










正则表达式简介
为什么要学正则表达式?
实际上爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
我们down下了的数据是全部的网页,这些数据 很庞大并且很混乱,大部分的东西使我们不关心的,因此我们需要将之按我们的需要过滤和匹配出来。那么对于文本的过滤或者规则的匹配,最强大的就是正则表达式,是Python爬虫世界里必不可少的神兵利器。
什么是正则表达式?
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合, 组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。

正则表达式匹配规则



对URL地址进行匹配是一个相当困难的任务,其复杂性取决于你想获得多么精确的匹配结果。
最简单的情况下URL应该匹配的内容有:协议名(http|https),一个主机名,一个可选的端口
号,一个文件路径。


re模块
正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀, e.g. r’chuanzhiboke\t.\tpython’
re 模块一般使用步骤
-
使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象
-
通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。
-
最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:

Pattern 对象
正则表达式编译成 Pattern 对象, 可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就
返回, 而不是查找所有匹配的结果。它的一般使用形式:mach(string[,pos[,endpos]])
string 待匹配的字符串
pos 字符串的起始位置, 默认值是 0
endpos 字符串的终点位置, 默认值是 len (字符串长度)
- 1
- 2
- 3
- 4
- 5
Match 对象
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认 值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数 默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有 匹配的结果,它的一般使用形式如下:
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
findall 方法与finditer 方法
findall方法搜索整个字符串,获得所有匹配的结果。使用形式如下:
findall(string[,pos[,endpos]])
finditer方法的行为跟findall的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[,maxsplit])
maxsplit 指定最大分割次数,不指定将全部分割.
sub方法
sub 方法用于替换。它的使用形式如下:

repl 可以是字符串也可以是一个函数:
1). 是字符串,使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,
2). 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换.
count 用于指定最多替换次数,不指定时全部替换。
匹配中文
在某些情况下,我们相匹配文本中的汉字,有一点需要注意的是,中文的unicode编码范围,主要在[u4e00-u9fa5],这里主要是因为这个范围不完整,比如没有包括全部中文标点,不过在大部分情况下,应该是够用的。
贪婪模式与非贪婪模式:abbbc
1. 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( .* );
使用贪婪的数量词的正则表达式 ab* ,匹配结果: abbb。
* 决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。
2. 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
使用非贪婪的数量词的正则表达式 ab*? ,匹配结果: a。 .*? .+?
即使前面有 * ,但是 ? 决定了尽可能少匹配 b,所以没有 b。
3. Python里数量词默认是贪婪的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
范例
常见格式
# 导入正则表达式对应的模块;
import re
定义正则表达式的规则;
pattern = r’westos’
对正则表达式进行一个编译, 编译后, 匹配速度更快;
patternObj = re.compile(pattern)
将来要处理的字符串内容;
text = “hello westos hello world westos”
匹配符合正则规则的所有内容;
result = patternObj.findall(text)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果:
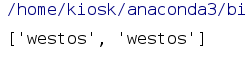
# 案例1: 匹配所有的qq邮箱, username@qq.com, 其中username必须是字母数字或者下划线, 次数为2-12个之间;
import re
pattern1 = r’\s\w{2,12}@qq.com’
text = ’ westos@qq.com hello@qq.com dhwehfhjrefhjrehfuhregiuhgggggggggggggiu@qq.com’
patternObj = re.compile(pattern1)
result = patternObj.findall(text)
print(result)
案例2:
北美电话的常用格式:(eg: 2703877865)
前3位: 第一位是区号以2~9开头 , 第2位是0~8, 第三位数字可任意;
中间三位数字:第一位是交换机号, 以2~9开头, 后面两位任意
最后四位数字: 数字不做限制;
pattern2 = r’(?[2-9][0-8]\d)?[-.\s]?[2-9]\d{2}[-.\s]?\d{4}’
text = ‘(323)4567890’
patternObj = re.compile(pattern2)
result = patternObj.findall(text)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:

分组
import re
“”"
http://www.baidu.com
https://www.baidu.com
ftp://www.baidu.com
“”"
| 或者
()分组, 如果有分组, 只返回分组里面匹配到的内容;
匹配http和https协议的URL地址;
r:代表规则为原生字符串, 一般情况下\代表转义的意思, 如果匹配的规则里面包含\时, 要写成\, 而有了r, 就不用\了.
URLpattern = r’((http|https)😕/(\w+.\w+.\w+))’
匹配http和https协议的URL地址;
URLpattern = ‘https?😕/\w+.\w+.\w+’
patternObj = re.compile(URLpattern)
text = ‘http://www.baidu.com https://www.baidu.com ftp://www.baidu.com’
result = patternObj.findall(text)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行结果:
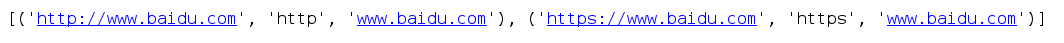
位置分组
import re
html = ‘<html><p>hello python</p></html>’
r:原生字符串, \代表转义, \如果没有r时必须用\代表\字符串;
“”"
<(.)>: 第一个分组
<(.)>: 第2个分组
(.): 第3个分组
</\2>: \2的位置必须和第二个分组的内容保持一致, 否则不匹配;
</\1>: \1的位置必须和第1个分组的内容保持一致, 否则不匹配;
“”"
pattern = r’<(.)><(.)>(.)</\2></\1>’
patternObj = re.compile(pattern)
result = patternObj.findall(html)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行结果:
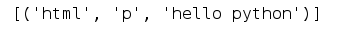
分割
import re
# 需求: 拿出运算操作中所有的数字
text = '1+3+5*10-8'
patternObj = re.compile(r'\+|-|\*|/')
# maxsplit=最大分割次数;
result = patternObj.split(text, maxsplit=4)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果:
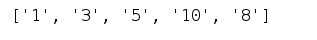
批量替换
"""
sub 方法用于替换。它的使用形式如下:
“”"
import re
text = “本文章点赞数为100, 转发数为20”
patternObj = re.compile(r’\d+’)
将text文本信息中符合patternObj规则的内容替换为0;
result = patternObj.sub(‘0’ , text)
print(result)
需求: 匹配到的所有数值+1
def addNum(matchObj):
“”“对匹配到的内容+1"”"
if matchObj:
# 目前num时一个字符串
num = matchObj.group()
# 在原有基础上加1 , num时数值类型
num = int(num) + 1
return str(num)
def add_perfix(matchObj):
if matchObj:
return ‘1002’ + matchObj.group()
result = patternObj.sub(addNum, text)
print(result)
result = patternObj.sub(add_perfix, text)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
运行结果:

正则案例:
"""
西刺代理IP定向爬虫
需求分析: 获取代理的IP和端口
"""
import re
import requests
User-Agent随机选择代理模块;
from fake_useragent import UserAgent
线程池
from concurrent.futures import ThreadPoolExecutor
def get_content(url):
“”“数据采集”""
try:
headers = {
‘User-Agent’: ua.random,
}
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
except Exception as e:
print("网页" + url + "爬取错误:", e)
return ''
else:
# response.text : 如果普通的页面, 用text, 返回字符串的内容
# response.content : 如果不是普通的页面(图片, 视频), 用content, 返回的时二进制内容;
return response.text
def html_parser(html):
“”“数据解析: IP:PORT”""
“”"
<tr class=“odd”>
<td class=“country”><img src="//fs.xicidaili.com/images/flag/cn.png" alt=“Cn”></td>
<td>113.89.53.247</td>
<td>9999</td>
</tr>
“”"
# 1. 获取每一行代理IP的详细内容;
# re.S: 表示“.”(不包含外侧双引号,下同)的作用扩展到整个字符串,包括“\n”。
# .代表除了\n之外的任意单个字符;
tr_pattern = re.compile(r’<tr class=.?>(.?)</tr>’, re.S)
trs = tr_pattern.findall(html)
# 2. 获取这一行IP代理的ip和port;
“”"
<td class=“country”><img src="//fs.xicidaili.com/images/flag/cn.png" alt=“Cn”></td>
<td>113.89.53.247</td>
<td>9999</td>
“”"
IPpattern = re.compile(r’<td>(\d+.\d+.\d+.\d+)</td>’) # .代表时真实的点字符串, 进行转义, 否则代表任意单个字符;
PortPattern = re.compile(r’<td>(\d+)</td>’)
for tr in trs:
ip = IPpattern.findall(tr)[0]
port = PortPattern.findall(tr)[0]
yield ip, port
def task(page):
“”"
多线程执行的任务: 数据采集和数据分析, 返回ip和port
:return:
“”"
print(“正在爬取第%d页” %(page))
url = ‘https://www.xicidaili.com/nt/%s’ % (page)
html = get_content(url)
results = html_parser(html)
return results
if name == ‘main’:
pages = 5
threadCount = 10
filename = ‘xici.csv’
# 创建用户代理的对象, 通过random属性随机获取一个User-Agent, 用于反爬虫处理;
ua = UserAgent()
with ThreadPoolExecutor(threadCount) as pool:
taskResults = pool.map(task, range(1, pages+1))
fw = open(filename, 'w')
count = 0
for taskResult in taskResults:
for item in taskResult:
count += 1
fw.write(",".join(item) + '\n')
# item: ('121.13.252.61', '41564')
# print(item)
print(count)
fw.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
运行结果:

保存到xici.csv里

















 248
248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









