







文章目录
论文:ROMA: Multi-Agent Reinforcement Learning with Emergent Roles
存在的问题&研究动机&研究思路
- ROMA提出智能体的策略是建立在智能体角色上的。
- 智能体的角色是由智能体的局部观测值决定的随机变量,有相似职责的智能体有相似的角色。相似智能体倾向于特定的子任务。
创新点
-
使用encode-decoder结构:
encoder产生均值和方差,角色 ρ i \rho_i ρi从中采样得到:
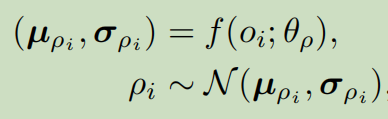
decoder根据角色 ρ i \rho_i ρi产生智能体 i i i的效用函数。 -
最大化条件互信息 I ( τ i ; ρ i ∣ o i ) I(\tau_i;\rho_i|o_i) I(τi;ρi∣oi),使得角色 ρ i \rho_i ρi可通过轨迹 τ i \tau_i τi辨认。可转化为最小化如下loss:
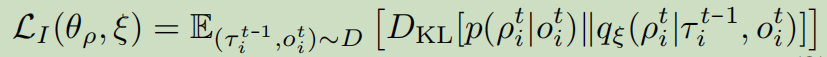
-
提出以下约束,鼓励两个智能体要么有相似的角色(执行相似的任务),要么行为大相径庭:
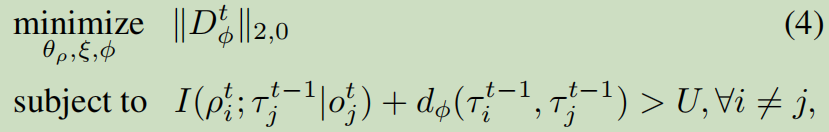
约束中第一项互信息,若此项较大,证明智能体i与智能体j角色相似,执行相似的任务。若第二项较大,证明两智能体角色差距较大,则行为应该不相似。上述最优化问题可转化为优化如下loss:
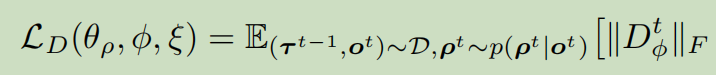
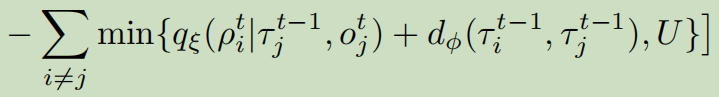
-
最终loss为:
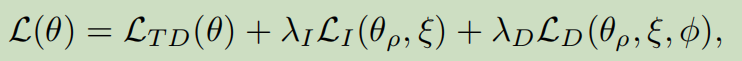
-
执行过程中,只有角色的encoder、decoder和智能体局部效用函数work。
算法框图

some points
- 通过最大化互信息使得两种分布更接近。
- 将角色转化为分布,从而可以最大化互信息,从而使得角色 ρ i \rho_i ρi可与轨迹 τ i \tau_i τi实现近似的一一对应,即Identifiable。















 1288
1288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









