






教你快速上手AI应用——吴恩达AI系列教程
人工智能风靡全球,它的应用已经渗透到我们生活的方方面面,从自动驾驶到智能家居,再到医疗辅助和量化交易等等。他们逐渐改变了我们的生活方式,然而,对于许多人来说,AI仍然是一个神秘且无法理解的领域。
为了帮助更多的人理解并掌握AI技术,更享受AI带给人们便捷的服务,吴恩达博士开设了一系列的AI教程。接下来我们会通过几个项目的教程让大家学会如何用AI解决生活中的一些小问题,在AI时代来临之际,教会大家如何利用好这一有力的武器。
介绍吴恩达博士

编辑
吴恩达(英语:Andrew Ng,1976年4月18日—)是斯坦福大学计算机科学系和电气工程系的客座教授,曾任斯坦福人工智能实验室主任。
2011年,吴恩达在谷歌创建了谷歌大脑项目
2014年5月16日,吴恩达加入百度,负责“百度大脑
2017年12月,吴恩达宣布成立人工智能公司Landing.ai,担任公司的首席执行官。
5月初,DeepLearning.ai 创始人吴恩达联合 OpenAI 推出入门大模型学习的经典课程《ChatGPT Prompt Engineering for Developers》,迅速成为了大模型学习的现象级课程,获得极高的热度。后续,吴恩达教授又联合 LangChain、Huggingface 等机构联合推出了多门深入学习课程,助力学习者全面、深入地学习如何使用大模型并基于大模型开发完整、强大的应用程序。
在这篇博客中,我们将介绍吴恩达AI系列教程的第二部分,教你如何快速上手AI应用——我们将学习如何通过langchain构建向量数据库从而封装一本书,然后我们可以通过提问获取这本书相应的问题。
无论你是AI领域的初学者,还是有一定基础想要进一步提升的开发者。我们都能通过引导你让你在AI世界中发现自己的道路。
功能演示
让我们先来看看我们封装书籍后我们现在需要有防晒效果的全部衬衫以及对这些衬衫做一个总结:

编辑
我们可以看到模型会把所有的防晒衬衫全部信息表出来,并且会有一句很精炼的总结。
如何应用
首先我们要设置环境的配置
- 安装 langchain
python pip install langchain - 安装 docarray
python pip install docarray - 安装 tiktoken
python pip install tiktoken - 同时我们要设置自己的API_KEY环境变量
只需要您将API_KET填写在里面即可

编辑
我们先明白如何通过 langchain 调用模型
LangChain 是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
而 langchain 里面的模型主要分为三个类型:
LLM(大型语言模型) :这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
聊天模型( Chat Model) :聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
文本嵌入模型(Text Embedding Models) :这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
- 首先调用LLM模型
from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) #读取环境变量
```然后我们问 llm 模型如何评价人工智能,他就会通过 langchain 自动调用你的 OPENAI_API_KEY 告诉你 llm 模型生成的答案:
```python from langchain.llms import OpenAI
# auto read OPENAI_API_KEY
llm = OpenAI(model_name="text-davinci-003",max_tokens=1024) llm("怎么评价人工智能")
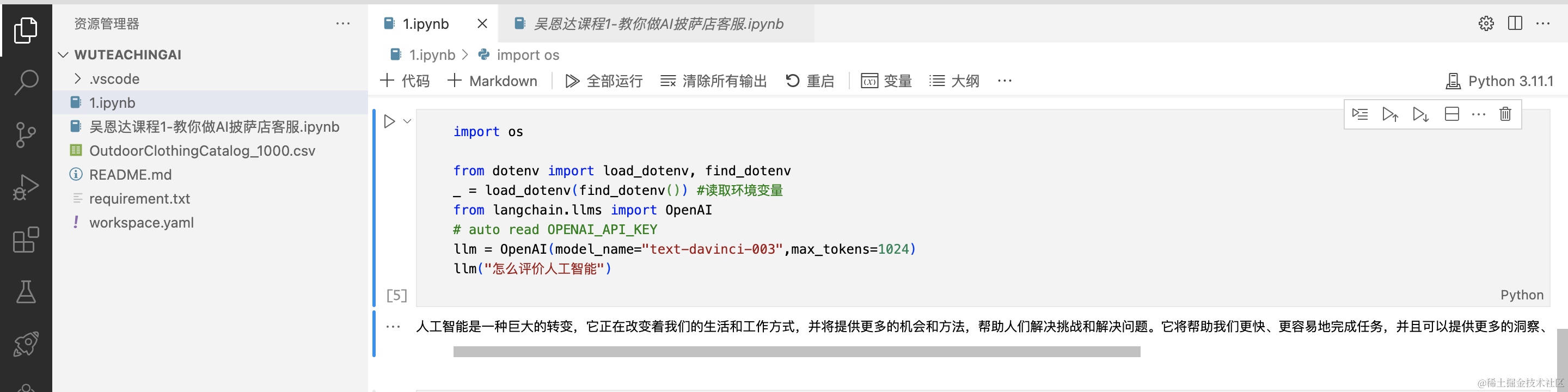
编辑
我们可以从图中看到,模型通过调用api接口回答了“怎么评价人工智能的回答”
导入 embedding 模型和向量存储组件
接下来我们会学习使用 embedding 模型和向量数据库做一个存储,利用 langchain 将我们的书籍进行封装。
- 我们首先把 langchain 的一些功能的包加载下来:
python from langchain.chains import RetrievalQA #检索QA链,在文档上进行检索 from langchain.chat_models import ChatOpenAI #openai模型 from langchain.document_loaders import CSVLoader #文档加载器,采用csv格式存储 from langchain.vectorstores import DocArrayInMemorySearch #向量存储 from IPython.display import display, Markdown #在jupyter显示信息的工具 在本次小项目中,我们的数据使用 Dock Array 内存搜索向量存储中,作为一个内存向量存储,不需要连接外部数据库
- 读取我们的户外户外服装目录书籍
我们首先可以在github仓库里获取该书籍[OutdoorClothingCatalog_1000.csv]
下载到本地后可以将该书上传到我们的 Cloud Studio 中,只需拖动即可上传:
- 加载书籍文件
# 读取文件
file = 'OutdoorClothingCatalog_1000.csv' loader = CSVLoader(file_path=file)
# 查看数据
import pandas as pd data = pd.read_csv(file,header=None) data

编辑
可以看到我们通过查看数据发现他提供了一个户外服装的CSV文件,文件中有很多种类衣服与他们的介绍,我们可以将这些与语言模型结合使用
- 创建向量存储
我们通过导入索引,即向量存储索引创建器:
python from langchain.indexes import VectorstoreIndexCreator #导入向量存储索引创建器
index = VectorstoreIndexCreator( vectorstore_cls=DocArrayInMemorySearch ).from_loaders([loader])
之后问他一个问题,例如我们可以让他列一下带有防晒衣的衬衫,然后给我们总结一下
query ="Please list all your shirts with sun protection \ in a table in markdown and summarize each one." response = index.query(query)#使用索引查询创建一个响应,并传入这个查询 display(Markdown(response))#查看查询返回的内容
我们就可以看到结果:

编辑
我们发现得到了一个 Markdown 的表格,其中包含了所有带有防晒衣的衬衫的名字与描述,还通过llm的总结得到了一个不错的总结“our shirts provide UPF 50+ sun protection, blocking 98% of the sun’s harmful rays. The Men’s Tropical Plaid Short-Sleeve Shirt is made of 100% polyester and is wrinkle-resistant”
语言模型与文档的结合使用
我们上面完成了一个书籍的存储以及调用语言模型回答里面的问题,而在我们的实际生活中如果想让语言模型与许多文档结合,怎么才能让他回答其中所有的内容呢?我们可以通过embedding和向量存储可以实现 - embedding 文本片段创建数值表示文本语义,相似内容的文本片段将具有相似的向量,这使我们可以在向量空间中比较文本片段
- 向量数据库 向量数据库是存储我们在上一步中创建的这些向量表示的一种方式,我们创建这个向量数据库的方式是用来自传入文档的文本块填充它。 当我们获得一个大的传入文档时,我们首先将其分成较小的块,因为我们可能无法将整个文档传递给语言模型,因此采用分块 embedding 的方式储存到向量数据库中。这就是创建索引的过程。
通过运行时使用索引来查找与传入查询最相关的文本片段,然后我们将其与向量数据库中的所有向量进行比较,并选择最相似的n个,返回语言模型得到最终答案
首先我们通过创建一个文档加载器,通过CSV格式加载
# 创建一个文档加载器,通过csv格式加载
loader = CSVLoader(file_path=file) docs = loader.load()
```然后我们可以查看一下单独的文档,可以发现每个文档都对应了CSV中的一个块

编辑
之后我们可以对文档进行分块和 embedding ,当文档非常大的时候,我们需要对文档进行分块处理,因为如果在较大文件的情况下我们的索引和提取会占用较大的内存使得效率变得很低,但是在此次小实验中,我们的文档并不大所以不需要进行分块处理,仅仅去做一个 embedding 就可以了
```python
''' 因为这些文档已经非常小了,所以我们实际上不需要在这里进行任何分块,可以直接进行embedding '''
from langchain.embeddings import OpenAIEmbeddings #要创建可以直接进行embedding,我们将使用OpenAI的可以直接进行embedding类 embeddings = OpenAIEmbeddings() #初始化
embed = embeddings.embed_query("Hi my name is Harrison")#让我们使用embedding上的查询方法为特定文本创建embedding print(len(embed))#查看这个embedding,我们可以看到有超过一千个不同的元素
我们的这个 embbding 可以查看到一千多个不同的元素,每个元素都是映射的数字值,组合起来就创建了这段文本的总体数值的表示
- 接下来我们将 embedding 存储在向量存储中
为刚才的文本创建embedding,准备将它们存储在向量存储中,使用向量存储上的 from documents 方法来实现。 该方法接受文档列表、嵌入对象,然后我们将创建一个总体向量存储
db = DocArrayInMemorySearch.from_documents( docs, embeddings )
运行这个程序,我们就能得到存储了书籍的向量数据库了

编辑
这时我们可以通过一个类似查询的文本传会给向量数据库,我们可以让他返回一些文本:
query = "Please suggest a shirt with sunblocking" docs = db.similarity_search(query)#使用这个向量存储来查找与传入查询类似的文本,如果我们在向量存储中使用相似性搜索方法并传入一个查询,我们将得到一个文档列表 len(docs)

编辑
可以看到返回了四个文档,同时我们可以打开第一个文档:

你可以看到,第一个文档的确是关于防晒的衬衫相关的内容
如何回答跟我们文档相关的问题
要回答和我们文档相关的问题我们需要通过检索器支持查询和返回文档的方法,并且通过导入语言模型的方式进行文本生成并返回自然语言响应
所以我们应该先做的第一步是创建检索器通用接口以及导入语言模型
retriever = db.as_retriever() #创建检索器通用接口 llm = ChatOpenAI(temperature = 0.0,max_tokens=1024) #导入语言模型 qdocs = "".join([docs[i].page_content for i in range(len(docs))])
# 将合并文档中的所有页面内容到一个变量中
- 通过调用语言模型来问问题
response = llm.call_as_llm("Question: Please list all your shirts with sun protection in a table in markdown and summarize each one.") #列出所有具有防晒功能的衬衫并在Markdown表格中总结每个衬衫的语言模型
然后我们可以通过 markdown 形式查看语言模型通过调用语言模型的总结,以及在文本中存在的关于防晒功能衬衫的所有信息

这样我们就得到了我们想要的结果!
如果有多个文档,那么我们可以使用几种不同的方法
- Map Reduce
将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的
- Refine
用于循环许多文档,际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。它通常需要更长的时间,并且基本上需要与Map Reduce一样多的调用
- Map Re-rank
对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分,并在那里精细调整说明,可以批量处理它们相对较快,但是更加昂贵
- Stuff
将所有内容组合成一个文档
在这里我们就不举太多例子,欢迎各位进入 Cloud Studio 自己体验!!!
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









