







Hadoop平台MapReduce编程
目标:给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件table.txt内容如下:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
要求输出:
grandchild grandparent
Mark Jesse
Mark Alice
Philip Jesse
Philip Alice
Jone Jesse
Jone Alice
Steven Jesse
Steven Alice
Steven Frank
Steven Mary
Jone Frank
Jone Mary
一,实验环境准备
- 已搭建好的Hadoop环境
- Windows下准备环境完成
二,实验步骤
- 创建 maven 工程,MapReduceDemo
- 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
- 在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 编写程序
package com.xumx.mapreduce.work;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class STJoin {
public static int time = 0;
public static class Map extends Mapper<Object, Text, Text, Text> {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] childAndParent = line.split(" ");
List<String> list = new ArrayList<>(2);
for (String childOrParent : childAndParent) {
if (!"".equals(childOrParent)) {
list.add(childOrParent);
}
}
if (!"child".equals(list.get(0))) {
String childName = list.get(0);
String parentName = list.get(1);
String relationType = "1";
context.write(new Text(parentName), new Text(relationType + "+"
+ childName + "+" + parentName));
relationType = "2";
context.write(new Text(childName), new Text(relationType + "+"
+ childName + "+" + parentName));
}
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
if (time == 0) {
context.write(new Text("grand_child"), new Text("grand_parent"));
time++;
}
List<String> grandChild = new ArrayList<>();
List<String> grandParent = new ArrayList<>();
for (Text text : values) {
String s = text.toString();
String[] relation = s.split("\\+");
String relationType = relation[0];
String childName = relation[1];
String parentName = relation[2];
if ("1".equals(relationType)) {
grandChild.add(childName);
} else {
grandParent.add(parentName);
}
}
int grandParentNum = grandParent.size();
int grandChildNum = grandChild.size();
if (grandParentNum != 0 && grandChildNum != 0) {
for (int m = 0; m < grandChildNum; m++) {
for (int n = 0; n < grandParentNum; n++) {
context.write(new Text(grandChild.get(m)), new Text(
grandParent.get(n)));
}
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Single table Join ");
job.setJarByClass(STJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
-
将程序打包,点击Maven中package
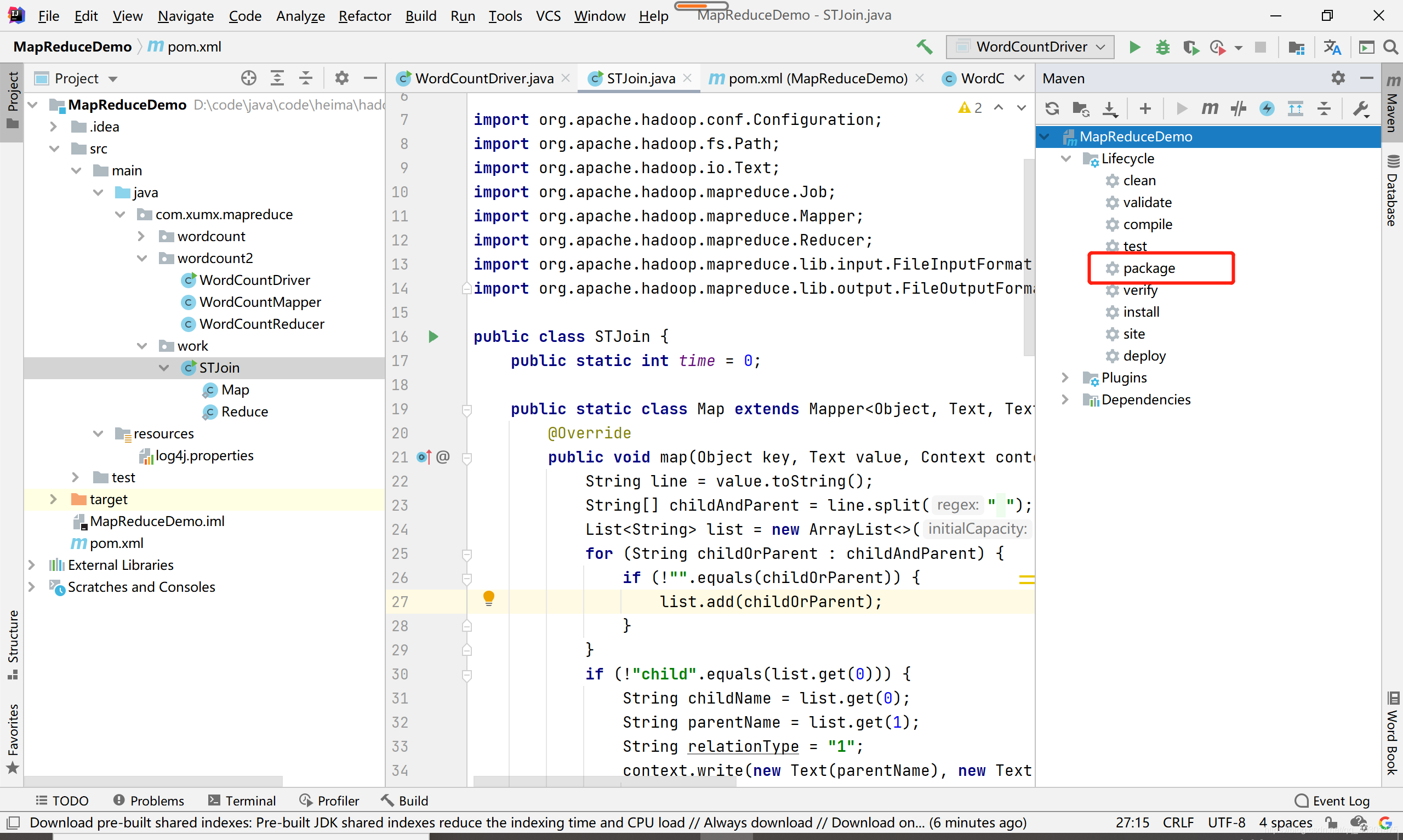
-
运行结束后,打开target,找到打包好的jar包
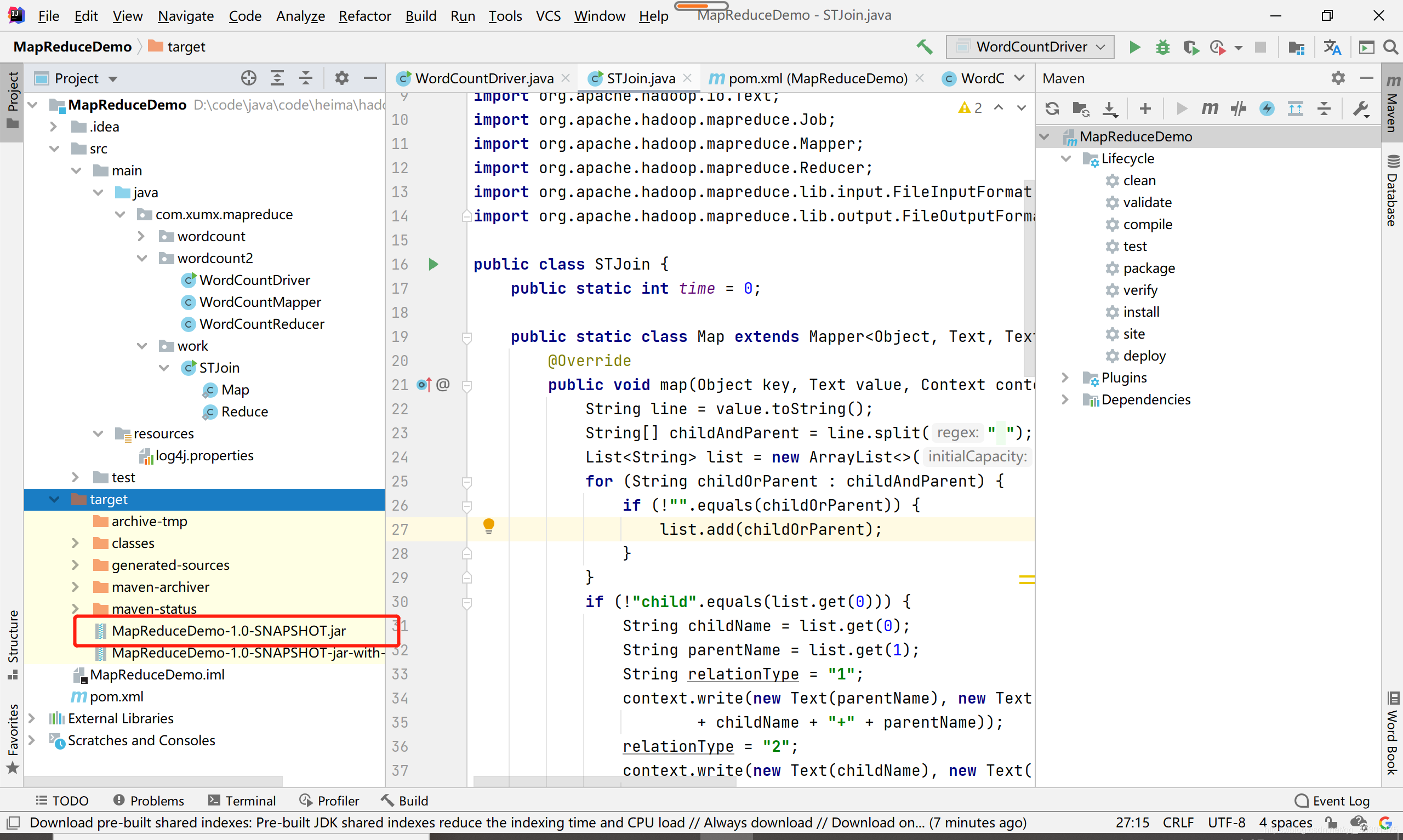
-
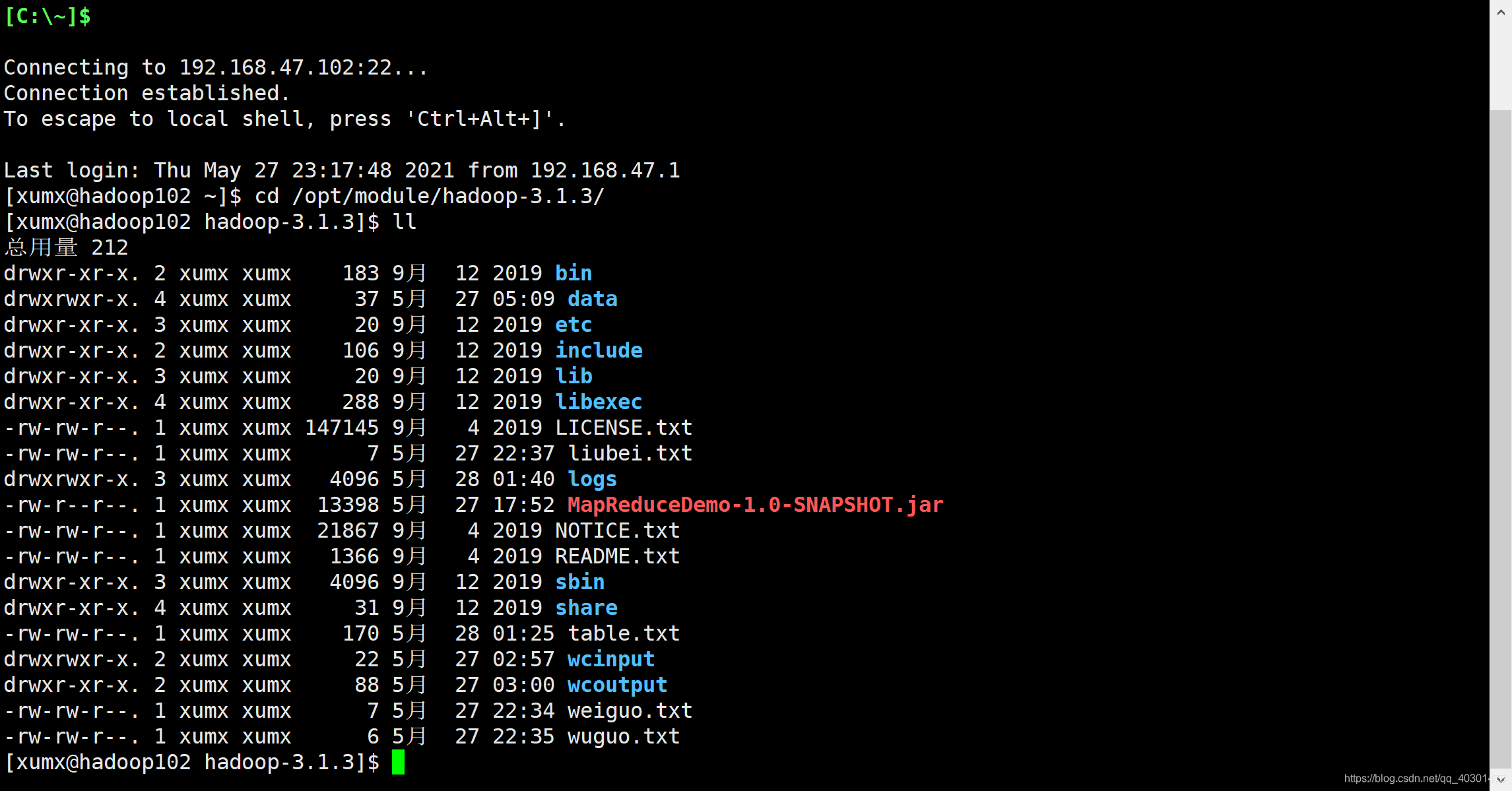
拷贝该 jar 包到 Hadoop 集群的/opt/module/hadoop-3.1.3 路径
三,程序结果验证
- 启动 Hadoop 集群
- 在/opt/module/hadoop-3.1.3目录下创建table.txt
[xumx@hadoop102 hadoop-3.1.3]$ vim table.txt
输入如下内容:
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
- 创建hdfs文件夹 /input5
[xumx@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input5
- 将table.txt文件上传至 /input5 目录下
[xumx@hadoop102 hadoop-3.1.3]$ hadoop fs -put table.txt /input5
- 运行程序
[xumx@hadoop102 hadoop-3.1.3]$ hadoop jar MapReduceDemo-1.0-SNAPSHOT.jar com.xumx.mapreduce.work.STJoin /input5 /output5
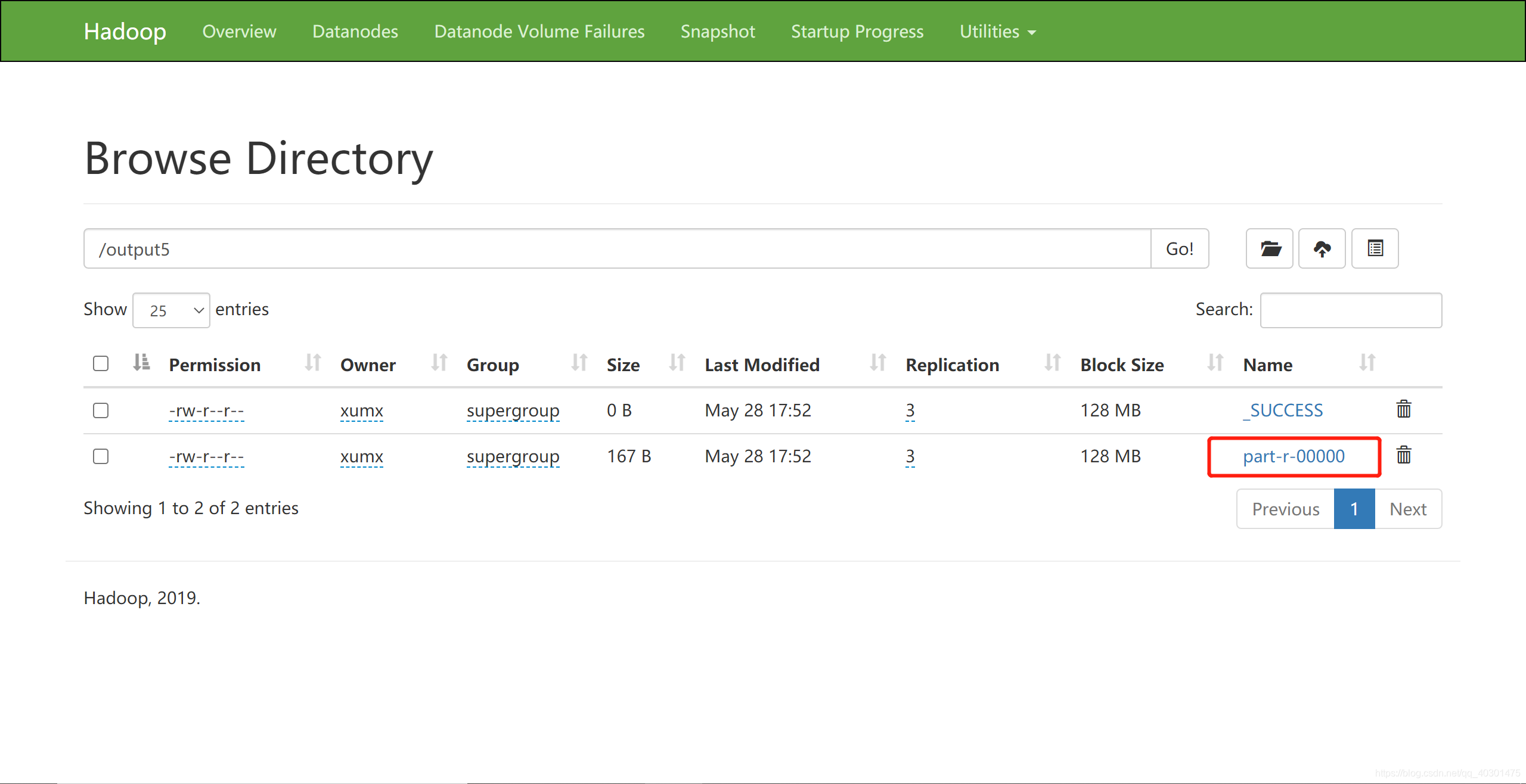
-
前端查看,发现多了output5文件夹,点进行
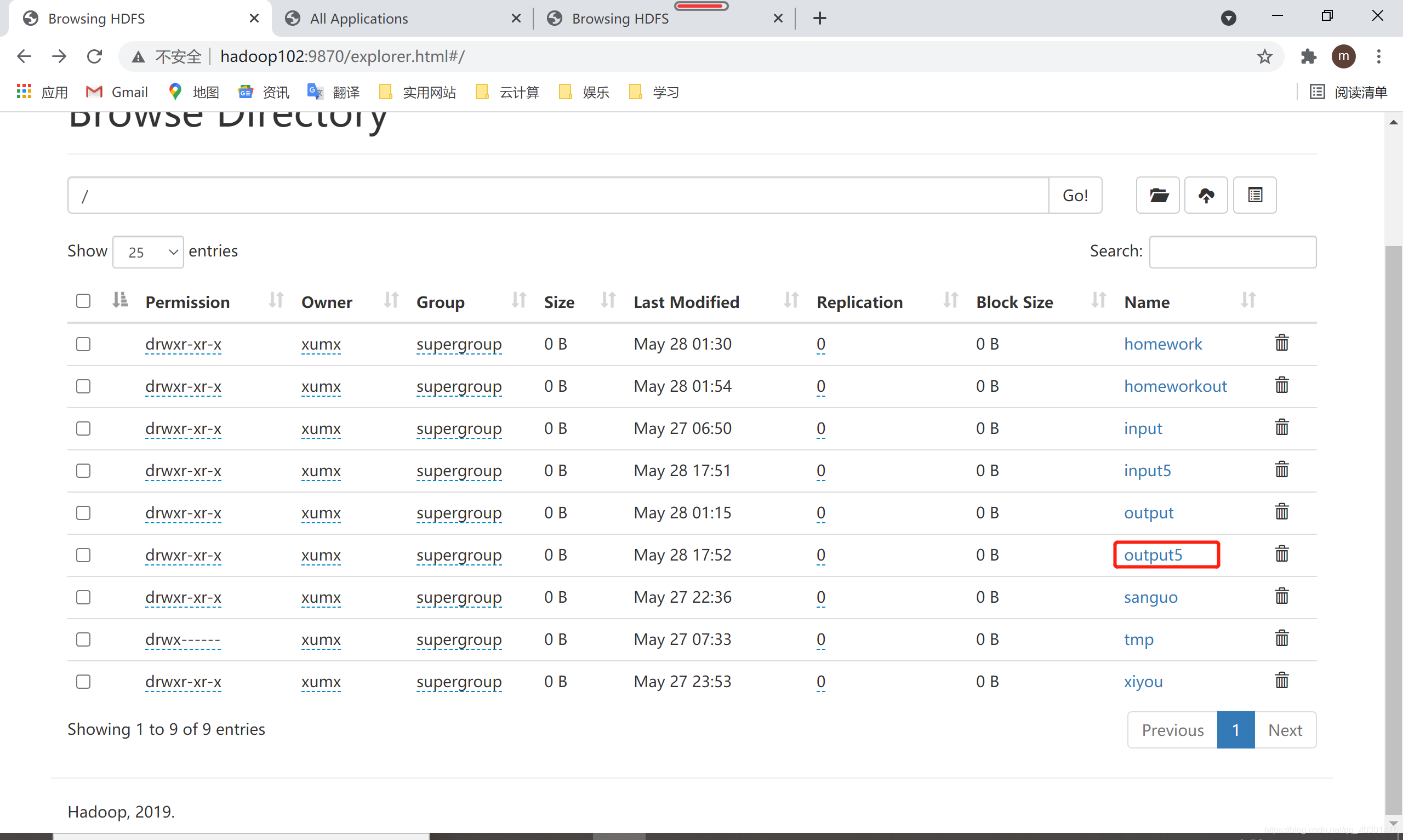
-
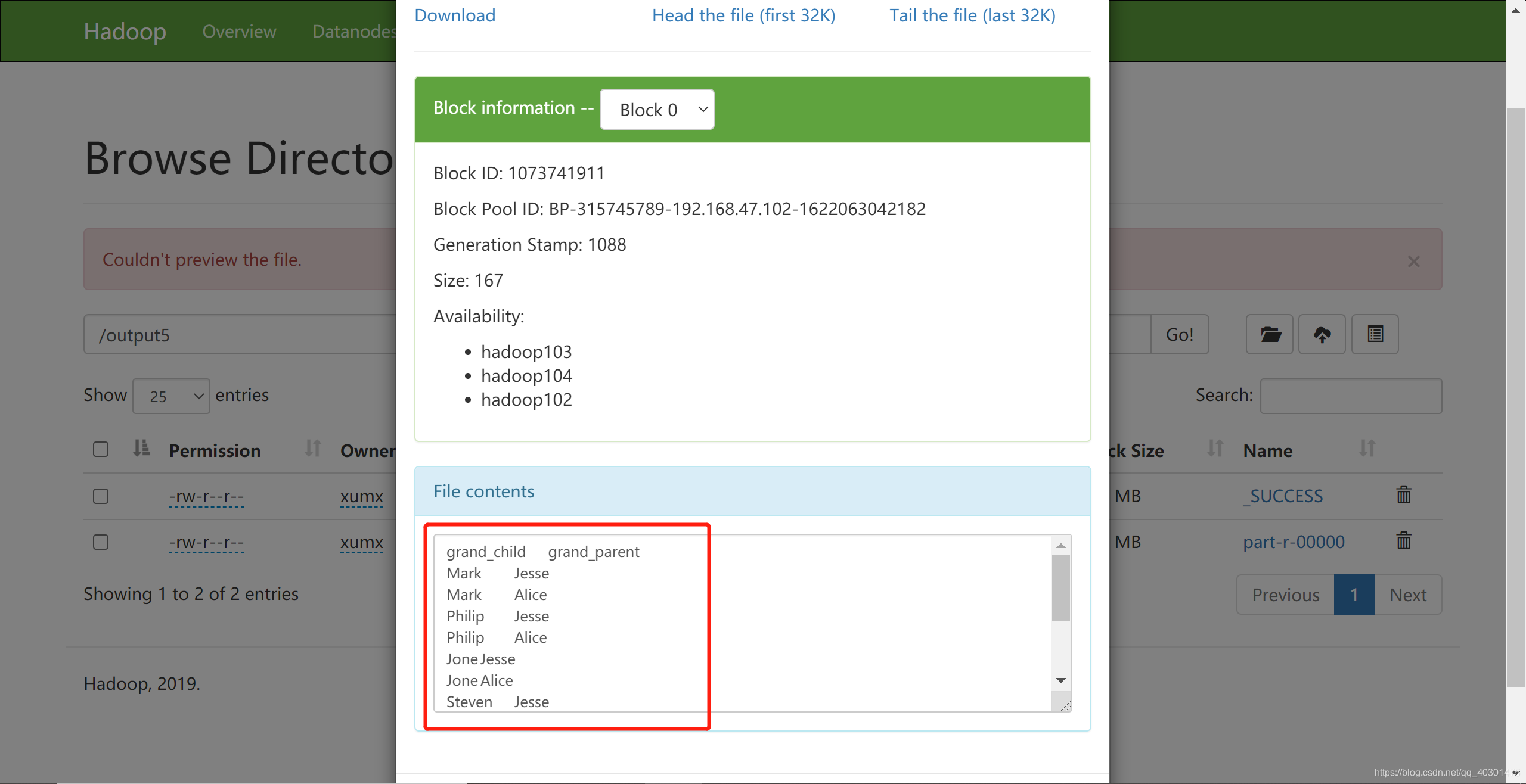
part-r-00000为运行结果
可以看到程序运行结果正确



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











