







变分推断是近年来深度学习中一个非常重要的技术手段。推断困难通常是指难以计算p(h|v)或其期望,其中v指的是模型的可观测变量,而h表示隐藏变量。在深度神经网络中,多层的隐藏变量之间联系复杂,无法通过一个具体地概率密度函数来刻画隐藏变量的实际分布情况。即使对于单层的稀疏编码器,倘若隐变量之间没有相关的独立性假设,其内部隐藏单元的概率分布密度函数也是很难刻画的,原因是当输出变量被观测时,其对应的隐藏变量之间遍搭建起了联系(这是结构化概率模型中的一个重要性质:假设A变量可推导出C变量,B变量可推倒C变量,当C变量不可观测即不知道是否发生时,变量A与B可视为时相互独立的,而变量C一旦被观测则使得变量A、B之间搭建起了依赖关系。
变分推断的前提基础是近似推断,由于直接计算p(h|v)难度非常大,我们可以将传统的极大对数似然logp(v;θ)转化为求其下界的问题,通过引入另一个简单的概率密度分布函数q(h|v)来极大化logp(v;θ)的下界。衡量logp(v;θ)与其下界的标准是KL散度(关于KL散度的理解可参考[1]):
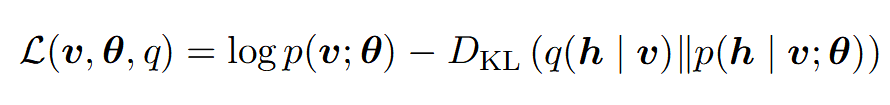
更为具体地,L可进一步化简得:
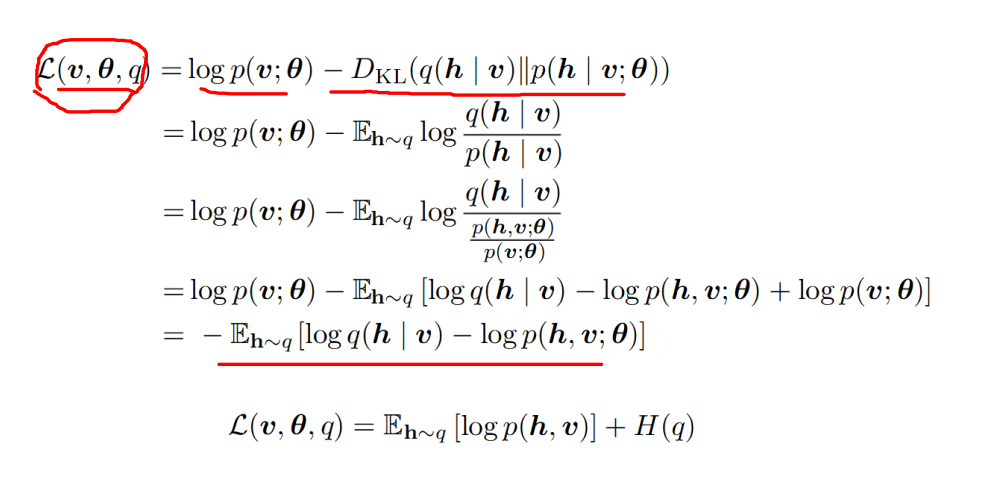
变分推断的核心思想就是在关于q的有约束的分布簇上最大化L。一个非常常用的变分学习的方法是加入一些限制使得q是一个因子分布(也就mean-field均值场方法):
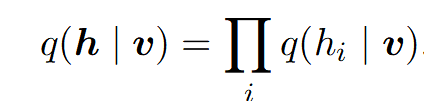
进而对L进行进一步化简得到(详细推导可见[2]):
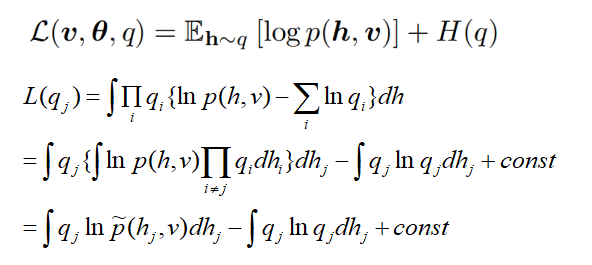
于是最大化L的上界,即最小化散度:
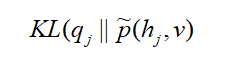
因此可得到q的迭代更新公式:
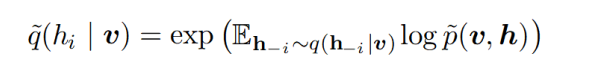
这就是均值场下的变分推断方法。
[1] https://blog.csdn.net/qq_40406773/article/details/80630280
[2] https://www.aliyun.com/jiaocheng/441651.html















 1750
1750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









