







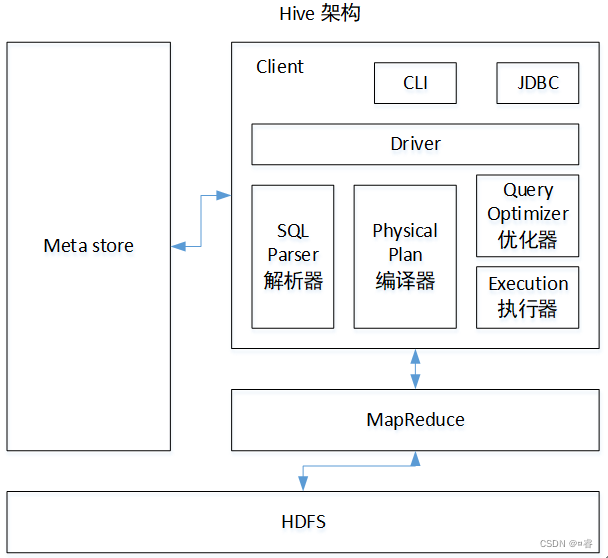
先来看hive的运行机制:
Hive 通过用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
由此得出,对于hive来说,查看某个语句的执行效率还是需要查看底层设计的。
hive的跑数一般是MapReduce和Spark,以MapReduce为例来讲的话:
以下表为例
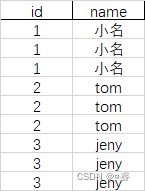
select distinct
id,name
from tmp;
select
id,name
from tmp;
相比而言,group by的速率会更快,因为group by 在MapReduce中会先分组,而distinct会对整张表进行计算。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









