







最近看了一下各种B树,B+树,BW树,FD树等B+树的变种,主要是为了看看数据库的底层存储结构以及索引结构原理。首先从最基础的二分搜索树,到B树,再到B+树,再到各种B树的变体,根据不可变性和原地更新的特点以及是否利用缓冲引申出来各种树,如COW B树,惰性B树,FD树,Bw树,缓存无关B树,LSM树。现在对其进行一个总体的回顾。
BST
首先介绍最简单的二分搜索树BST
基本概念
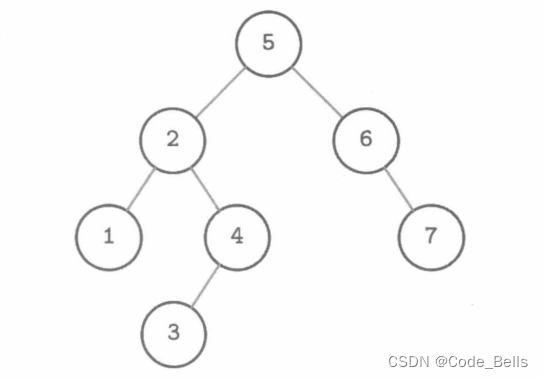
二分搜索树是一种有序的内存数据结构,每个节点一个key和一个value组成。BST是一颗二叉树,左边子树的所有节点存储的value都比该节点小,右边子树所有节点存储的value都比该节点大。结构如图所示。
树的平衡过程
平衡指的是左右子树的最大高度差不超过1。
平衡因子即左右子树的最大高度差。
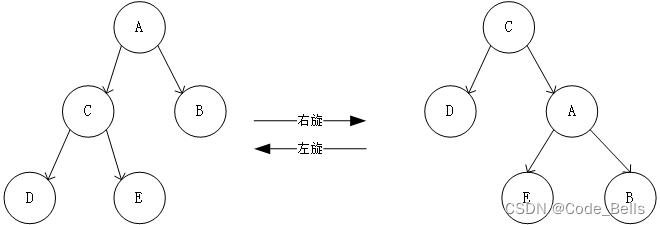
在插入或删除时,最简单的方法就是找到位置后直接插入或删除就不管这棵树了,但是这很有可能导致树处于不平衡状态,这种状态会导致树的搜索速度降低,因为最极端的情况,BST会成为一个单向链表,查询的复杂度为O(n),而如果能够使这棵树保持平衡状态,那么每次下沉到子树的时候就会舍去一半的节点,使复杂度达到O(log(n)),这也被叫做AVL,平衡二叉树,通过对非平衡树的左旋右旋达到将树平衡的目的,左旋右旋过程如下图,对左边的根节点右旋即是将根节点A变成C的右子节点,C的原右子节点变为A的左子节点,C成为根节点。左旋亦然。对于不同的树型,进行不同的左旋右旋操作。
我们定义异常结点(平衡因子大于1的节点)左孩子平衡因子为1的树为LL树,对异常结点右旋即可平衡;异常结点左孩子平衡因子为-1的树为LR树,对其异常结点的左子节点左旋,再对异常节点右旋即可;异常结点右孩子平衡因子为1的树为RL树,对异常节点的右子节点右旋,再对异常节点左旋即可;异常结点左孩子平衡因子为-1的树为RR树,对其异常节点左旋即可。
此时我们学会了树的基本操作,但是二叉树有一个很大的缺点,在插入多的时候,需要不断执行平衡操作,执行平衡操作就需要更新不断更新指针,这使得其维护成本很高,所以自然的我们需要一个高扇出,低高度的树,以此来适应磁盘的读写性能。高扇出可以改进临近键的数据局部性,低高度可以减少遍历期间的寻道次数。所以我们引入了B树。
B树
B树建立在AVL树的基础上,但是它具有高扇出低高度的特点,即一个节点可以存在2个以上的子节点。由此,我们可以将二叉树表示为这样的形式
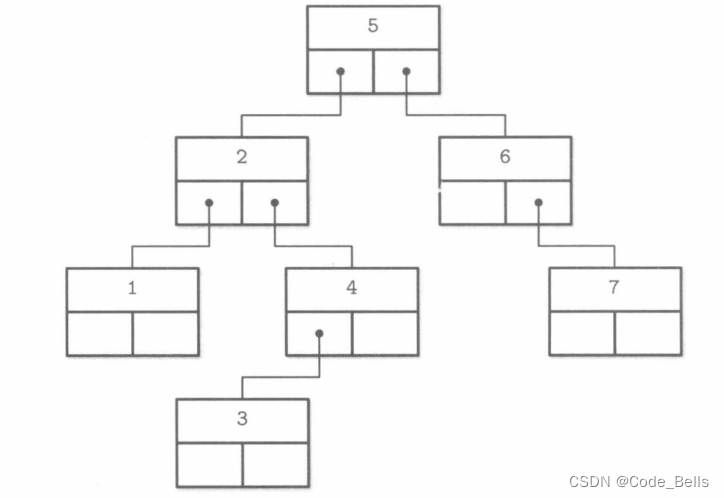
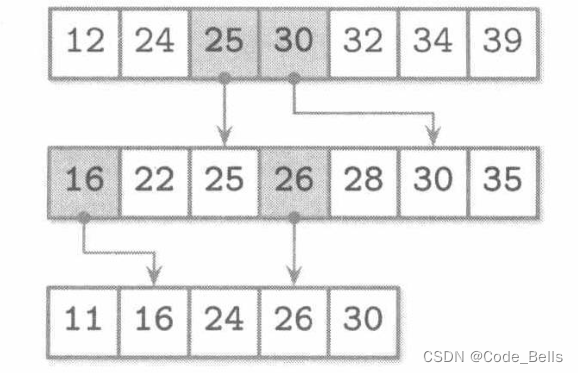
B树和AVL树最大的不同就是高扇出,低高度,他每个节点可以存储N个键,N+1个指针,就如同上图,指针可以简单理解为多少个子节点,键则可以理解为存储的数据个数。B树也是一个有序的,那对于其数据的存储也是和AVL类似, 存储在B树节点的键可以称为索引条目或者分隔键,用它来分割子树,第x个指针指向的子树存储的数据值都小于该节点的第x个数据值, 第x+1个指针指向的子树存储的数据值都大于该节点的第x个数据值。如下图所示。
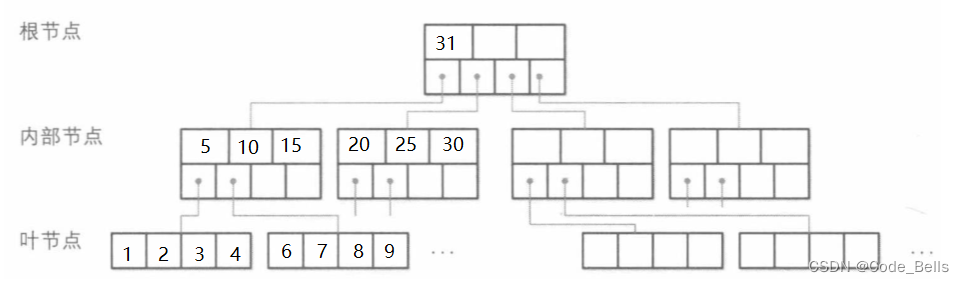
B+树
B+树和B树的区别就在于B树的非叶子节点可以存储数据,而B+树只有叶子节点能存储数据。并且叶子节点使用指针相连,左边的结尾会保存右边节点开始数据的指针,这使得我们可以像链表一样看到数据。
这种设计使得B+树适合全表扫描,而不需要像B树一样进行遍历整棵树。而B树相对于B+树的优点就是如果热数据接近根节点,因为B树在非叶子节点存储数据,这就可以让B树的检索速度优于B+树。
COW B树
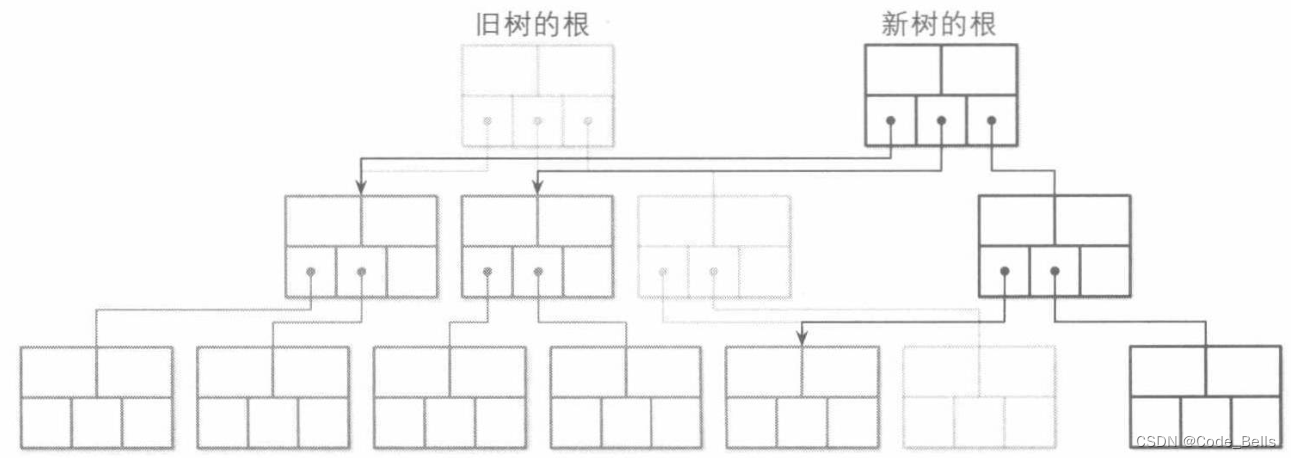
即写时复制(copy on write) B树,结构类似于B树,但是不同的是,B树的节点更新是原地更新的,而COW B树的节点不可变,页会被复制,更新然后写入新的位置。通过创造一个平行的树状层次结构,然后将原来树节点指针更新即可。注意,对于更新并发的操作,旧版本的树还是可用的。如下图所示,更新了根节点的第三个子节点的第二个子节点,因为更新了这个节点会导致父节点的指针被更改,则会将这个更新一直会牵扯到根节点。浅色的即旧版本的树数据。
惰性B树
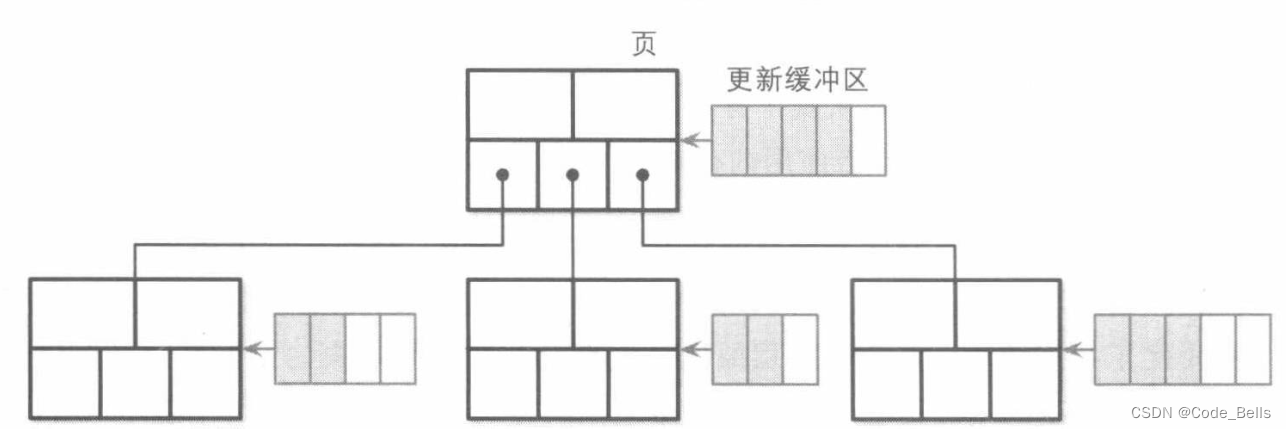
MongoDB的默认存储引擎WiredTiger使用缓冲实现了惰性B树,相对于B树,对于更新,它将更新放入缓冲区,每次读取数据先去缓冲区读取,没有的话才去树中读取,缓冲区会在刷写页的时候,将缓冲的数据和树的数据协调合并。并且刷写页的过程是后台线程执行的,读写进程无需等待其完成。
如下图
LA树
惰性自适应(Lazy adaptive)树,和惰性树不同的在于惰性树只在单个节点有一个更新缓冲区,而LA树可以在子树中存在更新缓冲区,跟踪对子树节点执行的所有操作。缓冲区是具有层次依赖关系的,也是级联的,更新会从高层缓冲区传递给底层缓冲区,到达叶子节点的时候,会进行批量的插入更新删除,所以可以一次更新多个页,减少更多的磁盘访问。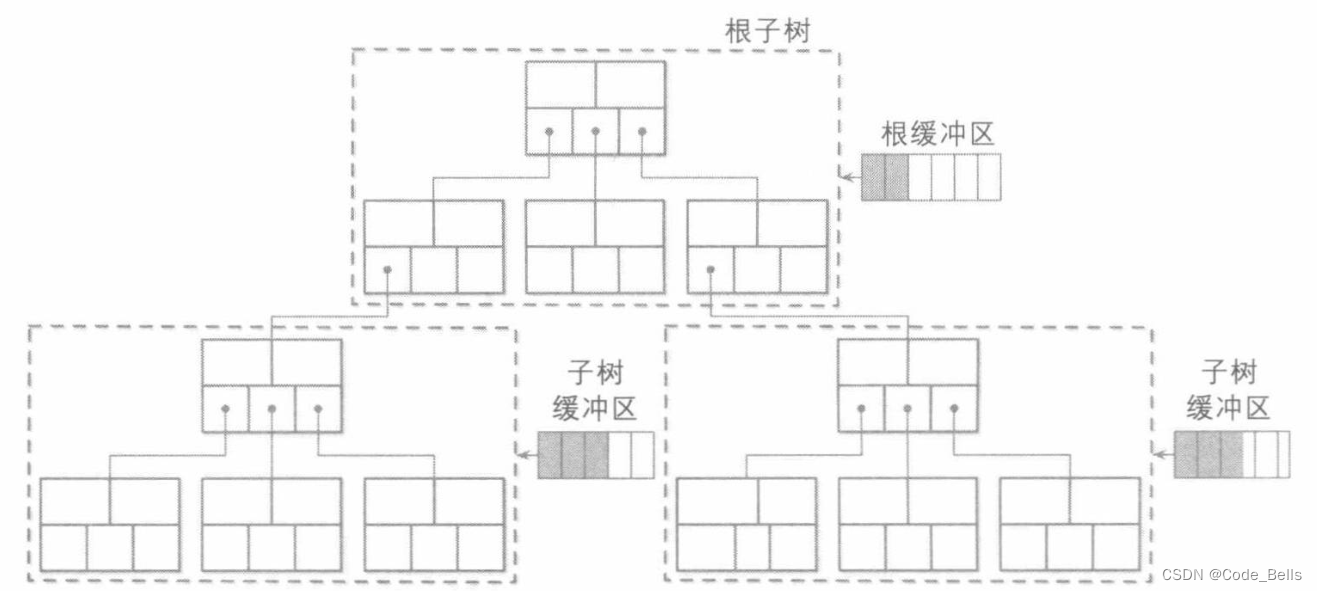
FD树
闪存盘(Flash Disk)树最重要的是分段级联思想,来维护层之间的指针。因为仅追加存储以及合并,将不同节点更新归并到一起,这意味这更新无需定位目标节点,只是单纯的追加操作。
FD树由一个小的,可变的头部树和多个不可变的有序段构成。随机IO产生时,会把更新缓冲在头部的小型B树中,一旦头部树被填满,就会把内容转移到不可变的有序段中,如果有序段超过阈值,就会和下一层合并。
分段级联
通过把序号较大的数组中每隔几个元素就将元素拉到较小的数组中来弥补元素之间的间隔

每隔一个元素就插入到上一个数组。

这些被拉出来的元素可以作为指针,从高层指向底层。
所以FD树的结构如下
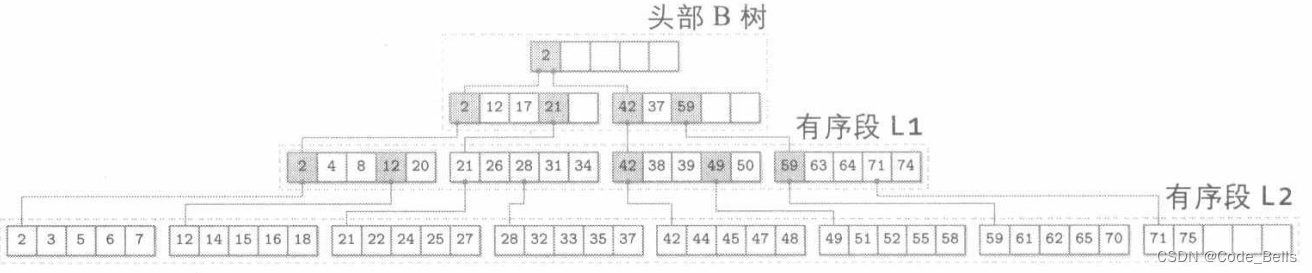
FD树不在原地更新页,并且可能在几个层上存在相同键的数据记录,所以FD树使用墓碑来进行删除,类似一个标记,表示相应数据被删除,当墓碑被传到最底层的时候,就可以被丢弃了。因为此时可以保证没有需要它遮蔽的数据了。
BW树
在原地更新的B树中,写放大是一个问题,并且空间放大也是一个问题,BW树通过仅追加存储来对不同的节点进行更新解决这两个问题,每个节点是由一个链表构成,链表末尾是基节点,其余是增量节点,增量节点表示更新插入,删除。
如图所示。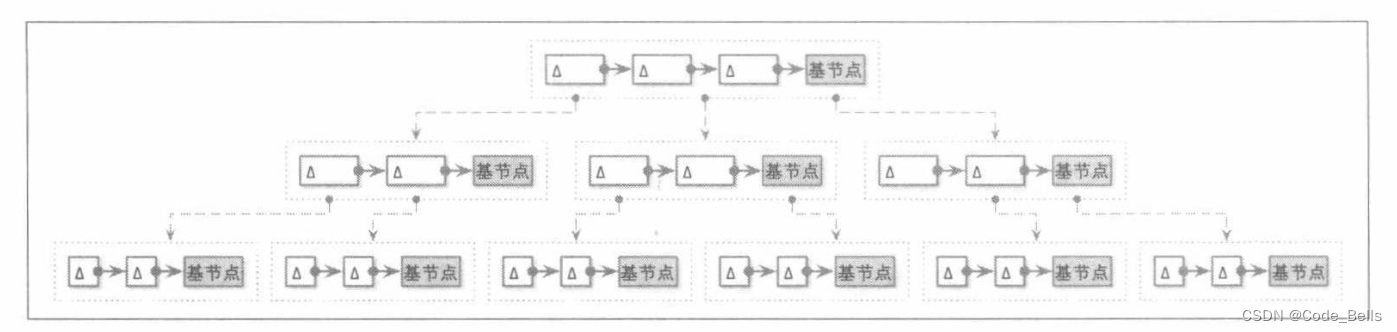
缓存无关B树
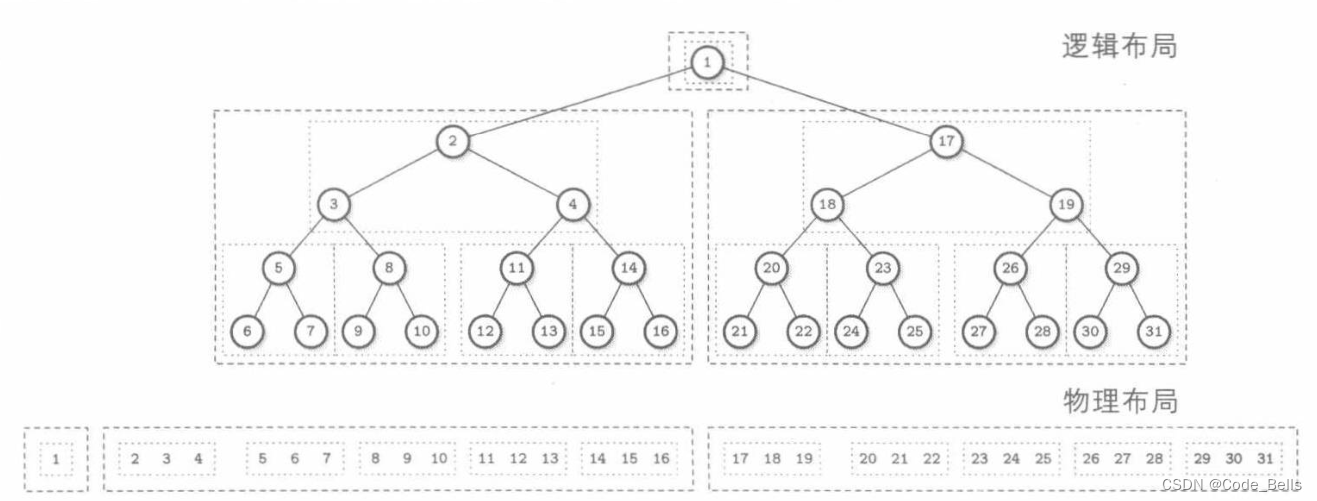
一个缓存无关B树由一个静态B树和一个打包的数组结构组成。静态B树使用van Emde Boas布局构建。在中间层的边上将树分裂,然后用类似方法分裂每个子树,最后得到大小为根号N的子树。这种布局的关键思想是,任何递归树都存储在一个连续内存块中。逻辑上,可以看到节点紧密形成树结构,底层存储可以看到树节点的内存和磁盘布局。
打包数组是一种为将来插入的元素保留间隙的数据结构,很简单的思想,如图。

LSM树
日志结构合并(Log Structured Merge)树是最流行的不可变磁盘存储结构之一,使用缓冲和仅追加存储来实现顺序写操作。
LSM树包括两个组件,内存驻留组件,也就是memtable,这是可变的,通常是一个内存排序树,缓冲数据记录,并且充当读写的目标,当大小达到阈值的时候,会被持久化到磁盘上,他不需要磁盘访问,只需要一个单独的预写日志文件即可保证数据记录的持久性;磁盘驻留组件通过将内存中缓冲的内容刷写到磁盘上来构建,仅用于读取,是不可变的。
通过组件的多少,可以分为双组件LSM树和多组件LSM树即一个磁盘驻留组件和多个磁盘驻留组件的区别。
当刷盘的时候,memtable和磁盘驻留组件的读取写入权限如图。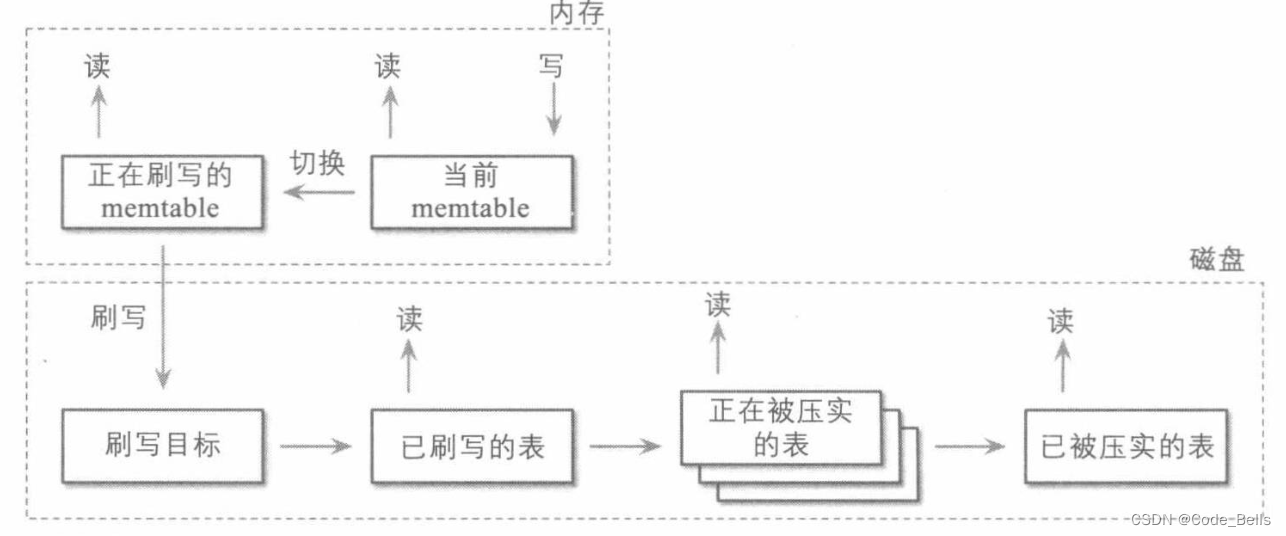
磁盘驻留组件一般使用SSTable实现,即有序字符串表
我的个人博客,欢迎交流!
CodebellsCodebells personal blogs. https://codebells.github.io/
https://codebells.github.io/
参考资料
数据库系统内幕 (美] 亚历克斯·彼得罗夫(Alex Petrov)翻译黄鹏程 傅宇 张晨)















 1057
1057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









