







还是论文题目太长打不下了(SGG:场景图生成)

中心思想:p≈u-s-o
1.目标检测
2.视觉特征提取
出于对论文上下文的理解,我觉得这里的主客体特征应该融合了fasterrcnn提取的视觉特征和主客体的位置特征
3.谓语特征=union box特征-主语特征-宾语特征
4.谓语特征经过两层fc得到视觉模块的谓语类别的置信度
同时4’.谓语特征经过一层fc,主语和宾语分别做word embedding。
5.在三个连续的时间步内分别以主语特征、谓语特征、宾语特征为输入,得到它们的hidden state,再经过一层fc得到语言模块的谓语类别分数
6.最终三元组的分数:
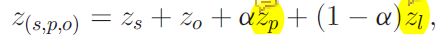
zs,zo:主客体的置信度
zp:视觉模块的置信度
zl:语言模块的置信度
---------------------------一些碎碎念---------------------------
没啥说的了。
大道至简就完事了。















 2666
2666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









