









一、ArrayList
1.底层基本数据结构:Object数组
transient Object[] elementData;
2.ArrayList初始化容量
由于ArrayList底层是基于数组的,因此在初始化时需要制定数组的初始化容量,ArrayList可以通过构造函数指定初始容量,如果不指定则默认初始容量为10,需要注意的是,当是默认容量的时候,创建一个ArrayList后,不会马上将底层Object数据初始化成10,而是指定成一个空数组。
无参构造器源码如下:
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
3.ArrayList的扩容
我们知道使用ArrayList可以不需要考虑其容量限制的往集合中加入数据,其实现原理是每次add数据的时候都会检查list的大小(size)是否超过容量,如果超过容量则会进行扩容操作。其扩容源码如下:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//右移一位相当于除以2
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以看到,如果原容量是10,则扩容后的容量为10+10/2=15,在确定了newCapacity后,会将原elementData数组中的数据通过调用Arrays.copyOf方法复制到容量为newCapacity的数组中,并且把新数组的引用赋值给elementData。由于在扩容中需要复制数据,因此如果在数据量大的时候,也是比较耗时的。
4.ArrayList的add(index,elem)插入操作
由于ArrayList底层是基于Object数组来存储数据,因此在往指定下标中插入一个数据时需要先将当前下标之后的数据一次后移一个位置,ArrayList中采用复制的方式,将(index,size-1)区间的数据复制到(index+1,size)区间。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
由于该操作需要进行数据复制,因此在数据量大,插入操作频繁的场景中使用ArrayList是比较耗时的。
5.ArrayList的remove(index)删除操作
和插入操作同样的道理,在删除某个index下的数据时,需要将(index+1,size-1)之间的数据向前依次移动一个位置,ArrayList采用复制的方式完成,即将(index+1,size-1)区间的值,复制到(index,size-2)之间,并将size-1下标对应的值设置成null。核心代码如下:
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
番外篇:注意到elementData[–size] = null后边的注释‘clear to let GC do its work’,大概意思是说‘明确让GC开展工作’,那为什么将引用设置成null会明确让GC开展工作呢? 这其实是将size-1下标对应的引用设置成null使其不再指向原来的值,则通过根可达性算法(GC Root)可以将size-1下标中的原有值判定为垃圾,然后又垃圾回收器回收。
6.ArrayList是否适合做队列?数组呢?
ArrayList不适合做队列,队列是一种FIFO的数据接口,那么如果使用ArrayList作为队列的话,就需要在数组尾部追加数据,数组头部删除数组,反过来也可以。但是无论如何总会有一个操作会涉及到数组的数据搬迁,这个是比较耗费性能的。
定长数组是比较适合作为队列的,我们可以使用双标记位来分别标记队头和队尾,如果到达数组边界则可以折回,充分利用存储空间,具体实现可看另一篇文章。
二、LinkedList
1.底层基本数据结构:双向链表
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2.LinkedList由于底层是基于双向链表的,因此不需要指定初始化容量,并且不存在扩容机制。
3.LinkedList的add(index,elem)方法
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
由于LinkedList中记录了链表中最后一个元素的引用,因此如果是在最后一个元素出插入新数据,则不需要遍历整个链表,则直接可以执行linkLast方法进行插入,这在数据量大得时候可以显著提升速度。
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
如果不是最后元素处插入数据,则需要从链表头部开始遍历到指定下标的节点处,我们看一下遍历的源码:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
整个遍历的设计思路是,如果index<size/2那么则从第一个节点开始向后遍历,如过index>=size/2则从最后一个节点开始向前遍历,这种设计思想在数据量大得情况下可以说是极大的降低了遍历时间。
当遍历到指定下标处的节点succ时,则进行链表的插入操作,链表的插入操作,逻辑很简单,不再赘述:
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
4.LinkedList的remove(index)方法
remove方法,删除指定位置上的元素,和add方法一样也同样需要调用node方法来遍历到指定下边处的节点,然后进行链表节点的删除操作。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
三、对比ArrayList和LinkedList
由于ArrayList和LinkedList底层数据结构
由于ArrayList和LinkedList底层数据结构不同,导致了ArrayList和LinkedList在存取速度、使用场景上有所差异,我们通过实现来比较一下ArrayList和LinkedList头插、中间插入、尾部插入的性能。
分别对10 0000,100 0000,1000 0000条数据进行插入操作。
1.头插
public static void main( String[] args ) throws InterruptedException {
ArrayList<Integer> list = new ArrayList<Integer>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list.add(0, i);
}
System.out.println("ArrayList耗时: " + (System.currentTimeMillis() - startTime));
LinkedList<Integer> list1 = new LinkedList<Integer>();
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
list1.addFirst(i);
}
System.out.println("LinkedList耗时: " + (System.currentTimeMillis() - startTime1));
}

如坐标图所示,在头插的场景中ArrayList的性能远远低于LinkedList,这是由于头部插入式ArrayList需要进行大量的数据复制操作,而LinkedList只需要节点的next、prev字段的赋值操作,因此如果你的场景中存在大量的头部插入数据操作,考虑使用LinkedList。
2.尾插
public static void main( String[] args ) throws InterruptedException {
ArrayList<Integer> list = new ArrayList<Integer>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.add(i);
}
System.out.println("ArrayList耗时: " + (System.currentTimeMillis() - startTime));
LinkedList<Integer> list1 = new LinkedList<Integer>();
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list1.addLast(i);
}
System.out.println("LinkedList耗时: " + (System.currentTimeMillis() - startTime1));
}
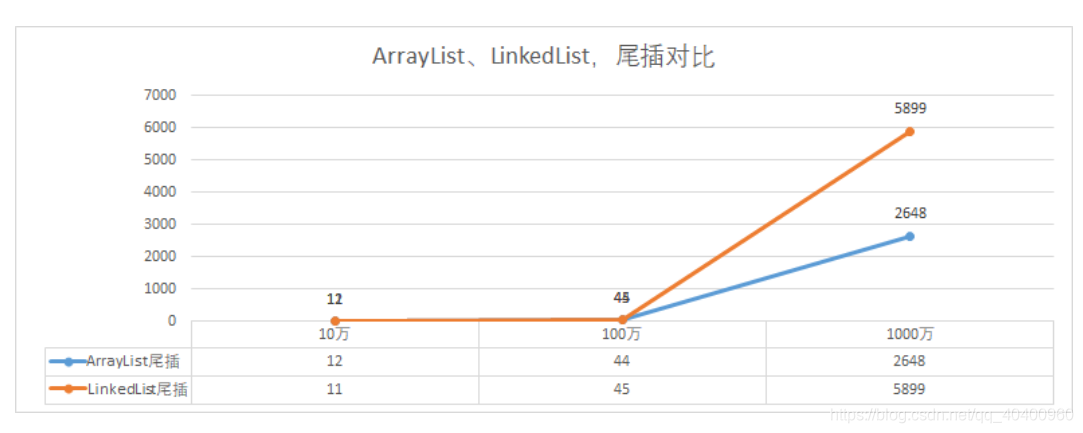
如图所见,在大量的尾部插入操作的场景中,ArrayList的整体性能比LinkedList的性能好,这是因为尾部插入时ArrayList不存在大量数据复制操作,相较而言LinkedList需要大量创建node以及next、prev操作,因此在大量尾部插入操作的场景中更适合使用ArrayList。
3.中间插入
public static void main( String[] args ) throws InterruptedException {
ArrayList<Integer> list = new ArrayList<Integer>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list.add(list.size()>>1,i);
}
System.out.println("ArrayList耗时: " + (System.currentTimeMillis() - startTime));
LinkedList<Integer> list1 = new LinkedList<Integer>();
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
list1.add(list1.size()>>1,i);
}
System.out.println("LinkedList耗时: " + (System.currentTimeMillis() - startTime1));
}
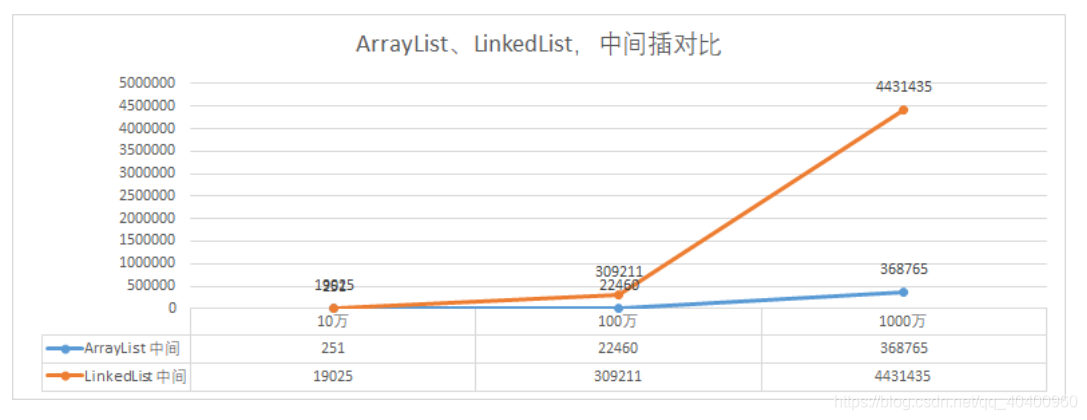
如图所见,在存在大量中间插入操作的场景中,ArrayList比LinkedList的性能更好一些,这是因为虽然ArrayList需要进行大量的数据复制操作,但是LinkedList也需要进行大量的遍历寻找目标节点,这在数据量比较大的情况下也是非常耗时的。















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











