






http://www.ai-start.com/dl2017/html/lesson4-week3.html
目标检测(Object detection)
目标定位(Object localization)

特征点检测(Landmark detection)
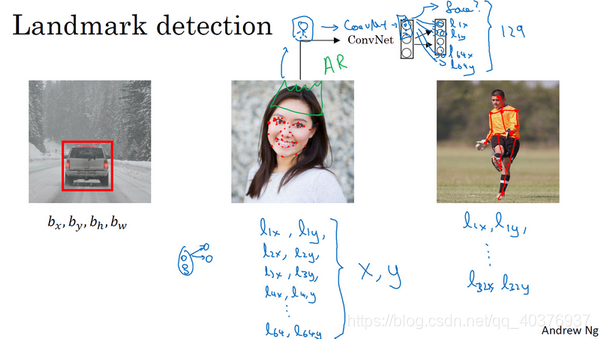
目标检测(Object detection)
滑动窗口目标检测
滑动窗口的卷积实现(Convolutional implementation of sliding windows)
掌握了卷积知识,我们再看看如何通过卷积实现滑动窗口对象检测算法。讲义中的内容借鉴了屏幕下方这篇关于OverFeat的论文,它的作者包括Pierre Sermanet,David Eigen,张翔,Michael Mathieu,Rob Fergus,Yann LeCun。

假设向滑动窗口卷积网络输入14×14×3的图片,为了简化演示和计算过程,这里我们依然用14×14的小图片。和前面一样,神经网络最后的输出层,即softmax单元的输出是1×1×4,我画得比较简单,严格来说,14×14×3应该是一个长方体,第二个10×10×16也是一个长方体,但为了方便,我只画了正面。所以,对于1×1×400的这个输出层,我也只画了它1×1的那一面,所以这里显示的都是平面图,而不是3D图像。
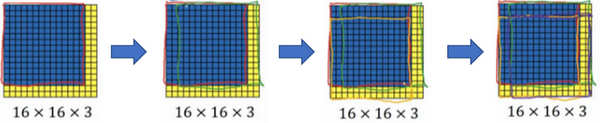
假设输入给卷积网络的图片大小是14×14×3,测试集图片是16×16×3,现在给这个输入图片加上黄色条块,在最初的滑动窗口算法中,你会把这片蓝色区域输入卷积网络(红色笔标记)生成0或1分类。接着滑动窗口,步幅为2个像素,向右滑动2个像素,将这个绿框区域输入给卷积网络,运行整个卷积网络,得到另外一个标签0或1。继续将这个橘色区域输入给卷积网络,卷积后得到另一个标签,最后对右下方的紫色区域进行最后一次卷积操作。我们在这个16×16×3的小图像上滑动窗口,卷积网络运行了4次,于是输出了了4个标签。

结果发现,这4次卷积操作中很多计算都是重复的。所以执行滑动窗口的卷积时使得卷积网络在这4次前向传播过程中共享很多计算,尤其是在这一步操作中(编号1),卷积网络运行同样的参数,使得相同的5×5×16过滤器进行卷积操作,得到12×12×16的输出层。然后执行同样的最大池化(编号2),输出结果6×6×16。照旧应用400个5×5的过滤器(编号3),得到一个2×2×400的输出层,现在输出层为2×2×400,而不是1×1×400。应用1×1过滤器(编号4)得到另一个2×2×400的输出层。再做一次全连接的操作(编号5),最终得到2×2×4的输出层,而不是1×1×4。最终,在输出层这4个子方块中,蓝色的是图像左上部分14×14的输出(红色箭头标识),右上角方块是图像右上部分(绿色箭头标识)的对应输出,左下角方块是输入层左下角(橘色箭头标识),也就是这个14×14区域经过卷积网络处理后的结果,同样,右下角这个方块是卷积网络处理输入层右下角14×14区域(紫色箭头标识)的结果。
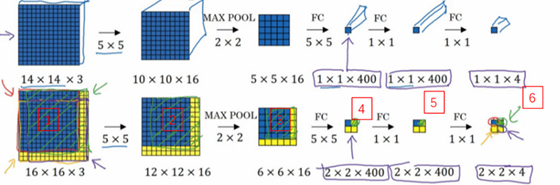
如果你想了解具体的计算步骤,以绿色方块为例,假设你剪切出这块区域(编号1),传递给卷积网络,第一层的激活值就是这块区域(编号2),最大池化后的下一层的激活值是这块区域(编号3),这块区域对应着后面几层输出的右上角方块(编号4,5,6)。
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算,就像这里我们看到的这个4个14×14的方块一样。
Bounding Box预测(Bounding box predictions)
交并比(Intersection over union)

非极大值抑制(Non-max suppression)
非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
Anchor Boxes

YOLO 算法(Putting it together: YOLO algorithm)
候选区域(选修)(Region proposals (Optional))

所以这个细节就是所谓的分割算法,你先找出可能2000多个色块,然后在这2000个色块上放置边界框,然后在这2000个色块上运行分类器,这样需要处理的位置可能要少的多,可以减少卷积网络分类器运行时间,比在图像所有位置运行一遍分类器要快。特别是这种情况,现在不仅是在方形区域(编号5)中运行卷积网络,我们还会在高高瘦瘦(编号6)的区域运行,尝试检测出行人,然后我们在很宽很胖的区域(编号7)运行,尝试检测出车辆,同时在各种尺度运行分类器。
这就是R-CNN或者区域CNN的特色概念,现在看来R-CNN算法还是很慢的。所以有一系列的研究工作去改进这个算法,所以基本的R-CNN算法是使用某种算法求出候选区域,然后对每个候选区域运行一下分类器,每个区域会输出一个标签,有没有车子?有没有行人?有没有摩托车?并输出一个边界框,这样你就能在确实存在对象的区域得到一个精确的边界框。
澄清一下,R-CNN算法不会直接信任输入的边界框,它也会输出一个边界框 b x b_{x} bx, b y b_{y} by, b h b_{h} bh和 b w b_{w} bw,这样得到的边界框比较精确,比单纯使用图像分割算法给出的色块边界要好,所以它可以得到相当精确的边界框。
现在R-CNN算法的一个缺点是太慢了,所以这些年来有一些对R-CNN算法的改进工作,Ross Girshik提出了快速的R-CNN算法,它基本上是R-CNN算法,不过用卷积实现了滑动窗法。最初的算法是逐一对区域分类的,所以快速R-CNN用的是滑动窗法的一个卷积实现,这和你在本周第四个视频(3.4 卷积的滑动窗口实现)中看到的大致相似,这显著提升了R-CNN的速度。














 3423
3423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









