







今天刚学习NLP时,在使用NLTK的
import nltk
>>> text = "welcome reader.I hope you find it interesting.please do reply.">>> from nltk.tokenize import sent_tokenize
>>> sent_tokenize(text)
进行分词的时候出现如下的错误:
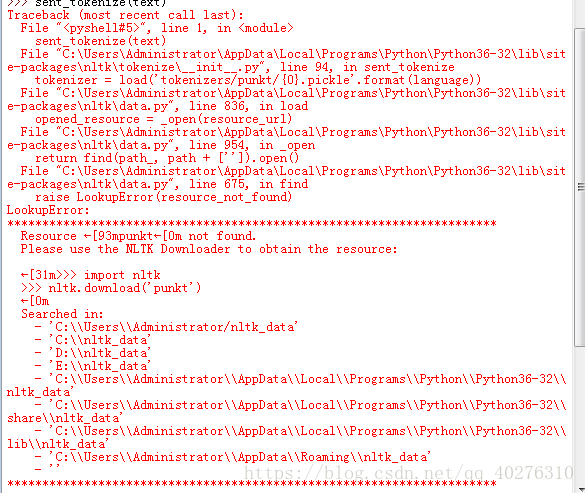
原因在于缺少一个模块
解决办法:输入
>>> nltk.download()
出现如下界面,点击下载模块punkt
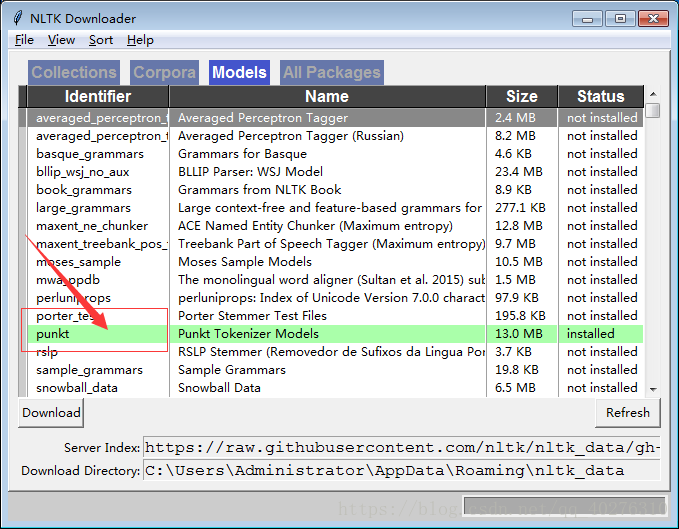
下载完punkt之后,word_tokenize可以分词成功了,如图:















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









