






接上一节内容:Pytorch搭建常见分类网络模型------VGG、Googlenet、 MobileNetV3、ResNet50(1)_一只小小的土拨鼠的博客-CSDN博客
前言:AlexNet、VGG等经典的神经网络框架,一个共同特点是:整个网络由不同神经模块的串联构建。神经网络深度不断加深会造成过拟合和模型参数巨大等问题。解决主要方法是引入稀疏特性、将全连接层换成稀疏连接。Googlenet串并联网络结构便是由此提出。
在串联网络中,每一层级的卷积核都是固定尺寸的,只能提取固定尺度的特征。基于这种尺度单一的特征图构建的模型鲁棒性不强,泛化能力差。串联网络参数量巨大,难以将梯度传递到网络顶层。所以2015年串并联网络架构的 GoogLeNet 成为了当时的最佳模型。
3、各种模型的搭建
(1)Googlenet网络介绍
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
Googlenet提出了多尺度融合的网络结构,这种结构非常有意义。在目标检测领域应用非常广泛,目标检测的特征金字塔特征融合的方法和网络结构正是借鉴了googlenet的思想。
下图是googlenet网络inception模块的基本结构,可以看到它将一个输入分成多个分支进行不同的处理,然后再将不同的处理结果进行拼接,组成最后的多尺度融合输出结构。加入1*1的卷积结构用于降低模型的参数数量。
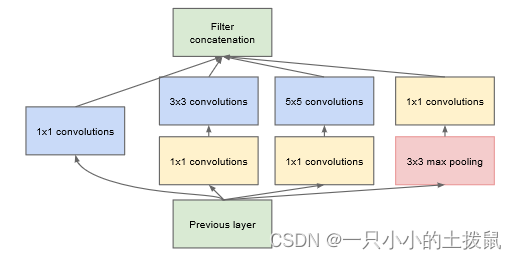
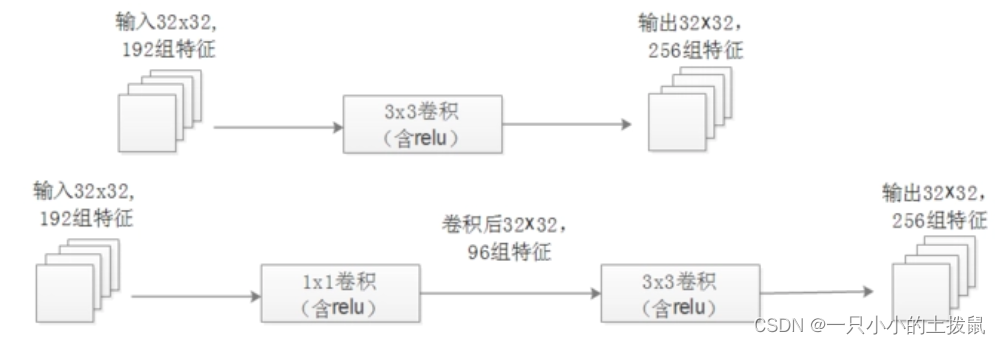
- 1x1卷积的作用:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。对于一个NIN结构,先进行一次普通的卷积(比如3x3),再进行一次1x1的卷积,对某个像素点来说1x1卷积等效于该像素点在所有特征上进行一次全连接的计算,所以1x1卷积相当于全连接层的形式。将两个卷积串联,就能组合出更多的非线性特征,从而在相同的感受野范围提取更强的非线性。使用1x1卷积进行降维,降低了计算复杂度。当某个卷积层输入的特征数较多,对这个输入进行卷积运算将产生巨大的计算量;如果对输入先进行降维,减少特征数后再做卷积计算量就会显着减少,从而节省计算量。 用1x1卷积降到96个特征后特征数减少,但只要最后输出的特征数不变,中间的降维类似于压缩的效果,并不影响最终训练的结果。
(上)192x256x3x3x32x32 (下)192x96x1x1x32x32+96x256x3x3x32x32
- 多个尺寸上进行卷积再聚合 ,可以看到对输入做了4个分支,分别用不同尺寸的卷积核进行卷积或池化,最后再在特征维度上拼接到一起。这种全新的结构的好处是:在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度,预先把相关性强的特征汇聚,就能起到加速收敛的作用。 在inception模块中有一个分支使用了max pooling,也能起到提取特征的作用。
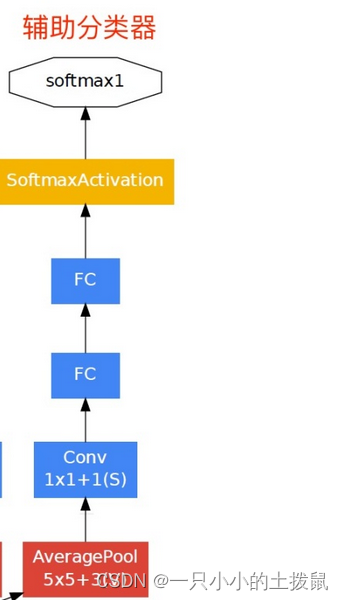
- googlenet的另一大创新点在于创造了多分类器,除了原来的主分类器之外,还增加了两个辅助分类器,这有点类似模型融合,不过模型融合是参与模型的最终决策的,但是他的两个辅助分类器并不参与最终决策,只是在训练总损失的时候,总损失 = 主分类器的损失 + 0.3*辅助分类器1 + 0.3*辅助分类器2。识别过程中并不参与,只取主分类器的结果,而且求解验证集损失的时候也不取辅助分类器的结果,因为验证过程中模型时关闭辅助分类器的。
GoogLeNet最基本的网络块是Inception,它是一个并联网络块,经过不断的迭代优化,发展出了Inception-v1、Inception-v2、Inception-v3、Inception-v4、Inception-ResNet共5个版本。具体的模型结构可参考:深度学习-GoogLeNet - 知乎
- Inception-v1将多尺度的卷积池化层提取的特征图拼接输入下一层,提升模型多尺度特征提取
- 能力Inception-v2将Inception-v1中的大尺寸卷积核替换为多个小尺寸卷积核的堆叠,减少模型参数量,增加网络深度,提升模型拟合复杂分布的能力。对卷积层进行BatchNormalizatioin,有效地加速了网络训练过程,也能够消除梯度弥散。还=引入了辅助分类器,来解决梯度无法反向传递非常深的问题。
- Inception-v3主要进行了以下改进:优化算法使用RMSProp替代SGD。使用Label Smoothing Regularization方法,LSR是一种通过在输出y中加入噪声,对模型进行约束,降低模型过拟合的方法。将大尺寸卷积核替换成小尺寸卷积核。对辅助分类器中的全连接层进行BatchNormalization。
- Inception-v4基本沿袭了Inception-v2/v3的设计,它的各个模块在结构上更加统一。
- Inception-ResNet借鉴了何凯明的残差连接思想,残差连接是指浅层特征通过另外一条支路直接加到高层特征中,达到特征复用的目的,可以有效避免深层网络的梯度弥散问题。
网络结构图: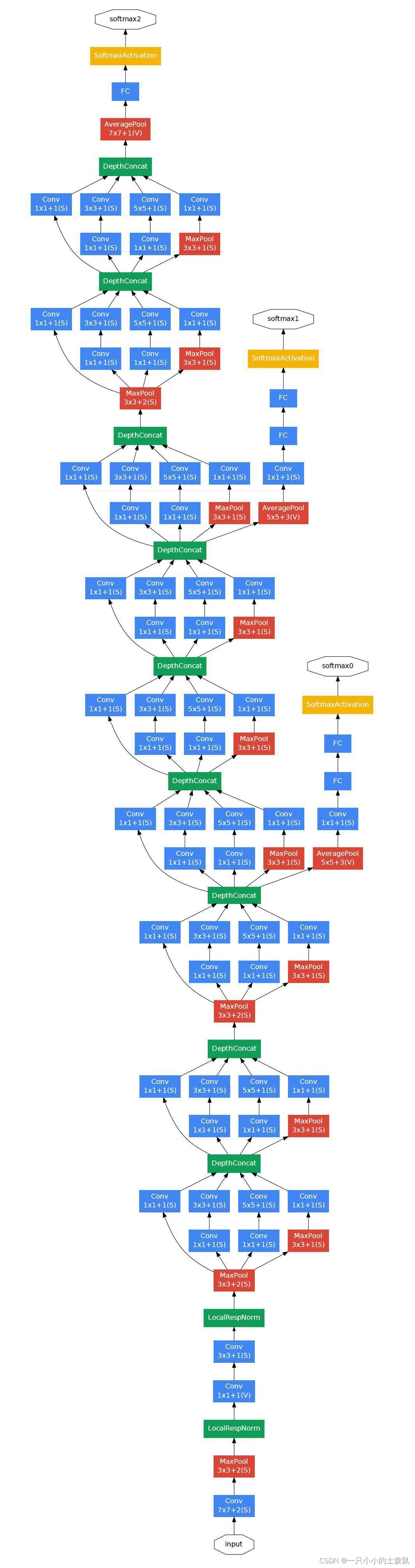
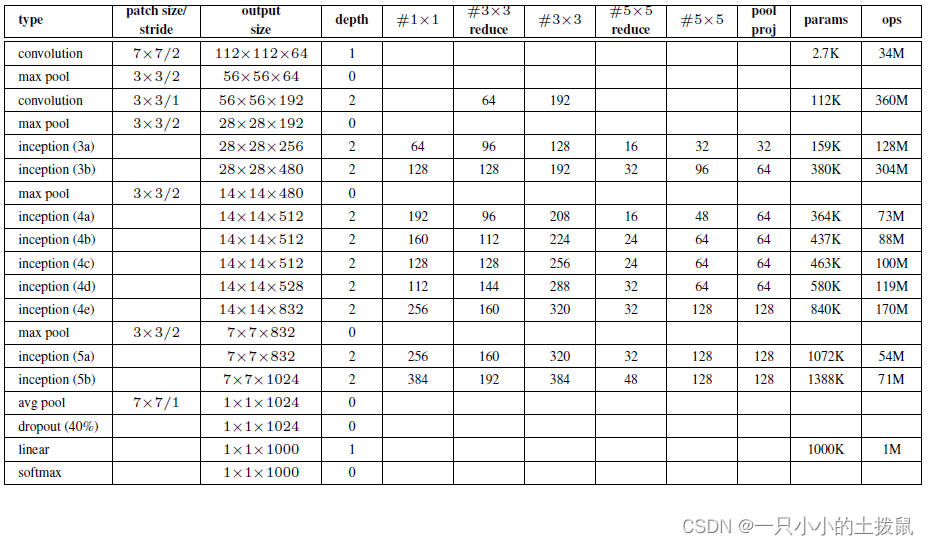
(2) Googlenet网络模型搭建
class GoogLeNet(nn.Module):
def __init__(self, num_classes=10, aux_logits=True,
init_weights=False): # 这是主分类器 aux_logits是true则启动使用辅助分类器,否则不启动
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits: # 是否启用辅助分类器
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights: # 是否使用初始化权重
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer# eval model lose this layer 如果为训练模型则使用辅助分类器,验证模型则关闭辅助分类器
return x, aux2, aux1
return x
def _initialize_weights(self): # 初始化权重的提房,有兴趣可以查查函数看看
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
class Inception(nn.Module): # 搭建多分支架构的一部分
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,
pool_proj): # self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 保证输出大小等于输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module): # 辅助分类器结构
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
googlenet = GoogLeNet(num_classes=10, aux_logits=True, init_weights=True) # 启动模型,这里的7就改成自己的数据集的种类即可,几种就改成几
print(googlenet) # 打印出模型结构看看
googlenet.to(device) # 将模型放到GPU上
test1 = torch.ones(64, 3, 224, 224) # 输出一个测试数据看看模型的数据是几种的,是不是我们需要的种类
test1_1, test_2, test_3 = googlenet(test1.to(device)) # 会输出三个分类器的结果,我们查看主分类器的输出最后是不是我们的种类数
print(test1_1.shape)
epoch = 4 # 迭代次数即训练次数
learning = 0.001 # 学习率
optimizer = torch.optim.Adam(googlenet.parameters(), lr=learning) # 使用Adam优化器-写论文的话可以具体查一下这个优化器的原理
loss = nn.CrossEntropyLoss() # 损失计算方式,交叉熵损失函数
train_loss_all = [] # 存放训练集损失的数组
train_accur_all = [] # 存放训练集准确率的数组
test_loss_all = [] # 存放测试集损失的数组
test_accur_all = [] # 存放测试集准确率的数组
for i in range(epoch): # 开始迭代
train_loss = 0 # 训练集的损失初始设为0
train_num = 0.0
train_accuracy = 0.0 # 训练集的准确率初始设为0
googlenet.train() # 将模型设置成 训练模式,这里意味着启动辅助分类器
train_bar = tqdm(traindata) # 用于进度条显示,没啥实际用处
for step, data in enumerate(train_bar): # 开始迭代跑, enumerate这个函数不懂可以查查,将训练集分为 data是序号,data是数据
img, target = data # 将data 分为 img图片,target标签
optimizer.zero_grad() # 清空历史梯度
outputs_1 = googlenet(img.to(device)) # 将图片打入网络进行训练,outputs是输出的结果
outputs, outputs1, outputs2 = outputs_1 # 因为googlenet有两个辅助分类器,所以会有三个分类结果
loss1 = loss(outputs, target.to(device)) # 第一个为主分类器的损失
loss1_1 = loss(outputs1, target.to(device)) # 第二个是辅助分类器1的损失
loss1_2 = loss(outputs2, target.to(device)) # 第三个是辅助分类器2的损失
loss1_fin = loss1 + loss1_1 * 0.3 + loss1_2 * 0.3 # 计算总损失
outputs = torch.argmax(outputs, 1) # 计算准确率的时候 只是用主分类器的结果,辅助分类器只用来反向传播,防止梯度消失重点,牢记
loss1_fin.backward() # 神经网络反向传播
optimizer.step() # 梯度优化 用上面的abam优化
train_loss += abs(loss1_fin.item()) * img.size(0) # 将所有损失的绝对值加起来
accuracy = torch.sum(outputs == target.to(device)) # outputs == target的 即使预测正确的,统计预测正确的个数,从而计算准确率
train_accuracy = train_accuracy + accuracy # 求训练集的准确率
train_num += img.size(0)
print("epoch:{} , train-Loss:{} , train-accuracy:{}".format(i + 1, train_loss / train_num,
train_accuracy / train_num)) # 输出训练情况
train_loss_all.append(train_loss / train_num) # 将训练的损失放到一个列表里 方便后续画图
train_accur_all.append(train_accuracy.double().item() / train_num) # 训练集的准确率
test_loss = 0 # 同上 测试损失
test_accuracy = 0.0 # 测试准确率
test_num = 0
googlenet.eval() # 测试模式启动,关闭辅助分类器
with torch.no_grad(): # 清空历史梯度,进行测试 与训练最大的区别是测试过程中取消了反向传播
test_bar = tqdm(testdata)
for data in test_bar:
img, target = data
outputs_1 = googlenet(img.to(device)) # 这个时候模型只有一个输出结果,因为关闭了辅助分类器
loss2 = loss(outputs_1, target.to(device))
outputs_1 = torch.argmax(outputs_1, 1)
test_loss = test_loss + abs(loss2.item()) * img.size(0)
accuracy = torch.sum(outputs_1 == target.to(device))
test_accuracy = test_accuracy + accuracy
test_num += img.size(0)
print("test-Loss:{} , test-accuracy:{}".format(test_loss / test_num, test_accuracy / test_num))
test_loss_all.append(test_loss / test_num)
test_accur_all.append(test_accuracy.double().item() / test_num)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(range(epoch), train_loss_all,
"ro-", label="Train loss")
plt.plot(range(epoch), test_loss_all,
"bs-", label="test loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(range(epoch), train_accur_all,
"ro-", label="Train accur")
plt.plot(range(epoch), test_accur_all,
"bs-", label="test accur")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
torch.save(googlenet.state_dict(), "googlenet.pth") # 保存模型
print("模型已保存")分析一下inception结构:
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
class Inception(nn.Module): # 搭建多分支架构的一部分
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,
pool_proj): # self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1))# 保证输出大小等于输入大小
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2)) # 保证输出大小等于输入大小
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1))
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)#将多个张量(tensor)在第二维度拼接在一起,组成一个融合维度的张量对于一个 Inception(192, 64, 96, 128, 16, 32, 32) 的结构来说,它的各部分参数分别是
(in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5,pool_proj)其中参数依次代表:
输入特征维度、1*1卷积的输出特征维度,3*3卷积之前的1*1卷积的输出特征维度、3*3卷积的输出特征维度、5*5卷积之前的1*1卷积的输出特征维度、5*5卷积的输出特征维度。对于一个(32、192、28、28)的张量数据来说,他将经历以下变换:
- branch1:输入的数据经过一个卷积核大小为1,步距为1,输出维度为64的卷积层,并通过一个激活函数。返回一个形状为(32、64、28、28)张量数据。
- branch2:输入的数据经过一个卷积核大小为1,步距为1,输出维度为96的卷积层,(激活)在通过一个卷积核大小为3,步距为1,补零为1,输出维度为128的卷积层。(激活)返回一个形状为(32、128、28、28)张量数据。(w-f+2p)/s+1=28,所以图像大小不变。
- branch3:输入的数据经过一个卷积核大小为1,步距为1,输出维度为16的卷积层,(激活)在通过一个卷积核大小为5,步距为1,补零为2,输出维度为32的卷积层。(激活)返回一个形状为(32、32、28、28)张量数据。(w-f+2p)/s+1=28,所以图像大小不变。
- branch4:输入的数据经过一个卷积核大小为3,步距为1,补零为1的最大池化层,张量数据形状不变。在通过一个卷积核大小为1,步距为1,输出维度为32的卷积层。(激活)返回一个形状为(32、32、28、28)张量数据。
- return torch.cat(outputs, 1):将branch1, branch2, branch3, branch4输出的张量数据在第一维度上进行拼接,可以得到并返回一个形状为(32、256、28、28)张量数据。
分析一下InceptionAux结构:
if self.aux_logits: # 是否启用辅助分类器
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
class InceptionAux(nn.Module): # 辅助分类器结构
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)#(14-5)/3+1=4
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024) #
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)#2048
x = F.dropout(x, 0.5, training=self.training)#只在训练的时候开启
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
对于一个 InceptionAux(512, num_classes) 的结构来说,它的各部分参数分别是
(in_channels, num_classes),对于一个形状为(32、512、14、14)的张量数据来说,他将经历以下变换:
- 输入的数据经过一个卷积核大小为5,步距为3的最大池化层,张量数据形状变为(32、512、4、4)。
- 在通过一个卷积核大小为1,步距为1,输出维度为128的卷积层。(激活)返回一个形状为(32、128、4、4)张量数据。
- 从第一维度开始进行展平处理,变为形状为(32、2048)的张量数据,并经一个随机失活函数。
- 将输出的数据经过第一个全连接层,变成维度为1024,并通过一个激活函数。(32,1024)
- 将输出的数据经过第一个全连接层,变成维度为num_classes。返回最终的张量数据。(32,并通过一个激活函数。(32,num_classes)。
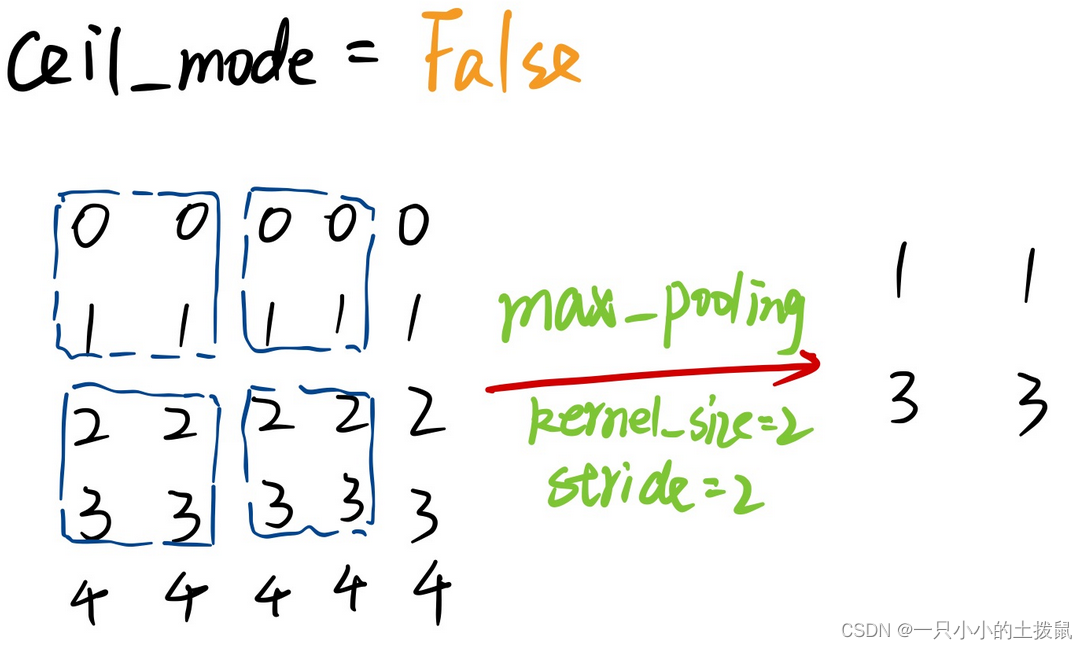
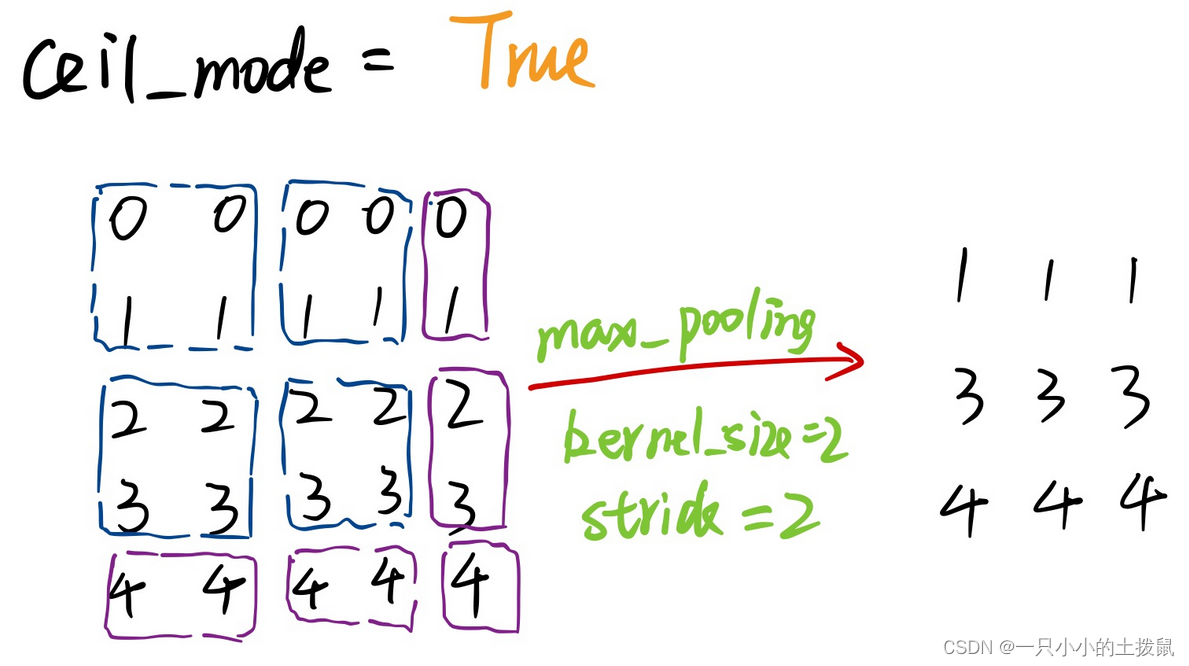
Pytorch中的maxpool的ceil_mode 当为True时,将用向上取整的值代替浮点数作为输出尺寸。 所以ceil模式就是会把不足square_size的边给保留下来,单独另算,而floor模式则是直接把不足square_size的边给舍弃了。类似math库中的ceil和floor的函数向上取整或者向下取整 。
torch.cat()函数的详解:在给定维度上对输入的张量序列seq 进行连接操作。
outputs = torch.cat(inputs, dim=2) 其中inputs : 输入数据必须是序列,序列中数据是任意相同的shape的同类型张量。dim : 选择的扩维, 必须在 0到 outputs的维度值之间,沿着此维连接张量序列。 使用torch.cat((A,B),dim)时,除拼接维数dim数值可不同外其余维数需相同,才能对齐
x1 = torch.tensor([[11,21,31],
[21,31,41]],dtype=torch.int)
x2 = torch.tensor([[12,22,32],
[22,32,42]],dtype=torch.int)
'inputs为2个形状为[2 , 3]的矩阵 '
inputs = [x1, x2]
print(torch.cat(inputs, dim=0).shape)
print(torch.cat(inputs, dim=0))
print(torch.cat(inputs, dim=1).shape)
print(torch.cat(inputs, dim=1))输出结果:
torch.Size([4, 3])
tensor([[11, 21, 31],
[21, 31, 41],
[12, 22, 32],
[22, 32, 42]], dtype=torch.int32)
torch.Size([2, 6])
tensor([[11, 21, 31, 12, 22, 32],
[21, 31, 41, 22, 32, 42]], dtype=torch.int32)torch.argmax(input, dim=None) 用法的理解,返回的就是最大数的索引 。参数 dim可以指定函数返回不同维的最大值。就是把dim这个维度,变成这个维度的最大值的index。 对一个一维向量 :
import numpy as np
a = np.array([3, 1, 2, 4, 6, 1])
b=np.argmax(a)#取出a中元素最大值所对应的索引,此时最大值位6,其对应的位置索引值为4,(索引值默认从0开始)
print(b)#4在dim=0表示二维矩阵中的列,dim=1在二维矩阵中的行。
import numpy as np
a = np.array([[1, 5, 5, 2],
[9, 6, 2, 8],
[3, 7, 9, 1]])
b=np.argmax(a, axis=0)#对二维矩阵来讲a[0][1]会有两个索引方向,第一个方向为a[0],默认按列方向搜索最大值
#a的第一列为1,9,3,最大值为9,所在位置为1,a的第一列为5,6,7,最大值为7,所在位置为2,
print(b)#[1 2 2 1]
c=np.argmax(a, axis=1)#现在按照a[0][1]中的a[1]方向,即行方向搜索最大值,
#a的第一行为1,5,5,2,最大值为5(虽然有2个5,但取第一个5所在的位置),索引值为1,
#a的第2行为9,6,2,8,最大值为9,索引值为0,
print(c)#[1 0 2]网络里面RELU激活函数中的inplace的含义是是否进行覆盖运算。即改变一个tensor的值的时候,不经过复制操作,而是直接在原来的内存上改变它的值 。inplace=True的意思是进行原地操作, 例如x=x+5,对x 就是 一个原地操作,是对于Conv2d这样的上层网络传递下来的tensor 直接进行修改 ,好处就是可以节省运算内存,不用多储存变量y。 有时可以稍微减少内存使用量,但可能并不总是有效的操作(因为原始输入已被破坏)。
import torch
import torch.nn as nn
my_conv1 = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1)
my_relu = nn.ReLU(inplace=True)
my_conv2 = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1)
x = torch.rand(1,2,3,4)
x1 = my_conv1(x)
h = my_relu(x1)
y = my_conv2(x1)这样做就是有问题的。因为在x1在经过my_relu之后,其值经过改变,现在其值相当于h。所以 y = my_conv2(x1)在这里,其实相当于y=my_conv2(h)。这样得到的结果就不是我们预期的了。
GoogLeNet其他版本
上面介绍的GoogLeNet模型是Inception v1版本,还有Inception v2,v3,v4版本
Inception V2
(1)学习VGGNet的特点,用两个33卷积代替55卷积,可以降低参数量。
(2)提出BN算法。BN算法是一个正则化方法,可以提高大网络的收敛速度。就是每一batch的输入分布标准化处理,使得规范化为N(0,1)的高斯分布,收敛速度大大提高。
【深度学习】GoogLeNet系列解读 —— Inception v2_z小白的博客-CSDN博客_inception v2
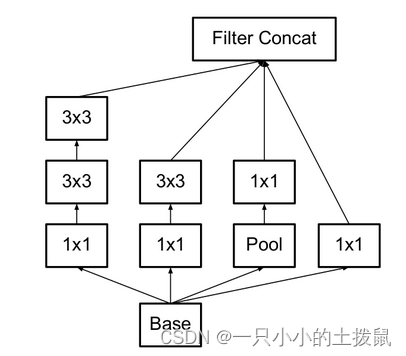
Inception V3
在Inception V2的基础上,将一个二维卷积拆分成两个较小卷积,例如将7*7卷积拆成1*7卷积和7*1卷积,这样做的好处是降低参数量。通过这种非对称的卷积拆分比对称的拆分为几个相同的小卷积效果更好,可以处理更多,更丰富的空间特征,这就是Inception V3网络结构。
整体上采用了Inception v2的网络结构,并在优化算法、正则化等方面做了改进,总结如下:
1. 优化算法使用RMSProp替代SGD。
2. 使用Label Smoothing Regularization(LSR)方法。LSR是一种通过在输出y中加噪声,实现对模型进行约束,降低模型过拟合的方法。
3. 将第一个7x7卷积层分解为两个3x3卷积层。
4. 辅助分类器(auxiliary classifier)的全连接层也进行了batch-normalization操作。
【深度学习】GoogLeNet系列解读 —— Inception v3_z小白的博客-CSDN博客

Inception V4
Inception v4中基本的Inception module还是沿袭了Inception v2/v3的结构,只是结构看起来更加简洁统一,并且使用更多的Inception module,实验效果也更好。
【深度学习】GoogLeNet系列解读 —— Inception v4_z小白的博客-CSDN博客_inception v4
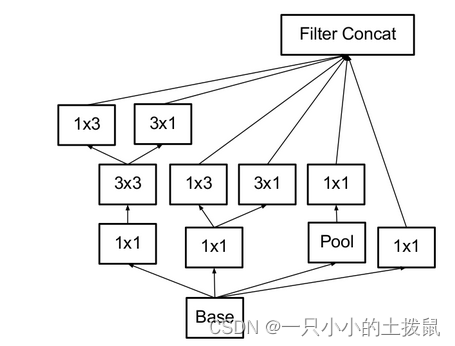
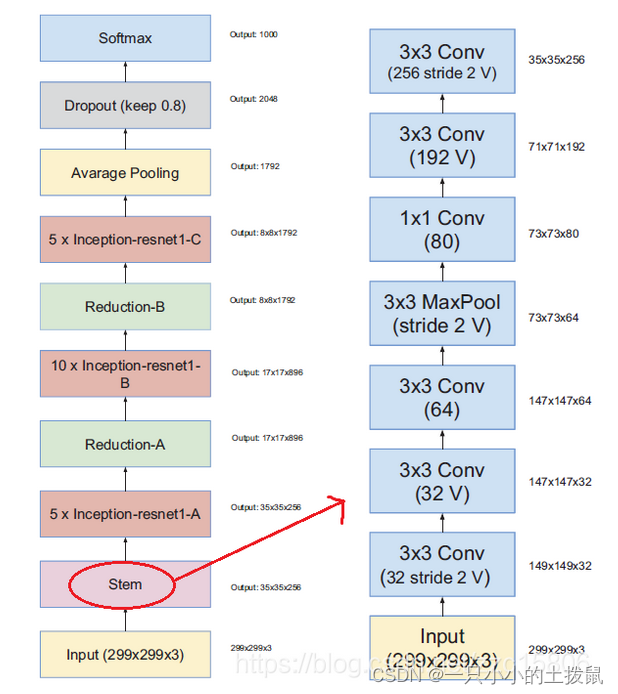
Inception-Resnet-v1和Inception-Resnet-v2
【深度学习】GoogLeNet系列解读 —— Inception v4_z小白的博客-CSDN博客_inception v4
残差连接是指浅层特征通过另外一条分支加到高层特征中,达到特征复用的目的,同时也避免深层网路的梯度弥散问题。
1. Inception module都是简化版,没有使用那么多的分支,因为identity部分(直接相连的线)本身包含丰富的特征信息;
2. Inception module每个分支都没有使用pooling;
3. 每个Inception module最后都使用了一个1x1的卷积(linear activation),作用是保证identity部分和Inception部分输出特征维度相同,这样才能保证两部分特征能够相加。

















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











