







目录
二、实例:使用Selenium操作浏览器获得QQ音乐榜单数据
在上一章中,我们使用Chrome的“检查”功能,对页面元素进行审查,轻松就能找到包含异步数据的真实网址,然后再解析这个网址中的内容来拿到目标数据。本章章,我们将探讨使用模拟浏览器的方法爬取动态数据,相比较审查页面元素的方法,我们不再需要关心数据到底是从哪里传输而来,更不会因为要复制或构造那些冗长且复杂的真实网址而烦恼。
模拟浏览器的方法是在爬虫过程中,打开浏览器加载网页,自动操作浏览器访问各个页面,抓取目标数据或者将操作过程截图保存下来。从数据抓取的角度来讲,就是爬取动态网页编程了爬取静态网页。
本章的重点内容:模拟浏览器环境的准备、使用Selenium操纵浏览器、使用Selenium获得数据
一、模拟浏览器的环境准备
模拟浏览器主要依赖Selenium,并在WebDriver的支持下,实现Selenium与Web浏览器之间的通信。因此,实现模拟浏览器除去基础的编程语言环境,一共由3样东西组成,浏览器、WebDriver、Selenium。
1.Selenium简介
Selenium是由一些列工具和库组成的大型工程项目,在它们的支持下实现Web浏览器的自动化。它主要是为了实现Web的自动化测试,也包括基于Web自动化任务管理。
Selenium可以根据用户的指令,让浏览器加载页面、页面的最大化、最小化、模拟键盘、鼠标操作、元素定位、元素点击、等待页面内容加载、获取需要的数据等。
2.Selenium安装
pip install selenium
3.安装WebDriver
Selenium目前支持firefox、chrome、edge、safari等市面上主流的浏览器,每个浏览器都有特定的WebDriver。本文中我们将对应chrome浏览器,在chromedriver的支持下完成相关操作。
(1)安装chromedriver
百度搜索chromedriver,找到chromedriver镜像。该网址列出了对应不同chrome版本的所有chromedriver文件。
下载时一定要注意自己的chrome浏览器的版本与chromedriver是不是匹配。
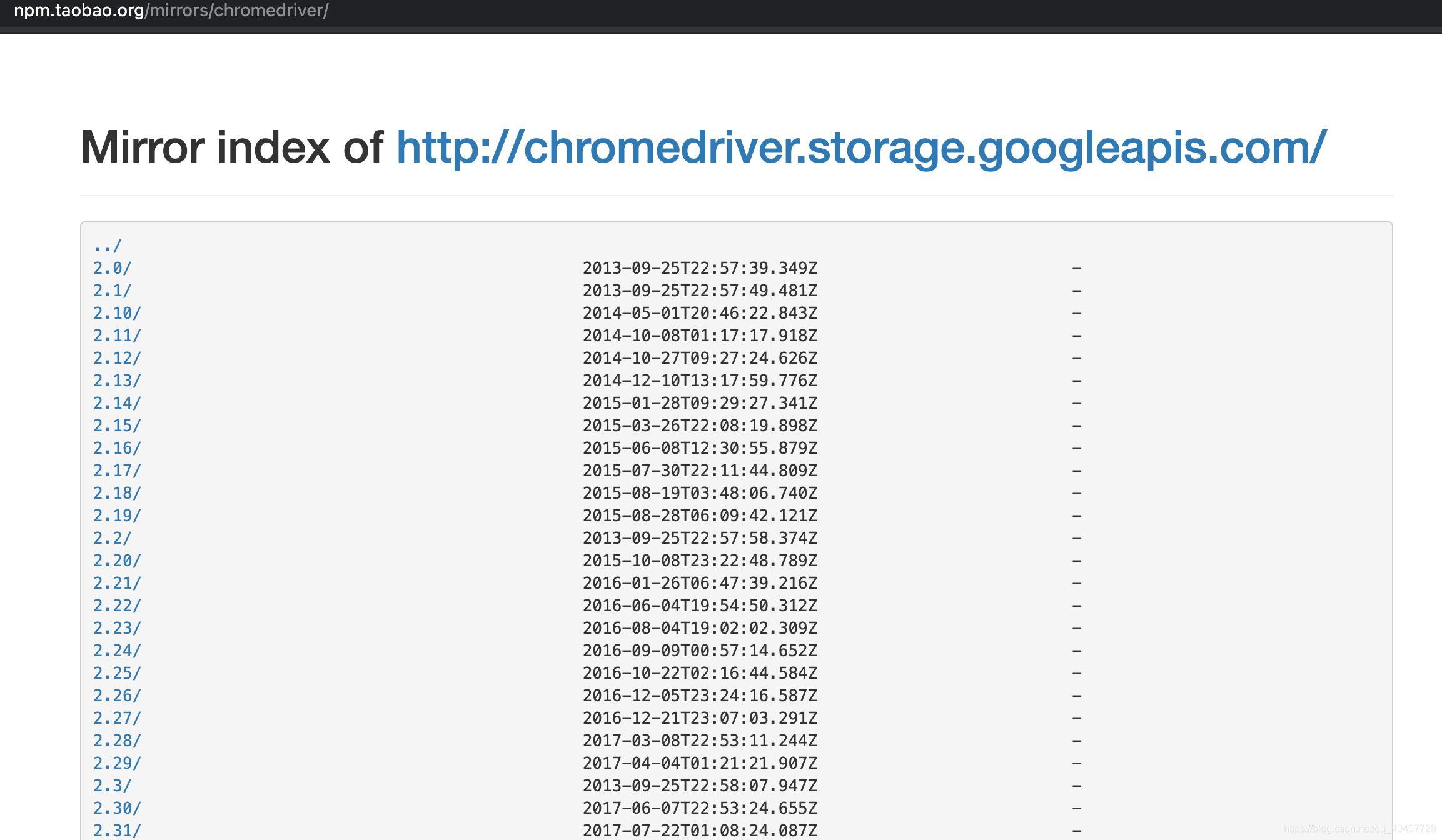
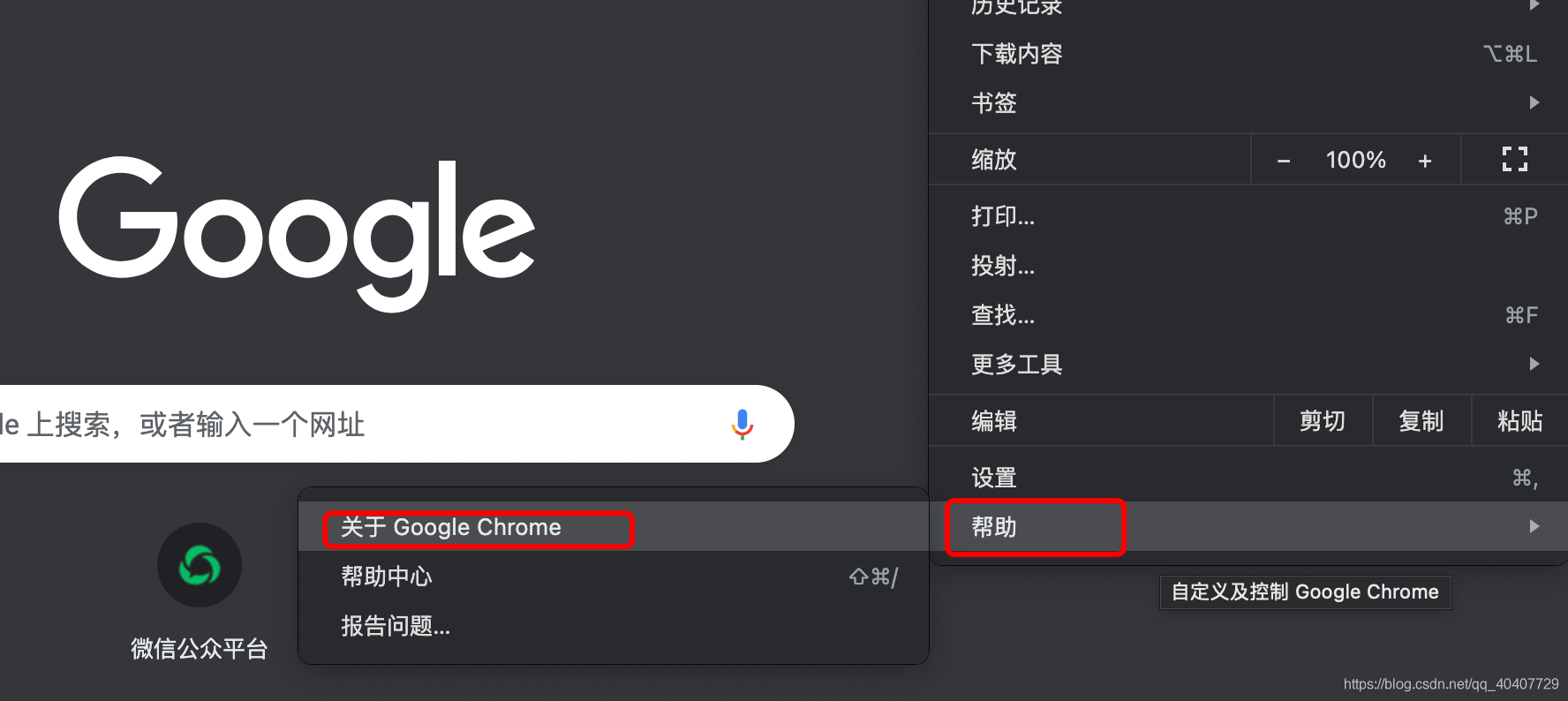
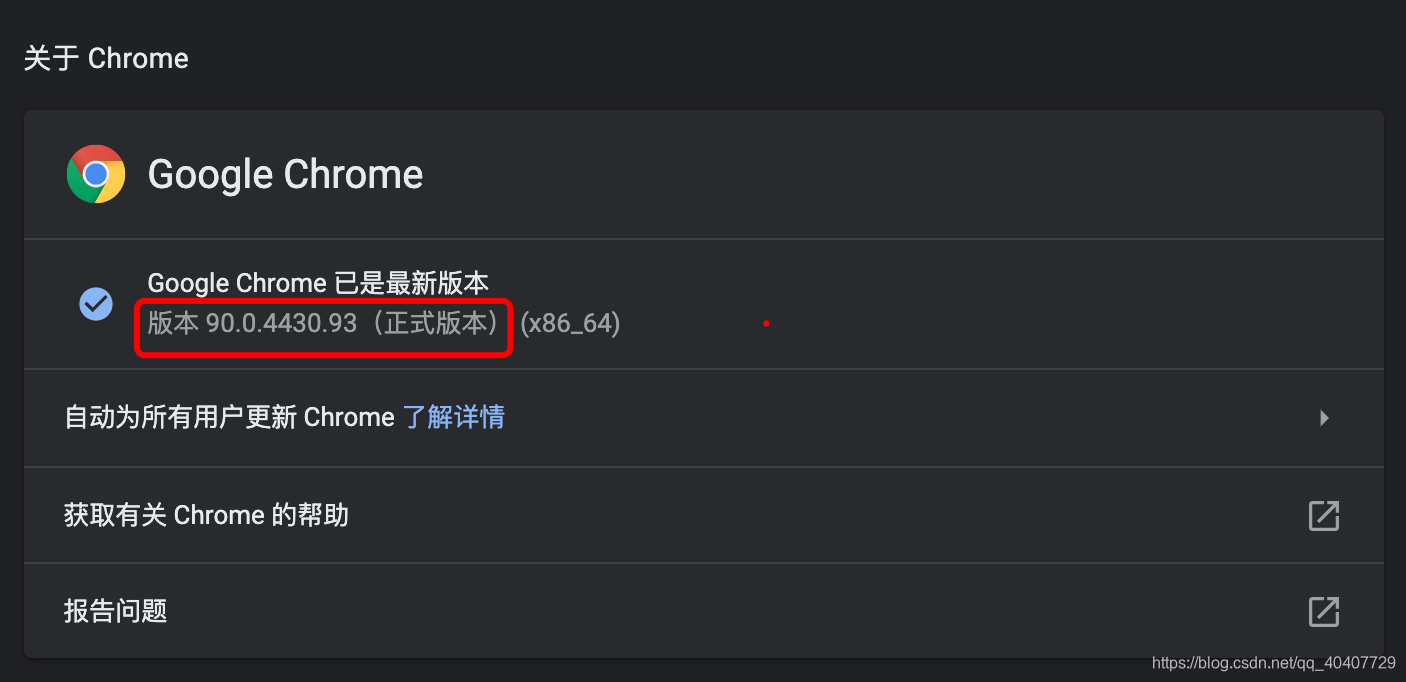
在chromedriver下载网站中找到相应版本号的文件,并根据自己的操作系统下载相应的压缩包文件,解压缩后会得到一个chromedriver的可执行文件。

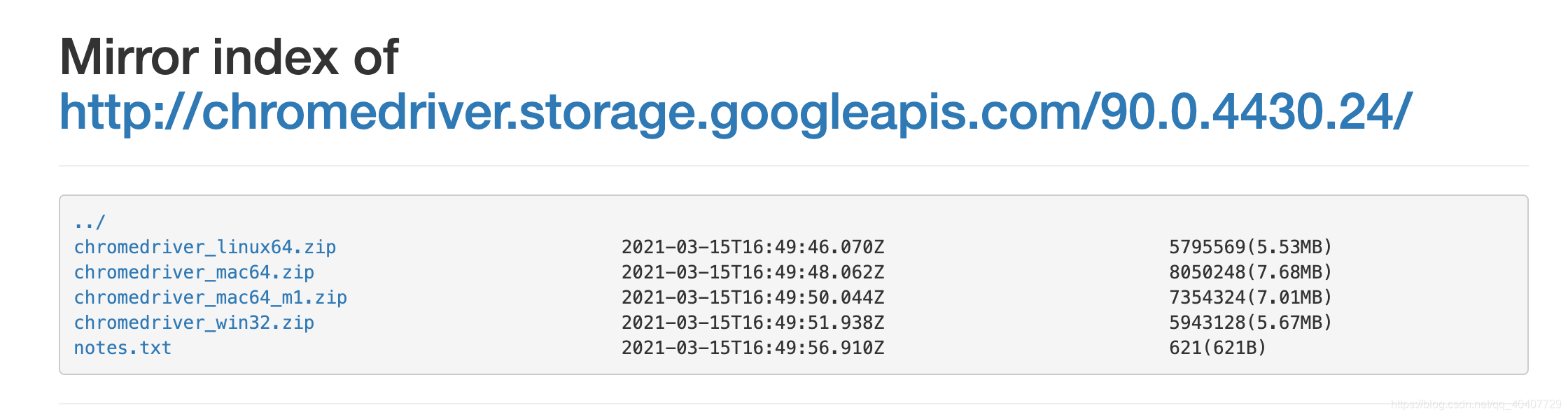
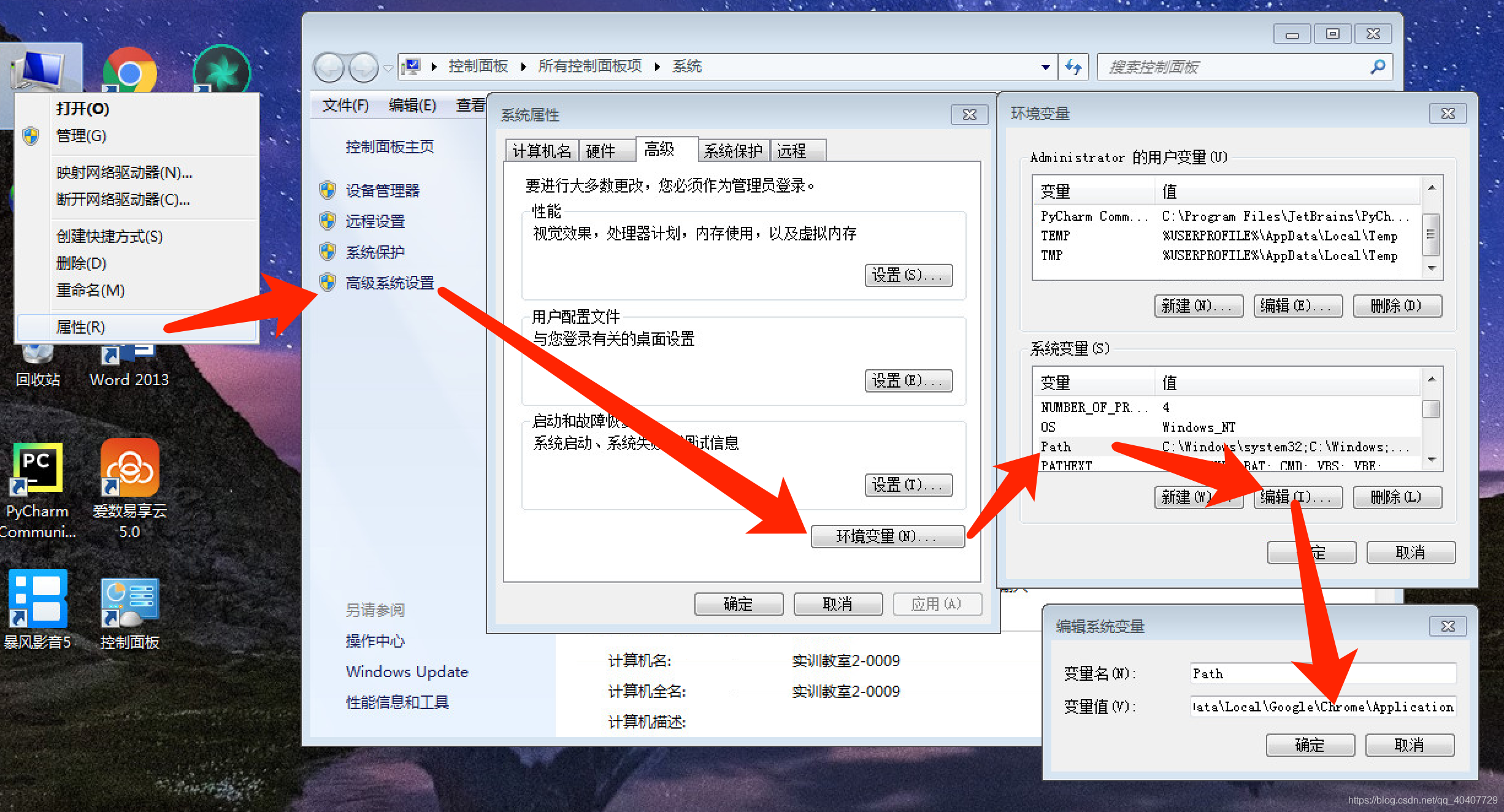
(2)将chromedriver添加到环境变量
如果将chromedriver添加到环境变量,在以后调用chromedriver时不需要再指定它所在的路径。
- windows系统
找到chromedriver.exe解压后所在的位置,复制它的路径。你也可以像网上多数介绍的那样,将chromedriver剪切到C:\Users\Administrator\AppData\Local\Google\Chrome\Application路径下。AppData默认是隐藏的,要想抵达这个路径下,需要在“菜单”——“工具”——“文件夹属性”——“查看”中勾选“显示隐藏的文件、文件夹和驱动器”。
将路径复制到系统的环境变量的路径中,方法见图5。
在命令提示符窗口输入命令“chromedriver --version”,如果没有正常显示版本号,请重新启动电脑。

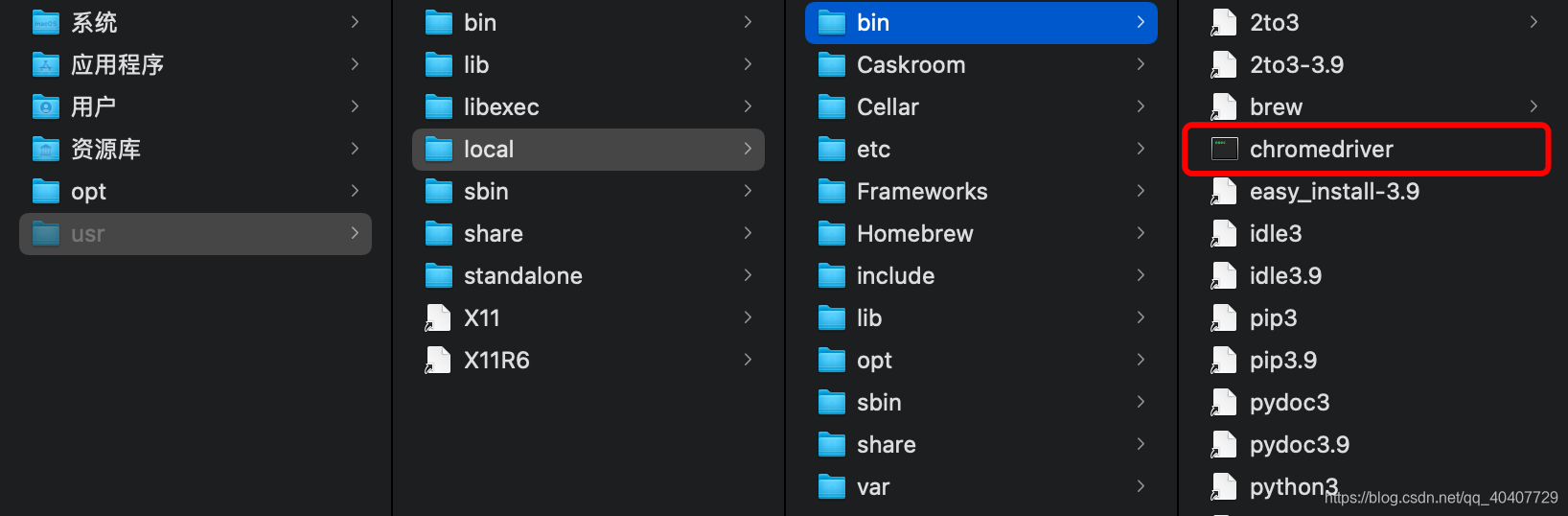
- mac系统
快捷键shift+command+G,启动快速前往对话框
输入路径usr/local/bin
将chromedriver文件拖入到此处
在终端中输入“chromedriver --version”,正常显示版本号则说明成功。
![]()
下面,我们将通过三个实例来了解Selenium操作浏览器的方法。
二、实例:使用Selenium操作浏览器获得QQ音乐榜单数据
1.启动浏览器
from selenium import webdriver # 导入webdriver模块
driver = webdriver.Chrome() # 调用chrome浏览器创建浏览器对象执行以上两段代码后,会打开一个chrome浏览器,在浏览器的左上角会提示“Chrome正受到自动测试软件的控制”

2.使用webdriver打开qq音乐榜单网页
使用get()方法将页面的内容加载到浏览器对象driver中。
driver.get('https://y.qq.com/n/yqq/toplist/4.html')
3.获得网页源代码
print(driver.page_source)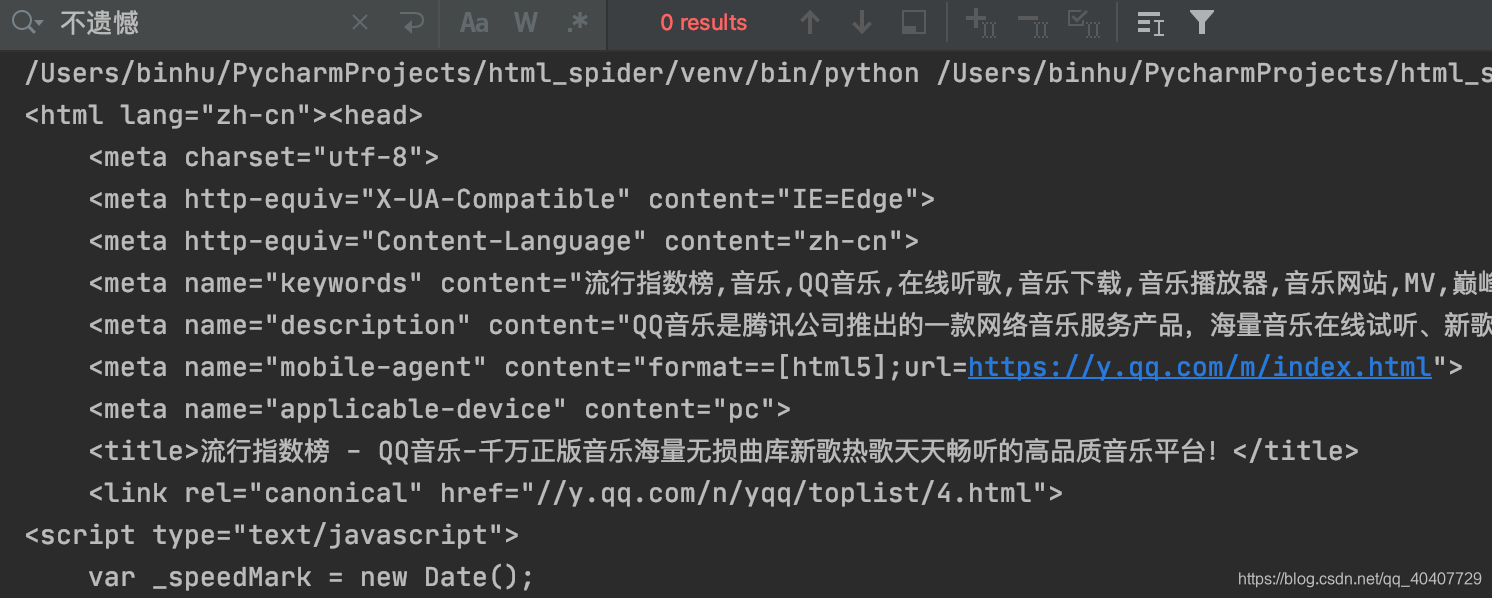
在网页源代码中搜索不到第一首歌曲名称“不遗憾”,这是因为歌曲信息是使用AJAX技术传输的,信息还没有完全加载,就执行了打印操作。
为了解决这个问题,我们需要使用Selenium的等待方法,直到某个元素在页面中出现后,再执行后续操作。
4.页面等待
(1)创建一个等待的对象
导入等待模块
from selenium.webdriver.support.ui import WebDriverWait创建等待对象
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver是浏览器对象;timeout为最长超时时间,默认单位是秒;poll_frequency是休眠时间的间隔时间,默认为0.5秒,意思是每隔0.5秒检查一次条件是否被满足;ignored_exceptions是超时后的异常信息,默认情况下抛出NoSuchElementException。
我们将driver作为浏览器对象,最长超时时间设为10秒。
wait = WebDriverWait(driver,10)WebDriverWait对象一般与until()或until_not()方法配合使用,下面我们使用until()方法设置等待条件。
(2)设置等待条件
wait.until(等待条件)
from selenium.webdriver.common.by import By # 指定元素的定位方法
from selenium.webdriver.support import expected_conditions as EC # 负责条件的触发方法
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'.songlist__item')))引入之前定义的wait对象,调用until方法,传入要等待的条件Expected_conditions,这里传入了presence_of_all_elements_located,意思是所有满足条件的节点都加载出来,其参数为条件定位的元组。这里使用CSS选择器来定位class名称为'songlist__item'的节点,如果10秒内成功加载出来,就继续执行后面的语句,否则抛出异常。
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出来,传入定位元组,如 (By.ID, 'p') |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出来 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现警告 |
By的作用是实现节点的定位,它可以支持多种定位策略。
CLASS_NAME= 'class name' # 使用属性class的值来定位节点
CSS_SELECTOR= 'css selector' # 使用css 选择器来定位节点
ID= 'id' # 使用属性id的值来定位节点
LINK_TEXT= 'link text' # 使用链接的文本内容来定位节点
NAME= 'name' # 根据属性name的值来定位节点
PARTIAL_LINK_TEXT= 'partial link text' # 使用链接的部分文本内容来定位节点
TAG_NAME= 'tag name' # 使用节点的名称来定位节点
XPATH= 'xpath' # 使用xpath来定位节点
设置好等待条件后,我们再print一次page_source会发现此时的源代码中已经包含了榜单中的歌曲信息。
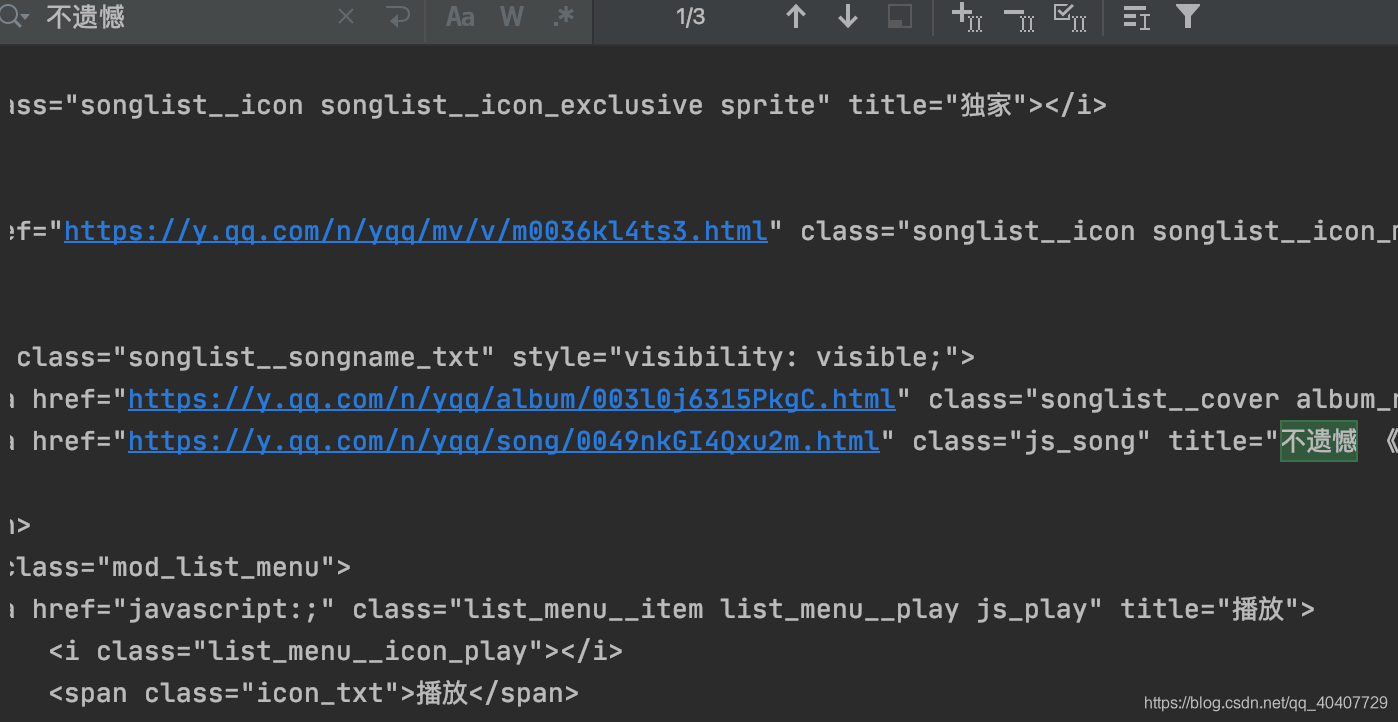
5.使用Selenium获得数据
使用Selenium获得数据一般分为两个步骤,一是定位元素,二是指定获取的内容。
Webdriver提供了一系列定位元素的方法,详见官方文档:
- id定位:find_element_by_id()
- name定位:find_element_by_name()
- class定位:find_element_by_class_name()
- link定位:find_element_by_link_text()
- partial link定位:find_element_by_partial_link_text()
- tag定位:find_element_by_tag_name()
- xpath定位:find_element_by_xpath()
- css定位:find_element_by_css_selector()
以上方法返回的是第一个满足定位条件的节点对象,类型为“<class 'selenium.webdriver.remote.webelement.WebElement'>” 。如果需要获得所有满足条件的节点,只要将element变为elements,该方法返回的是一个列表,例如find_elements_by_id()。
在本实例中,一共有20首歌曲,每首歌曲都在一个li节点下,每首歌曲的名称是的一个a节点下的title的值。我们可以按照先抓大后抓小的原则,使用xpath解析路径。
另外,获取节点信息有两种方式:
- 获取节点的文本信息:.text
- 获取节点的属性值:.get_attribute('属性的名称')
获取榜单歌曲名称的代码:
data = driver.find_elements_by_xpath('//ul[@class = "songlist__list"]/li') # 先抓大,获取每首歌的节点
for song in data:
print(song.find_element_by_xpath('./div/div[4]/span/a[2]').get_attribute('title')) # 后抓小,获取每首歌的名称优化后的完整代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 10)
def get_source():
url = 'https://y.qq.com/n/yqq/toplist/4.html'
driver.get(url)
try:
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.songlist__item')))
data = driver.find_elements_by_xpath('//ul[@class = "songlist__list"]/li')
for song in data:
print(song.find_element_by_xpath('./div/div[4]/span/a[2]').get_attribute('title'))
except TimeoutError:
get_source()
def main():
get_source()
if __name__ == "__main__":
main()
driver.close()三、实例:使用selenium模拟浏览器登录百度账号
1.创建webdriver对象
导入所有库,创建webdriver对象,并使用.get方法打开百度首页
from selenium.webdriver import Chrome
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import time
driver = Chrome()
driver.get('https://www.baidu.com')2.打开登录框
创建一个webdriverwait对象,使用检查工具找到用户登录的节点,用户登录按钮节点的ID值为"s-top-loginbtn",使用click()方法。
wait.until(EC.presence_of_element_located((By.ID,"s-top-loginbtn"))).click()执行后会弹出百度登录框,登录框中提供了扫码登录和用户名登录两种登录方式,用检查工具找到用户名登录的节点,该节点的名称为p,class值为"tang-pass-footerBarULogin pass-link"。
wait.until(EC.presence_of_element_located((By.XPATH,'//p[@class = "tang-pass-footerBarULogin pass-link"]'))).click()3.输入用户名和密码
此处使用time.sleep()方法先等待1秒
然后分别找到用户名和密码文本框的节点,使用.send_keys()方法传入用户名和密码。
time.sleep(1)
username = driver.find_element_by_name("userName")
username.send_keys('用户名') # 输入你的用户名
password = driver.find_element_by_name("password")
password.send_keys('密码') # 输入你的密码4.点击登录按钮
使用检查工具找到登录按钮的节点,该节点的ID值为"TANGRAM__PSP_11__submit",使用等待方法定位登录按钮,并调用click()。
wait.until(EC.presence_of_element_located((By.ID,"TANGRAM__PSP_11__submit")))
submit.click()在点击登录后,可能会出现图像认证,这里我们设置等待5秒钟,用户手动完成图像认证。接下来我们可以使用get_cookies方法拿到登录后的cookies.完整代码如下:
from selenium.webdriver import Chrome
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import time
driver = Chrome()
driver.get('https://www.baidu.com')
wait = WebDriverWait(driver,10)
wait.until(EC.presence_of_element_located((By.ID,"s-top-loginbtn"))).click()
wait.until(EC.presence_of_element_located((By.XPATH,'//p[@class = "tang-pass-footerBarULogin pass-link"]'))).click()
time.sleep(1)
username = driver.find_element_by_name("userName")
username.send_keys('用户名') # 输入你的用户名
password = driver.find_element_by_name("password")
password.send_keys('密码') # 输入你的密码
submit = wait.until(EC.presence_of_element_located((By.ID,"TANGRAM__PSP_11__submit")))
submit.click()
print('等待用户进行图像认证')
time.sleep(5)
cookies = driver.get_cookies()
print(cookies)
print('登录成功')四、实例:模拟浏览器获取豆瓣的影评信息
from selenium.webdriver import Chrome
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import csv
import time
# 创建WebDriver对象
driver = Chrome()
# 创建WebDriverWait对象
wait = WebDriverWait(driver, 30)
def get_data():
url = 'https://movie.douban.com/'
driver.get(url) # 打开豆瓣电影网站
driver.implicitly_wait(10)
search_input = driver.find_element_by_tag_name("input") # 寻找搜索框
search_input.send_keys("角斗士") # 模拟键盘输入搜索的内容
search_input.send_keys(Keys.RETURN) # 模拟键盘回车
wait.until(EC.presence_of_element_located((By.XPATH,'//div[@class="paginator sc-htoDjs eszZtj"]'))) # 等待翻页栏出现,即本页加载完毕
driver.find_element_by_xpath('//div[@id="root"]/div/div[2]/div[1]/div[1]/div[1]/div[1]/div/div[1]/a').click() # 通过xpath定位到本页第一部电影的名称,并单击该节点
time.sleep(1) # 休息一秒钟,等待页面加载
button = wait.until(EC.presence_of_element_located((By.XPATH,'//a[@href="reviews"]'))) # 等待"全部影评"节点
button.click() # 单击打开"全部影评"页面
time.sleep(1) # 休息一秒钟,等待页面加载
comment_list = [] # 创建一个空列表,用来存放所有的影评信息
for i in range(10): # 循环访问10个页面
wait.until(EC.presence_of_element_located((By.XPATH,'//div[starts-with(@class,"review-list")]'))) # 等待影评列表加载完毕
data = driver.find_elements_by_xpath('//div[starts-with(@class,"review-list")]/div') # 安装先抓大后抓小原则,使用xpath抓取每个楼层
for item in data: # 循环抓取每层楼的影评内容、作者和提交时间
comment = {}
comment['content'] = item.find_element_by_class_name('short-content').text
comment['author'] = item.find_element_by_xpath('./div/header/a[2]').text
comment['comment_time'] = item.find_element_by_class_name('main-meta').text
comment_list.append(comment)
wait.until(EC.presence_of_element_located((By.CLASS_NAME,"next"))).click() # 实现翻页功能
time.sleep(1) # 翻页后休息1秒钟
return comment_list
def writer_csv(data): # 将列表写入csv中
with open('douban_reviews.csv','w',encoding='utf-8-sig') as f:
writer = csv.DictWriter(f,fieldnames=['content','author','comment_time'])
writer.writeheader()
writer.writerows(data)
def main():
result = get_data()
writer_csv(result)
if __name__ == '__main__':
main()
driver.quit()五、小结—合理使用Selenium
Selenium可以模拟任何操作,例如单击、右击、拖拉、滚动、复制粘贴或者文本输入等。操作方式大致可分为常规操作、鼠标事件操作和键盘事件操作。
使用Selenium的优点很明显,通过少量代码我们就可以获取异步传输的数据,或者实现网站的模拟登录。但是它的缺点也很突出,那就是运行速度较慢,因为它要等待页面内容加载完毕才会运行后面的代码,如果页面中有很多的图片又有很多的异步加载,那就需要花费很长的时间。此时,我们需要在WebDriver的option选项设置中,关闭加载图片、CSS或JS等,来缩短等待时间。
灵活运用Selenium,将有助于提升爬虫开发效率,在实际开发中,将Selenium作为辅助工具,对于一些难以找到JS或者XHR源的数据,Selenium可能还有一线希望。而对于有明确数据源的数据,request直接去请求的效率就会显得特别具有优势了。
六、获取深圳租房信息
目标网站:房天下
目标数据:爬取100条租房信息,包含名称(title)、月租金(price)、出租方式(rent_out_mode)、房型(house_type)、面积(area)、朝向(orient)、区域(district)、小区名称(neighbourhood_name)、与地铁站的距离(distance_from_subway_station)等。
主要用到的技术:selenium、xpath。
技术提示:1.刚打开房天下的时候会有一个cover页,需要设置等待找到closecover节点并执行点击动作,从而关闭cover页;
2.翻页有两种方式,一是点击指定页面的链接,二是点击下一页的链接,请观察和测试一下,哪种方式更稳定?
3.因为只爬取100条租房信息,在爬取数据时和翻页时都要进行条件控制;
4.翻页后,最好能设置1秒钟的休息,等待数据加载。
需要提交的作业内容:.py,.csv。


















 3557
3557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











