






hadoop搭建
(如果后面还要配置hive、hbase等等工具,推荐hadoop2.7或者2.6,不推荐3.0以上的,亲身经历,bug多多,虽然我这个是配置的3.2.0,但是和2.7的步骤是一样的,改改名字就行,注意配置文件中的路径即可。)
虚拟机及网络配置:https://blog.csdn.net/qq_40343117/article/details/99692659
jdk配置地址:https://blog.csdn.net/qq_40343117/article/details/99705080
一、关闭防火墙
输入
systemctl stop direwalld // 停止防火墙
systemctl disable firewalld //禁止防火墙开机启动
firewalld-cmd --state //查看防火墙状态


输入vi /etc/selinux/config将SELINUX设置为disabled

二、配置 hostname
1、配置hostname,输入,后面的名字可以自己改
hostnamectl set-hostname h01

2、输入vi /etc/hosts配置我们三台机器的ip地址和对应的hostname
 (注意,重启终端再进入就可以看到更改的名字)
(注意,重启终端再进入就可以看到更改的名字)
三、下载hadoop
下载地址:https://hadoop.apache.org/releases.html
选择binary版本就可以,这个是里面已经配置好了,我们使用就可以,source 是让人去开发自主使用的。(自己选择合适版本)
不推荐3.2.0,因为后面要用到hbase等系列的话,会产生不兼容等问题,3.1.2测试还可以,暂时没问题

四、克隆虚拟机
我们的hadoop是一个集群,所以只有一个虚拟机 是肯定不够的,这里我安装三台虚拟机,一开始我们一直配置的h01作为namenode,h02,h03作为datanode
关闭虚拟机h01,右键选择管理-克隆,一直下一步到克隆类型,选择完整克隆

设置名称和克隆位置

结束,相同步骤克隆出h03
五、配置hadoop前的准备
(我只写了h02的配置,h03相同,只是ip地址不能也一样)
1、配置hostname,输入,后面的名字可以自己改
hostnamectl set-hostname h02
 输入
输入vi /etc/hosts

2、配置网络
输入之后,更改ip地址为192.168.228.102,主机是101
vi /etc/sysconfig/network-scripts/ifcfg-ens33
 输入
输入service network restart重启网络
 尝试输入
尝试输入 ping www.baidu.com

一定要三台机器互相ping通才可以继续

3、测试java配置

成功(以上的几步h03相同)
4、配置SSH免密码登陆
生成秘钥,输入ssh-keygen -t rsa -P '',直接回车,什么也不用管,一直到结束
(每台机器都要运行一次)
 使用root账户会将产生的秘钥文件存在/root/.ssh
使用root账户会将产生的秘钥文件存在/root/.ssh

我们新建一个authorized_keys文件用来存储秘钥
输入touch /root/.ssh/authorized_keys
 输入
输入cat id_rsa.pub >> authorized_keys汇总秘钥到新建的文件中

输入scp /root/.ssh/authorized_keys @h02:/root/.ssh/(h03)将文件复制到h02和h03的指定位置
 进行测试登陆,在h01输入
进行测试登陆,在h01输入ssh h02,输入exit退出(一定要互相测试,保证没有问题,比如h02测h03,h03测h01等等)

注意,第一次远程连接,会提示输入密码,正常的

六、配置hadoop
1、将压缩包放到虚拟机
mobaX可以直接把文件拖到虚拟机中
 2、解压压缩包
2、解压压缩包
输入tar -zxvf /usr/local/hadoop-3.2.0.tar.gz -C /usr/local/
 3、配置环境变量
3、配置环境变量
输入vi /etc/profile
在里面输入(一定改成自己的文件路径)
export HADOOP_HOME=/usr/local/hadoop-3.2.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出,输入scp /etc/profile @h02:/etc/profile将配置文件传到h02,h03
 选择mobaX的terminal
选择mobaX的terminal
 然后我们就可以同时操作三台虚拟机,可以一起输入
然后我们就可以同时操作三台虚拟机,可以一起输入source /etc/profile来更新环境变量
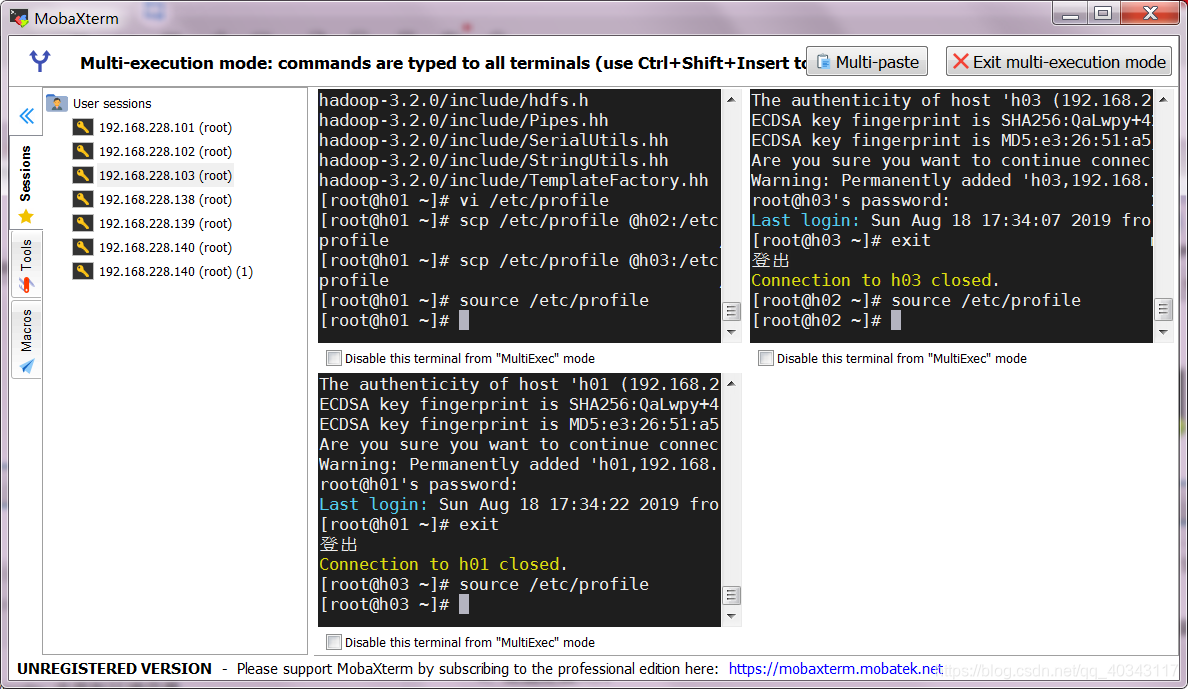 输入hadoop version 查看是否配置成功(只有h01可以,因为h02,h03我们还没有安装hadoop,不要急,后面会在配置好以后直接传输到h02,h03)
输入hadoop version 查看是否配置成功(只有h01可以,因为h02,h03我们还没有安装hadoop,不要急,后面会在配置好以后直接传输到h02,h03)

单击退出

4、配置配置文件
重中之重,经常出错,虽然不难,但是很烦,一定要仔细
推荐给大家一个用notepad++远程连接虚拟机修改配置文件的方法,因为用惯了windows,linuix的vi还是不是很舒服。
打开notepad++,选择插件-插件管理
 找到一个叫Npp-Ftp,我按过了,没安过的在Availiable里面
找到一个叫Npp-Ftp,我按过了,没安过的在Availiable里面
 安装以后旁边出现一个窗口,选择profile settings
安装以后旁边出现一个窗口,选择profile settings

单击addnew,输入你的hostname

输入ip地址和你的密码,username写root就可以,注意最后的目录写/就是我们配置虚拟机设置的根目录

单击小管子图标,选择新建的h01

连接成功,直接点击找到你想更改的文件就可以

找到/usr/local/hadoop-3.2.0/etc/hadoop找到配置文件(按照自己的安装路径来)
配置hadoop-env.sh
输入
#java环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
#设置为root用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
ctrl+s保存就直接保存到虚拟机了,是不是很方便,而且很灵活。

下面的配置文件一定要放在之间
打开core-site.xml
我们先建一个文件夹存放临时文件(三台机器都要有),输入
mkdir /usr/local/tmp
输入(h01换成自己的主机名,就是作为namenode的名字,路径也换成自己的)
<property>
<name>fs.defaultFS</name>
<value>hdfs://h01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/tmp</value>
</property>

配置hdfs-site.xml
新建文件夹用来保存元数据和一般数据(三个都有)
mkdir /usr/local/hdfs
mkdir /usr/local/hdfs/name
mkdir /usr/local/hdfs/data
输入
<!--secondnamenode的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>h01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>h01:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
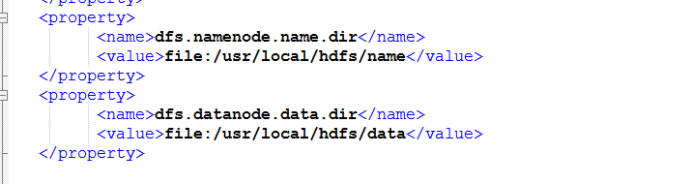
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hdfs/data</value>
</property>

配置workers/salves
输入你的从机名

配置yarn-site.xml
输入
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

配置mapred-site.xml
输入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
 5、将hadoopo分发给h02/h03
5、将hadoopo分发给h02/h03
输入scp -r /usr/local/hadoop-3.2.0 @h02:/usr/local/
输入hadoop version检查是否成功
 6、格式化namenode
6、格式化namenode
输入hadoop namenode -format,不用管过程,最后出现sucusseful就行了
(注意namenode最好格式化一次,多了会出现currentIID不匹配的问题,导致无法启动namenode,且注意重新更改配置文件之后,不需要重新格式化namenode,除非你改了其中与namenode有关的路径
例如:
启动不了namenode

Hdfs-site.xml这里的目录不能改,格式化namenode之后这里面会出现新的文件夹帮助系统找到namenode,你更改路径之后里面不会有这个文件夹
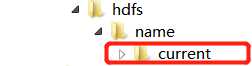
你可以更改路径名或者复制这个文件夹到你的新路径下的name里面
)
正常格式化:

7、测试登陆hadoop
输入start-all.sh成功

输入jps成功
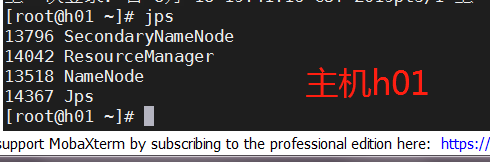
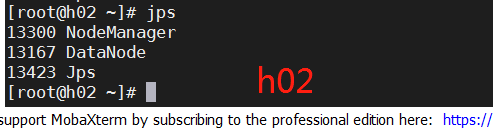
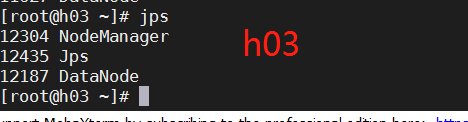
进入网页检查,打开网页输入192.168.228.101:50070(你自己的主机ip地址)-------成功

 输入192.168.228.101:8088------成功
输入192.168.228.101:8088------成功
















 9213
9213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









