







一、去重效率优化
尽量使用group by分组来去重,其效率高于distinct
涉及统计数量时,可使用先group by在使用count(user_name),而不是直接count(distinct user_name)
二、聚合技巧应用
1、grouping sets,同时对不同类别分组
如要用户的性别分布、城市分布、等级分布,以前的写法要分别写三个sql执行3次
grouping sets可将group by查询中根据不同维度进行聚合,聚合规则在括号中填写
#以前的写法
select sex,count(distinct user_id)
from user_info
group by sex;
#优化的写法
select sex,city,level,count(distinct user_id)
from user_info
group by sex,city,level
grouping sets (sex,city,level);
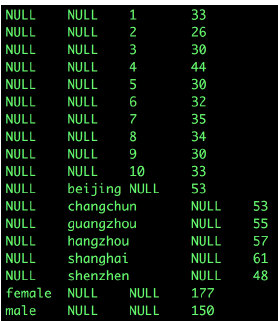
稍复杂一点举例,用户性别分布及每个性别的城市分布
select sex,city,count(distinct user_id)
from user_info
group by sex,city
grouping sets (sex,(sex,city));
2、cube,根据group by维度的所有组合进行聚合
三、开启并发执行,对当前窗口生效
开启并发
set hive.exec.parallel=true;
查询是否开启并发
set hive.exec.parallel;
开启后对所有可使用并发的流程均有效,如union all
四、lateral view进行行转列
五、数据倾斜
任务进度长时间维持99%,查看任务监控,只有少量(1个或几个)reduce任务未完成。因其处理的数据量和其他reduce差异过大
解决:
1)空值产生的数据倾斜
两个表连接时,使用的连接条件有很多空值,建议在连接条件中增加过滤(a.user_name is not NULL)
2)大小表连接(一张表很大,另一张表很小)
将小表放到内存里,在map端做join 暂时没理解
3)两个表连接条件的字段数据类型不一致
转成一致
on a.user_id=cast(b.user_id as string)














 4177
4177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









