







目录
1.引言与背景
随着大数据时代的到来,机器学习在诸多领域展现出强大的预测与决策能力,其核心任务之一便是对复杂数据分布的建模与推断。然而,对于许多现实世界中的模型,尤其是那些具有高维度、非线性特性和隐变量的模型,直接计算后验概率分布往往极其困难甚至不可行。变分推断(Variational Inference, VI)作为一种有效的近似推断方法,通过构造易于处理的变分分布来近似难以直接计算的后验分布,从而克服了传统精确推断方法在大规模、复杂模型中的局限性。本文旨在系统地介绍变分推断算法的理论基础、算法原理、实现细节、优缺点、应用案例、与其他推断方法的对比,以及对其未来发展的展望。
2. 变分推断定理
变分推断的核心依据是变分原理,该原理指出对于任何概率分布,其与目标后验分布
之间的KL散度
可以被重新表述为一个优化问题:
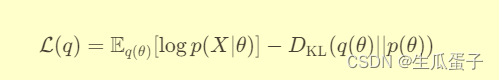
其中被称为证据下界(Evidence Lower Bound, ELBO),是KL散度的负值加上观测数据对数似然的期望。变分推断的目标是通过最大化ELBO来寻找最优变分分布
,使得它尽可能接近真实的后验分布
。这一过程转化为一个优化问题,而非求解复杂的积分问题,大大降低了计算复杂度。
3. 算法原理
变分推断的基本流程包括以下四个步骤:
a. 变分家族选择 首先,需要选取一个包含简单分布的变分族,如高斯分布、狄利克雷分布、指数族分布等,它们应具有封闭形式的解析表达和易于优化的特性。
b. 构建ELBO 基于所选变分族,构建对应的ELBO函数,其中包含两部分:一是观测数据对数似然期望,可通过采样或近似积分得到;二是KL散度,对于常见的变分族和先验分布,通常可以得到封闭形式的表达。
c. 优化ELBO 利用梯度上升或其他优化算法(如Adam、牛顿法等)最大化ELBO,更新变分参数,不断逼近最优变分分布。这一步通常涉及对变分分布参数的梯度计算,对于连续变量,可借助自动微分工具如PyTorch或TensorFlow实现。
d. 后验推断 优化完成后,最优变分分布被视为真实后验分布
的近似。从中可以提取点估计(如均值)、不确定性量化(如方差、 credible intervals)、模式探索(如边际分布)等信息,服务于后续的预测、决策或模型解释。
4. 算法实现
为了展示一个简单的Python实现变分推断的例子,我们将聚焦于使用变分自编码器(Variational Autoencoder, VAE)这一特定的框架。VAE是一种广泛应用的深度学习模型,它利用变分推断来学习数据的潜在表示(即隐变量)和相应的生成模型。以下是使用PyTorch实现VAE的代码及其详细讲解:
Python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Normal
# 定义编码器(Encoder)网络
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_mean = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
mean = self.fc_mean(x)
logvar = self.fc_logvar(x)
return mean, logvar
# 定义解码器(Decoder)网络
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super().__init__()
self.fc1 = nn.Linear(latent_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc_out = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
z = torch.relu(self.fc1(z))
z = torch.relu(self.fc2(z))
out = torch.sigmoid(self.fc_out(z))
return out
# 定义VAE模型
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super().__init__()
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
def reparameterize(self, mean, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mean + eps * std
def forward(self, x):
mean, logvar = self.encoder(x)
z = self.reparameterize(mean, logvar) # 采样隐变量z
recon_x = self.decoder(z)
return recon_x, mean, logvar
# 设置模型参数
input_dim = 784 # 假设输入数据为MNIST图像(28x28像素)
hidden_dim = 400
latent_dim = 20
# 创建VAE实例
vae = VAE(input_dim, hidden_dim, latent_dim)
# 定义损失函数(重构损失+KL散度惩罚项)
def loss_function(recon_x, x, mean, logvar):
BCE = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum') # 二元交叉熵损失
KLD = -0.5 * torch.sum(1 + logvar - mean.pow(2) - logvar.exp()) # KL散度惩罚项
return BCE + KLD
# 训练循环(简化版,仅作示例)
optimizer = optim.Adam(vae.parameters(), lr=1e-3)
for epoch in range(num_epochs):
for batch_idx, (data, _) in enumerate(train_loader): # 假设使用数据加载器加载批量数据
data = data.view(-1, input_dim).to(device) # 调整数据形状并转移到设备(如GPU)
optimizer.zero_grad() # 清除梯度缓存
recon_x, mean, logvar = vae(data) # 前向传播
loss = loss_function(recon_x, data, mean, logvar) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
# 使用VAE进行变分推断(采样新数据)
with torch.no_grad():
new_samples = torch.randn(10, latent_dim).to(device)
generated_images = vae.decoder(new_samples).view(-1, 1, 28, 28) # 生成新的图像样本代码讲解:
-
定义编码器(Encoder):这是一个全连接神经网络,负责将输入数据映射到潜在空间的均值和对数方差。这两个输出分别对应变分分布
的均值和方差。
-
定义解码器(Decoder):另一个全连接神经网络,接收从潜在空间采样的隐变量
z,并将其映射回原始数据空间,生成重构数据。 -
定义VAE模型:封装编码器和解码器,并实现
reparameterize方法。该方法利用重新参数化技巧从给定的均值和对数方差中采样隐变量z,这是变分推断的关键步骤,确保采样过程对网络参数可微。 -
损失函数:结合二元交叉熵损失(BCE,用于衡量重构数据与原始数据的差异)和KL散度惩罚项(KLD,用于迫使变分分布
)。整体损失函数即为ELBO的负值加常数项。
-
训练循环:使用Adam优化器进行参数更新。每次迭代中,前向传播计算重构数据、均值和对数方差,然后计算损失并反向传播更新模型参数。
-
变分推断应用:在训练完成后,可以通过从标准正态分布中采样新的隐变量
z,然后通过解码器生成新的数据样本,实现数据生成任务。这里展示了生成10个新样本的过程。
以上代码实现了基于变分自编码器的变分推断过程,通过优化ELBO来学习数据的潜在表示和生成模型。在实际应用中,可能需要调整网络架构、优化器设置、损失函数等以适应具体任务需求。同时,要注意将代码运行在适当的硬件设备(如GPU)上以加速计算。
5. 优缺点分析
优点:
- 计算效率:通过优化可解析的ELBO替代直接计算复杂的后验分布,尤其适用于大规模数据集和高维模型。
- 灵活性:可以灵活选择变分族,适应各种模型结构和先验假设,易于与深度学习框架集成。
- 可扩展性:支持在线学习和增量式更新,适用于流式数据和大规模分布式计算环境。
- 不确定性量化:提供对后验分布的近似,有助于进行预测的不确定性评估。
缺点:
- 近似误差:变分分布可能无法准确捕捉后验分布的所有特征,特别是在模型复杂度较高或变分族选择受限时。
- 过平滑:由于KL散度的正则化效应,变分推断可能会导致后验分布的过平滑,低估尾部概率和模型复杂性。
- 依赖于变分族的选择:选择合适的变分族对推断性能至关重要,但实际应用中可能缺乏理论指导。
- 优化挑战:优化ELBO可能存在局部极小值问题,尤其是当目标函数非凸或存在多个模态时。
6. 案例应用
变分推断广泛应用于诸多机器学习任务:
- 生成模型:如变分自编码器(VAE)、变分玻尔兹曼机(VBM)、深度潜因子模型(DeepLFM)等,用于图像生成、自然语言处理、推荐系统等场景。
- 贝叶斯深度学习:通过引入变分先验和后验分布,实现模型参数的不确定性量化,提高模型的泛化能力和鲁棒性。
- 概率图模型:在复杂图模型中,如隐马尔可夫模型(HMM)、条件随机场(CRF)等,变分推断用于高效计算边缘概率和条件概率。
- 强化学习:应用于策略搜索、模型学习、后验预测分布等环节,提升决策质量和模型学习效率。
7. 对比与其他算法
与MCMC对比:
- 计算效率:变分推断通过优化可解析的目标函数,通常比MCMC(如Metropolis-Hastings、Gibbs采样等)更快,特别适合大规模数据和高维模型。
- 可并行性:变分推断更易于并行化和分布式计算,而MCMC通常需要依赖链的状态序列,串行性较强。
- 近似质量:MCMC在理想条件下能收敛到精确后验,而变分推断只能得到近似解,但实际应用中两者都可能受困于混合不充分等问题。
与MAP估计对比:
- 不确定性量化:变分推断提供对后验分布的完整近似,包含不确定性信息;而最大后验概率(MAP)估计仅给出单点估计,忽视了模型参数的不确定性。
- 模型复杂性:MAP倾向于选择复杂模型以最大化数据拟合,可能导致过拟合;变分推断通过KL散度正则化,能在一定程度上防止过拟合。
8. 结论与展望
变分推断作为一种强大的近似推断技术,在机器学习领域展现出了显著的应用价值和广阔前景。尽管存在近似误差、依赖变分族选择等局限性,但随着理论研究的深入和技术手段的进步,如变分推断的深度学习化、自适应变分族设计、基于梯度的采样方法等,这些挑战正在逐步得到缓解。未来,我们期待变分推断能够在更大规模、更高维度、更复杂结构的模型中发挥关键作用,进一步推动机器学习在科学研究、工程技术和社会经济等领域的应用发展。

















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









