016-12-21 dump2 of English Wikipedia for all of our full-scale experiments as the knowledge source used to answer questions.)
- reader模型是一个他们自己设计的基于双向RNN的框架( 那时候bert应该没出 )
Data
- 这部分简单提一下,因为下面有用.
SQUAD
- 简单介绍一下SQUAD:
- Each example is composed of a paragraph extracted from a Wikipedia article and an associated human-generated question. The answer is always a span from this paragraph and a model is given credit if its predicted answer matches it.
剩下还有: CuratedTREC , WebQuestions, WikiMovies数据集
远程监督(Distantly Supervised Data)
- 随便找了篇文章科普一下,远程监督浅谈:
- https://blog.csdn.net/yywang_hit/article/details/79705099
- 我把这块单独拿出来是因为看不懂这块它的实验表格你看不懂…所以你得清楚,它做了一个Distantly Supervised Data的trick,这个trick好像来源于命名体识别,然后他们借鉴过来了,用它干什么?
- 原因:除了squad,其他三个数据集只有QA对,没有对应文档段落的支持,所以为了和整个模型切合,需要从wikipidea文档里给他们找出对应的段落,和squad的结构一样.
- **找出的方式:**就是借鉴与Distantly superviesed的方式,找出tok篇article,然后筛选paragraph,等等,具体细节见论文(自己没有看到源码,不敢忘谈字面理解)
- 结果: 通过这种方式生成了额外的和squad类似的可以用于训练的数据集合,所以论文很多表格里面有类似下图( DS )的东西:
- 这个图简单说明了每一个数据集与训练的关系

多任务学习
- 随便一篇文章科普多任务学习
- http://www.pianshen.com/article/2477158462/
- 解释:其实我并没有看到这里有多任务学习的影子(论文也没注意到有说,但是看到部分博客里说了)…只是单纯几个不同训练集合在一起我觉得不是多任务学习,但是看到个新概念肯定先了解下,不深入.
Retriever
- 这部分自己重点看的( TF-IDF retriever ),简单说一下思路,很简单:
- 代码给出了他们在文档上统计好的一些信息,包括 TF-IDF权重( 行表示样本,列表示词库里的每一个单词,但是用了稀疏矩阵去存储)
- 给一个question,我们token以后,可以同样计算其 TF-IDF( 利用了documnet统计好的信息),但是这里有一个小trick(见下)
- 我们回顾一下,cdqa是继承Countervector类的方式,对documents进行fit,然后遇到question时transform,所以很多细节忽略了,这里,为了快速查找某一个单词IDF( 让我的话可能会用字典…),代码用了 murmurhash,很神奇的名字,你就看成对单词做hash就好了.
- 当然,retriever代码里面的hash只是体现方便快速查找,其他好处暂时不清楚.
- 词袋模型我觉得大家都理解,不理解看下(https://blog.csdn.net/ACM_hades/article/details/93085783),写的很不错,词袋模型由于看作单词无序独立,所以一点语序都没有,论文使用bi-ngram,就是稍微考虑了点局部语序以提升效果.
- 最后相似度就是两个稀疏矩阵点乘 ( Closest docs by dot product between query and documentsin tfidf weighted word vector space)
- 剩下什么排序的trick就不值得一说了
Reader
- 这部分看得不太仔细,
Encode
- 阅读理解模块的标配,分别对documens( paragraph)和qustion进行 encode
Paragraph encoding
- Specifically, we choose to use a multi-layer bidirectional long short-term memory network (LSTM), and take pi as the concatenation of each layer’s hidden units in the end
- 具体来说,我们选择使用多层双向长短时记忆网络(LSTM)来作为编码器encode paragraph,最后以pi为各层隐藏单位的串联,见下图:

- The feature vector p~i is comprised of the following parts:
- Word embeddings: We use the 300-dimensional Glove word embeddings trained from 840B Web crawl data
(Pennington et al., 2014). We keep most of the pre-trained word embeddings fixed and only fine-tune the 1000 most frequent question words because the representations of some key words such as what, how, which, many could be crucial for QA systems.
- 因为都很重要就放了原话,很简单的思路,word embedding没有随机初始化,用了glove论文提供的训练好的词向量,但是这里有一个trick,这个embedding层,作者只是让部分疑问词finetune,其他词都固定,你可以把固定理解为常量,finetune理解为变量,好处见上面英文.
- Exact match: We use three simple binary features, indicating whether pi can be exactly matched to one question word in q, either in its original, lowercase or lemma form. These simple features turn out to be extremely helpful.
- 这里就是人手工提取特征的trick了,三个二值特征( 0表示否定,1表示肯定,一般人而言啊我猜的…),分别对应段落的original, lowercase or lemma中是否匹配的到一个问题中的单词.
-
Token features: (其实就是每一个词的一些词法特征)
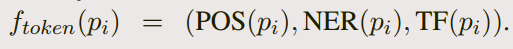
-
Aligned question embedding:
-
对于每一个文档的单词,他的这个embedding如下:( 其实就是注意力)
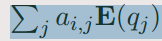
-
这里的E指的只是word embedding, α(·) is a single dense layer with ReLU
nonlinearity
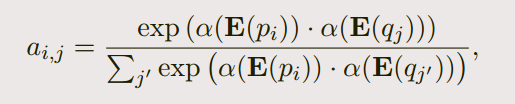
-
它没明说,但是大概率这些encoding最后是concat到一起,输入神经网络的.
Question encoding
- we only apply another recurrent neural network on top of the word embeddings of qi
and combine the resulting hidden units into one single vector
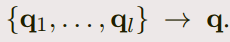
- 合并方式如下:
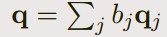
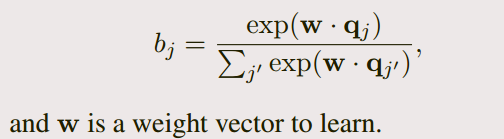
Prediction
- 预测的结构
we use a bilinear term to capture the similarity between pi and q and compute the probabilities of
each token being start and end as:
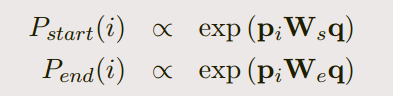
-
During prediction, we choose the best span from token i to token i0 such that i ≤ i0 ≤ i + 15 and
Pstart(i)×Pend(i0) is maximized -
模型结构基本就这样
END
本文完















 4849
4849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









