






孤立森林(Isolation Forest)算法是西瓜书作者周志华老师的团队研究开发的算法,一般用于结构化数据的异常检测。
异常的定义
针对于不同类型的异常,要用不同的算法来进行检测,而孤立森林算法主要针对的是连续型结构化数据中的异常点。
使用孤立森林的前提是,将异常点定义为那些 “容易被孤立的离群点” —— 可以理解为分布稀疏,且距离高密度群体较远的点。从统计学来看,在数据空间里,若一个区域内只有分布稀疏的点,表示数据点落在此区域的概率很低,因此可以认为这些区域的点是异常的。
-
异常数据占总样本量的比例很小;
-
异常点的特征值与正常点的差异很大。
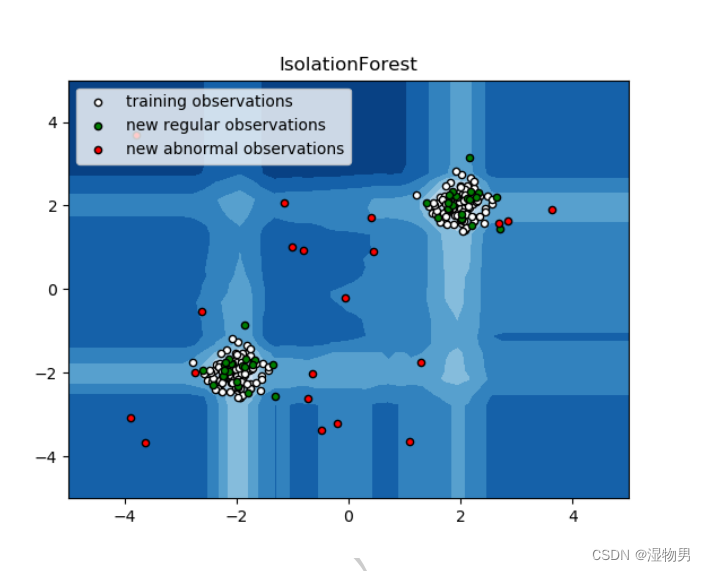
算法思想
想象这样一个场景,我们用一个随机超平面对一个数据空间进行切割,切一次可以生成两个子空间(也可以想象用刀切蛋糕)。接下来,我们再继续随机选取超平面,来切割第一步得到的两个子空间,以此循环下去,直到每子空间里面只包含一个数据点为止。
直观上来看,我们可以发现,那些密度很高的簇要被切很多次才会停止切割,即每个点都单独存在于一个子空间内,但那些分布稀疏的点,大都很早就停到一个子空间内了。
训练测试过程
- 单棵树的训练
-
从训练数据中随机选择 Ψ 个点作为子样本,放入一棵孤立树的根节点;
-
随机指定一个维度,在当前节点数据范围内,随机产生一个切割点 p —— 切割点产生于当前节点数据中指定维度的最大值与最小值之间;
-
此切割点的选取生成了一个超平面,将当前节点数据空间切分为2个子空间:把当前所选维度下小于 p 的点放在当前节点的左分支,把大于等于 p 的点放在当前节点的右分支;
-
在节点的左分支和右分支节点递归步骤 2、3,不断构造新的叶子节点,直到叶子节点上只有一个数据(无法再继续切割) 或树已经生长到了所设定的高度 。(至于为什么要对树的高度做限制,后续会解释)
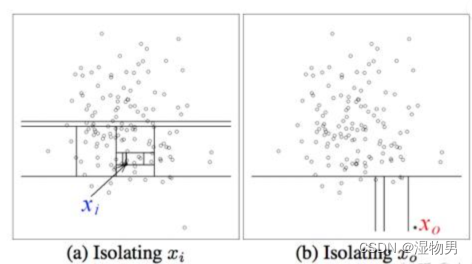
上图就是对子样本进行切割训练的过程,左图的 处于密度较高的区域,因此切割了十几次才被分到了单独的子空间,而右图的 落在边缘分布较稀疏的区域,只经历了四次切分就被 “孤立” 了。
- 整合全部孤立树的结果
由于切割过程是完全随机的,所以需要用 ensemble 的方法来使结果收敛,即反复从头开始切,然后计算每次切分结果的平均值。
获得 t 个孤立树后,单棵树的训练就结束了。接下来就可以用生成的孤立树来评估测试数据了,即计算异常分数 s。 对于每个样本 x,需要对其综合计算每棵树的结果,通过下面的公式计算异常得分:
s ( x , ψ ) = 2 − E ( h ( x ) ) c ( ψ ) s(x,\psi)=2^{-\frac{E(h(x))}{c(\psi)}} s(x,ψ)=2−c(ψ)E(h(x))
h(x) 为 x 在每棵树的高度,c(Ψ) 为给定样本数 Ψ 时路径长度的平均值,用来对样本 x 的路径长度 h(x) 进行标准化处理。
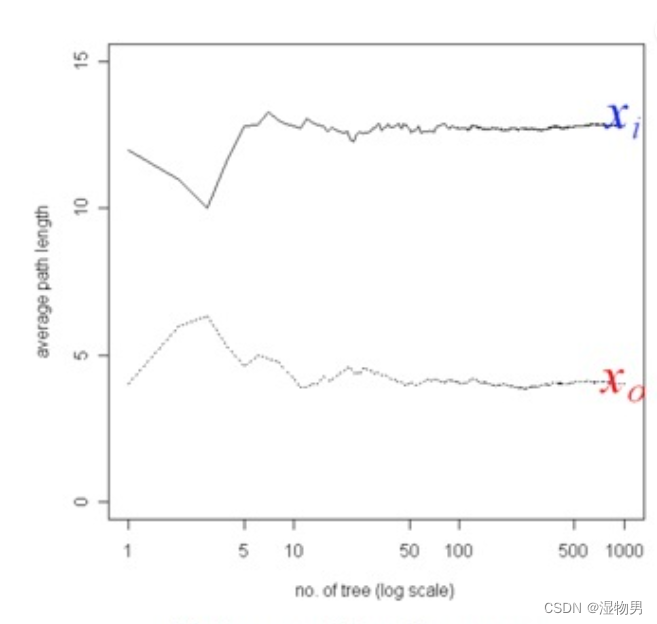
上图为孤立树的数目与每个样本点的平均高度的关系,可以看到数目选取在 10 以内时,结果非常不稳定,当数目达到 100 后就趋于收敛了。因此我们在使用过程中,树的棵树设置为 100 即可,如果棵树过少结果可能不稳定,若过多则白白浪费了系统开销。
- 异常得分
如果异常得分接近 1,那么一定是异常点;
如果异常得分远小于 0.5,那么一定不是异常点;
如果异常得分所有点的得分都在 0.5 左右,那么样本中很可能不存在异常点。















 2809
2809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











