







PyTorch框架学习十五——可视化工具TensorBoard
之前的笔记介绍了模型训练中的数据、模型、损失函数和优化器,下面将介绍迭代训练部分的知识,而迭代训练过程中我们会想要监测或查看一些中间变量,所以先介绍一下PyTorch的可视化,使用的是TensorBoard。TensorBoard可以帮助显示很多重要的中间训练过程,如可视化损失值、准确率的变化,特征图的显示,模型的计算图(结构)以及网络层的权重分布等等,非常有利于分析模型的正确性,方便理解和调整模型。
一、TensorBoard简介
TensorBoard是TensorFlow中强大的可视化工具,支持显示标量、图像、文本、音频、视频和Embedding等多种数据可视化。其在PyTorch中也能使用。
它的运行机制如下图所示:
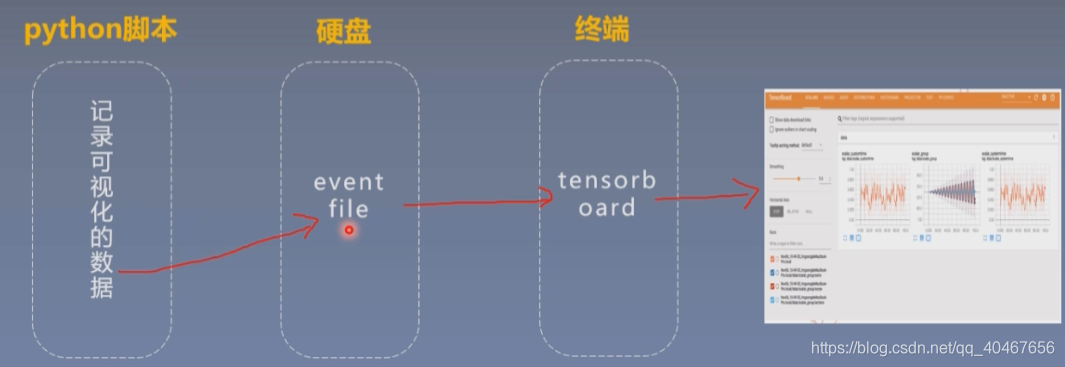
在程序中加入记录可视化数据的代码,程序运行的时候会在硬盘生成event file,将需要记录和显示的数据存入event file,TensorBoard就可以读取event file里的数据并在终端(默认网页)进行绘制。
二、TensorBoard安装及测试
TensorBoard的安装也是很简单的,打开Anaconda的终端,进入需要安装TensorBoard的虚拟环境:

然后输入pip install tensorboard,就会自动安装:
ps:可能还需要手动再安装一个future包,如果在安装TensorBoard时没有自动安装的话。
用一个例子来试验一下TensorBoard是否可以使用,先不用管代码具体什么意思:
import numpy as np
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter(comment='test_tensorboard')
for x in range(100):
writer.add_scalars('data/scalar_group', {"xsinx": x * np.sin(x),
"xcosx": x * np.cos(x),
"arctanx": np.arctan(x)}, x)
writer.close()
运行没有报错之后,在终端进入该虚拟环境该路径下,输入tensorboard --logdir=./,如下图所示:

会给出一个网址,点进去之后就是TensorBoard的终端网页,以及绘制好的图像:
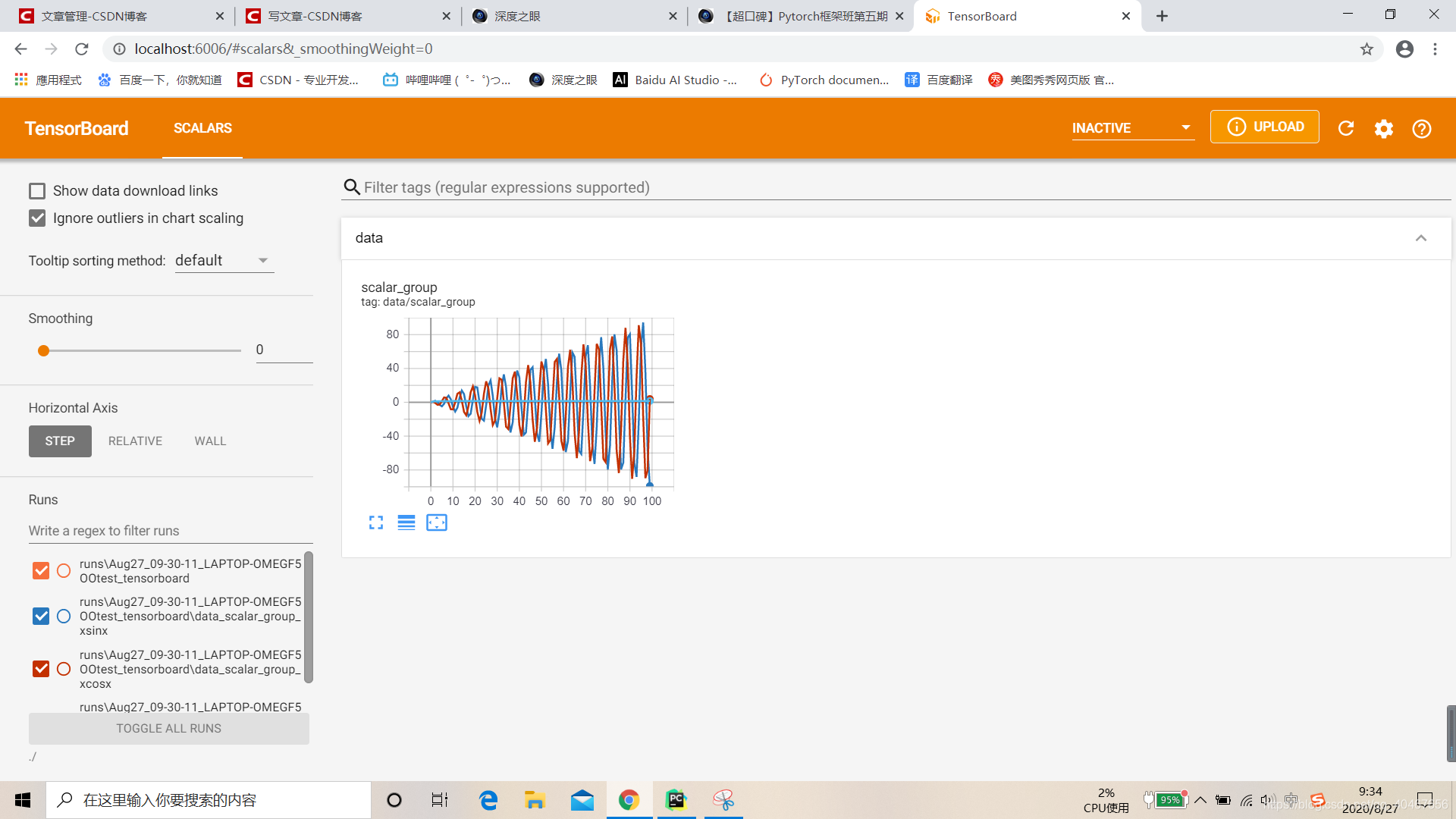
以上就是安装以及测试的简介。
三、TensorBoard的使用
首先需要介绍SummaryWriter类:
class SummaryWriter(object):
def __init__(self, log_dir=None, comment='', purge_step=None, max_queue=10,
flush_secs=120, filename_suffix=''):
功能:提供创建event file的高级接口。
主要属性:(都与event file的创建路径有关)
- log_dir:event file输出文件夹的路径。
- comment:不指定log_dir时,文件夹的后缀。
- filename_suffix:event file文件名后缀。
举几个例子就明白了:
首先是指定log_dir的:
log_dir = "./train_log/test_log_dir"
writer = SummaryWriter(log_dir=log_dir, comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
创建的event file的路径如下图所示:

都是按照log_dir指定的路径创建,此时comment虽然指定但是不起作用,event file后面也带上了filename_suffix的后缀12345678。
再来看一下不指定log_dir的例子:
writer = SummaryWriter(comment='_scalars', filename_suffix="12345678")
for x in range(100):
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
创建的event file的路径如下图所示:

这边的runs/时间+设备型号/event file是默认的创建路径,comment指定的‘_scalars’是加在了时间+设备型号这个文件夹后面,即event file的上级目录,filename_suffix指定的‘12345678’还是加在event file后面。
以上是SummaryWriter类的使用简介,下面将介绍SummaryWriter类下的具体方法,用以在TensorBoard中进行绘制。
1.add_scalar()
功能:记录标量。
add_scalar(self, tag, scalar_value, global_step=None, walltime=None)
主要参数:
- tag:图像的标签名,图的唯一标识。
- scalar_value:要记录的标量(y轴)。
- global_step:x轴。
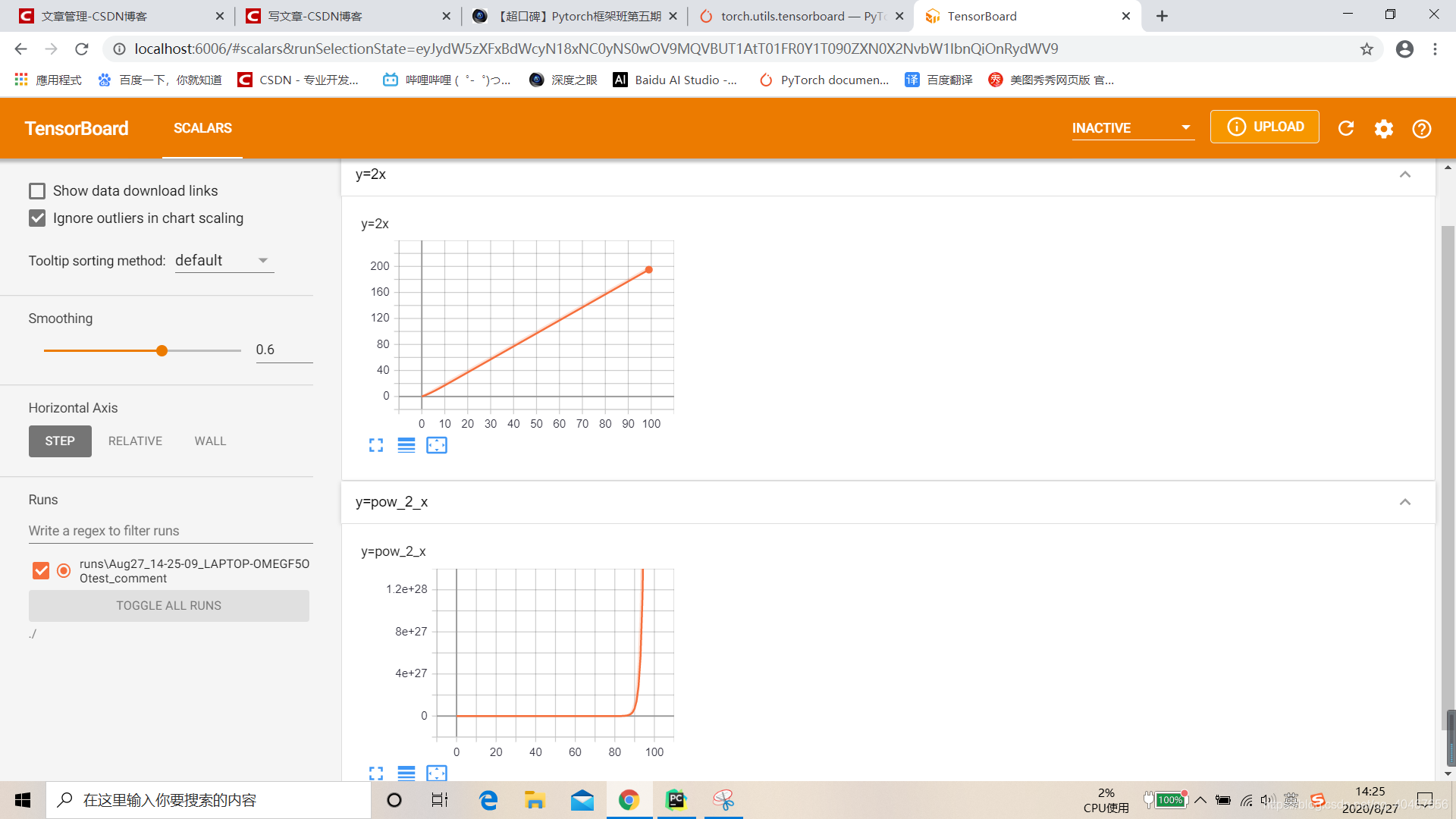
举例如下:
max_epoch = 100
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(max_epoch):
writer.add_scalar('y=2x', x * 2, x)
writer.add_scalar('y=pow_2_x', 2 ** x, x)
writer.close()
分别可视化了y=2x和y=pow_2_x,如下图所示:
2.add_scalars()
功能:在一张图中记录多个标量。
add_scalars(self, main_tag, tag_scalar_dict, global_step=None, walltime=None)
主要参数:
- main_tag:该图的标签。
- tag_scalar_dict:key是变量的tag,value是变量的值。
- global_step:x轴。
例子的话,刚刚测试的时候的代码就是用到了add_scalars(),具体见上面。
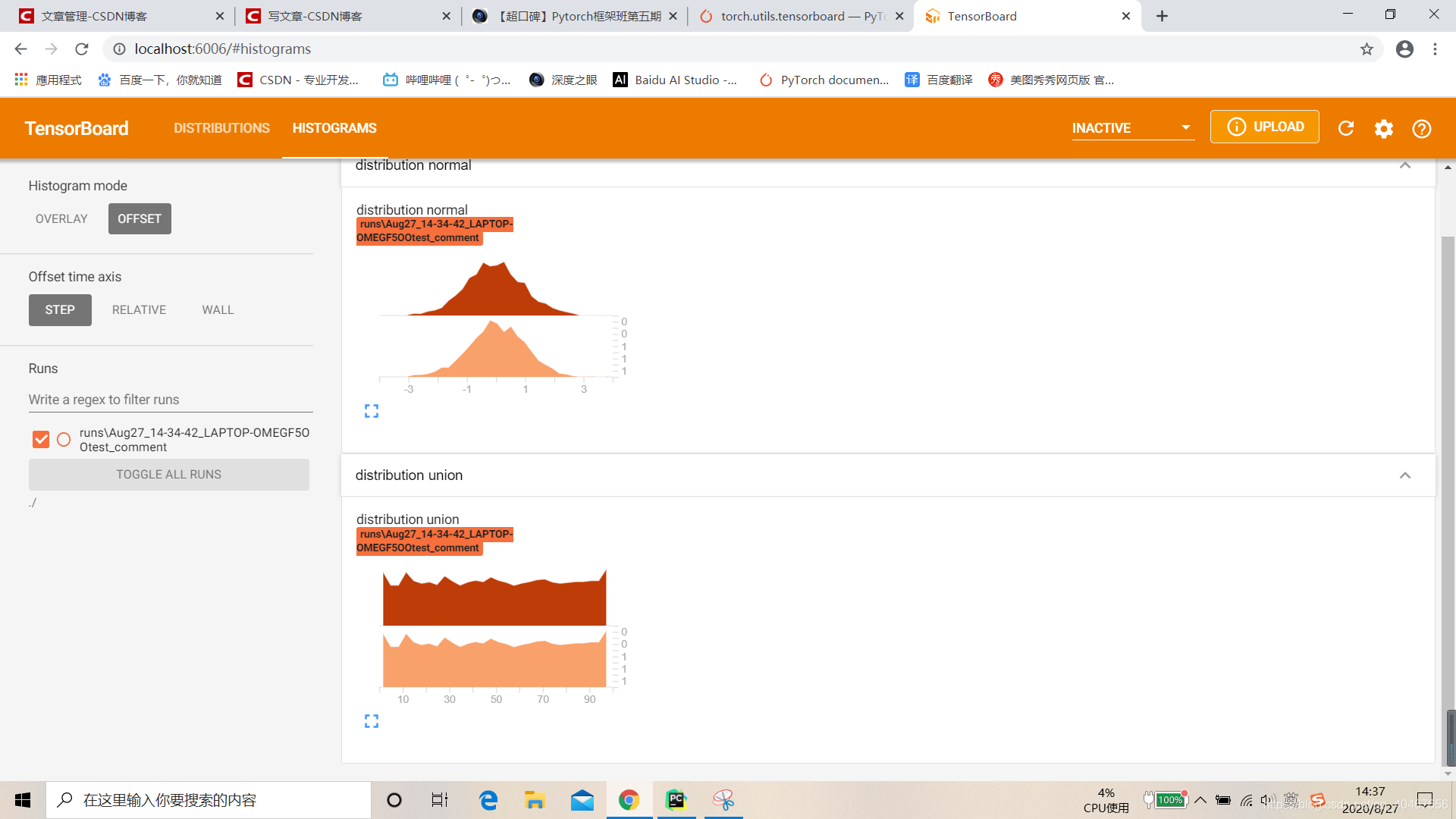
3.add_histogram()
功能:统计直方图与多分位数折线图。
add_histogram(self, tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
主要参数:
- tag:同上。
- values:要统计的参数。
- global_step:y轴。
- bins:取直方图的bins,一般用默认的’tensorflow’。
举例如下:
writer = SummaryWriter(comment='test_comment', filename_suffix="test_suffix")
for x in range(2):
np.random.seed(x)
data_union = np.arange(100)
data_normal = np.random.normal(size=1000)
writer.add_histogram('distribution union', data_union, x)
writer.add_histogram('distribution normal', data_normal, x)
writer.close()
可视化了一个正态分布和均匀分布:
4.add_image()
功能:记录图像,将CHW、HWC或HW格式的图像可视化。
add_image(self, tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
主要参数:
- tag:同上。
- img_tensor:图像数据,注意尺度。
- global_step:x轴。
- dataformats:数据形式,CHW、HWC或HW。
需要注意的是img_tensor这个参数,当输入图像的像素全都小于等于1时,会自动将所有像素值乘255,若有大于1的,则保持不变。
举例:
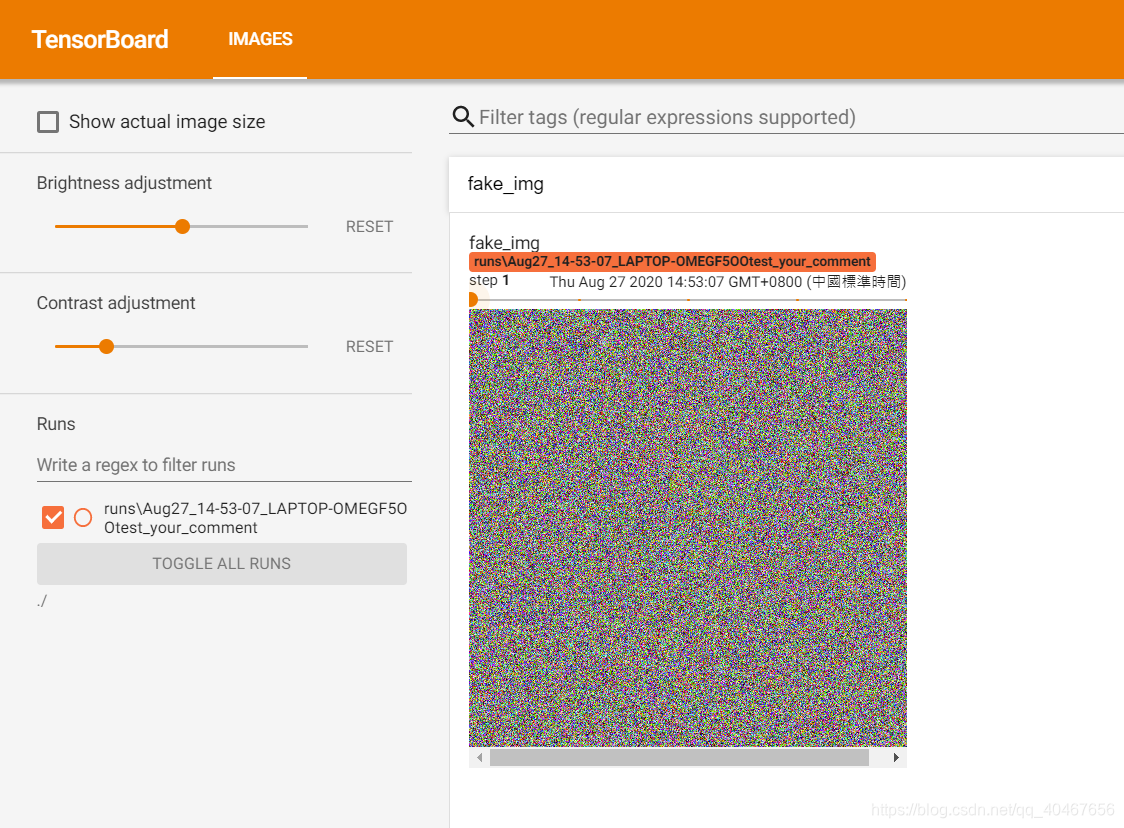
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# img 1 random
fake_img = torch.randn(3, 512, 512)
writer.add_image("fake_img", fake_img, 1)
time.sleep(1)
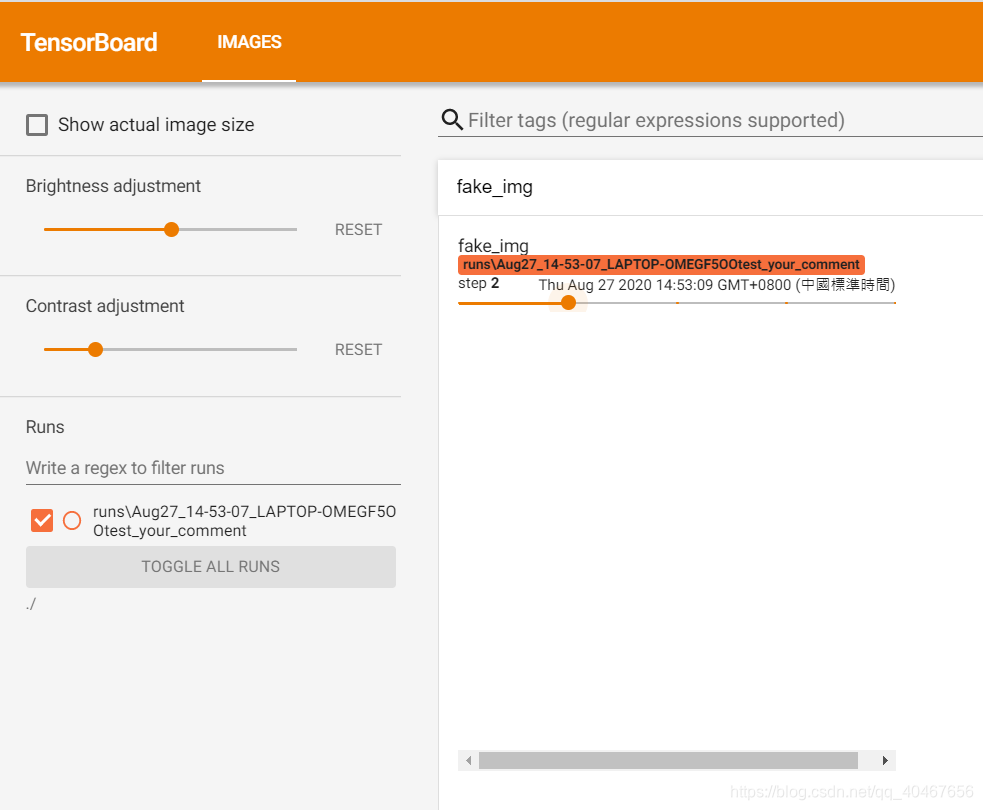
# img 2 ones
fake_img = torch.ones(3, 512, 512)
time.sleep(1)
writer.add_image("fake_img", fake_img, 2)
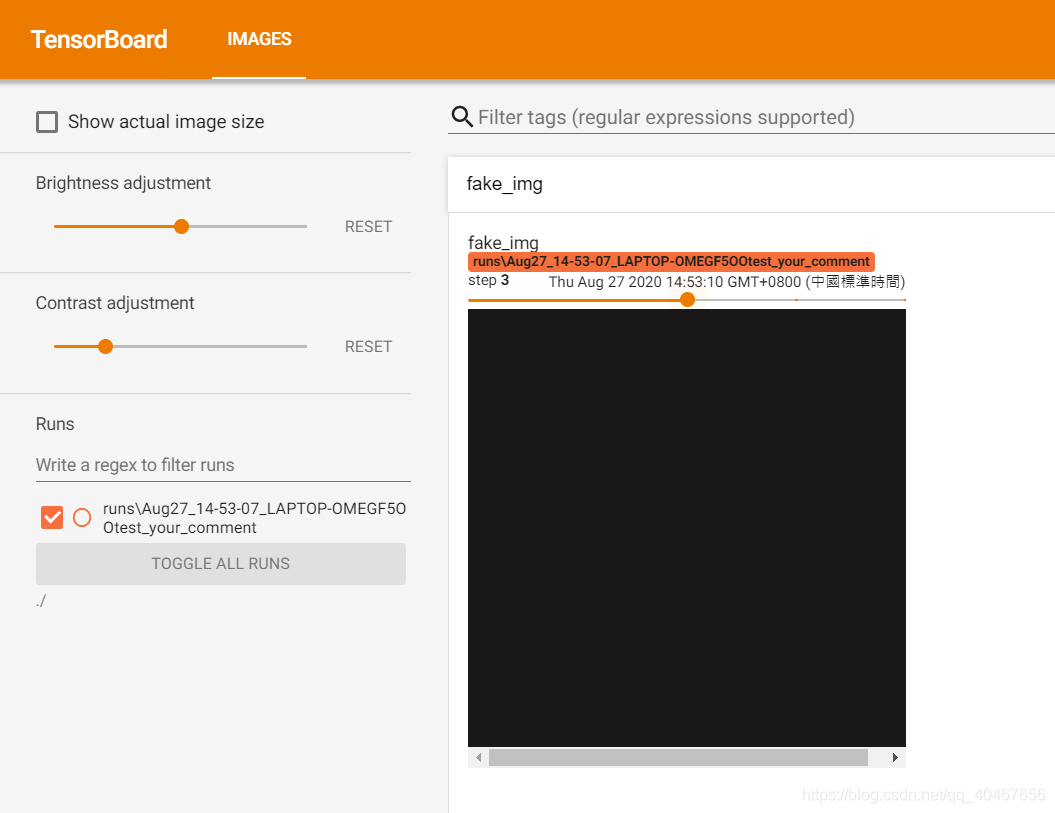
# img 3 1.1
fake_img = torch.ones(3, 512, 512) * 1.1
time.sleep(1)
writer.add_image("fake_img", fake_img, 3)
# img 4 HW
fake_img = torch.rand(512, 512)
writer.add_image("fake_img", fake_img, 4, dataformats="HW")
# img 5 HWC
fake_img = torch.rand(512, 512, 3)
writer.add_image("fake_img", fake_img, 5, dataformats="HWC")
writer.close()
这里构造了五张图片,第一张是随机产生的三通道图像,第二张是像素值全为1的三通道图像,第三张为像素值全为1.1的三通道图像,第四张为像素值全都小于1的灰度图像,第五张为像素值全都小于1的三通道图像,只是通道数在最后一维,结果如下图所示:
第一张:
第二张,像素值全乘了255,1×255即全为255,显示全白:
第三张,像素值全为1.1,超过了1,不乘255,因为像素值太小,显示接近全黑:
第四张:
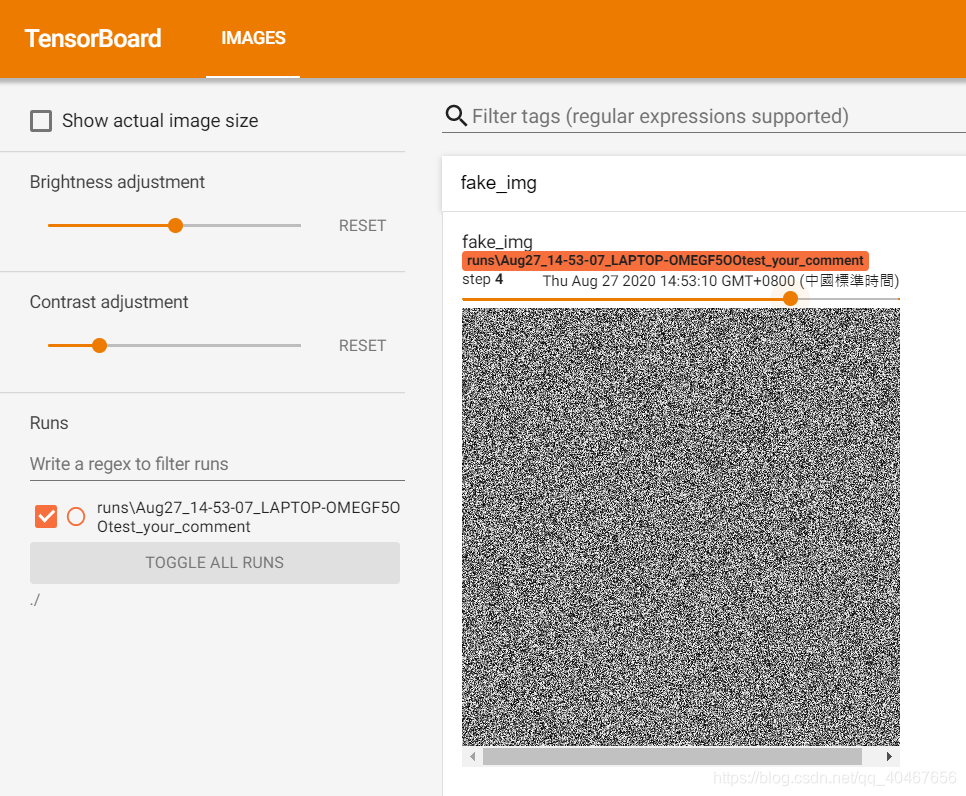
第五张:
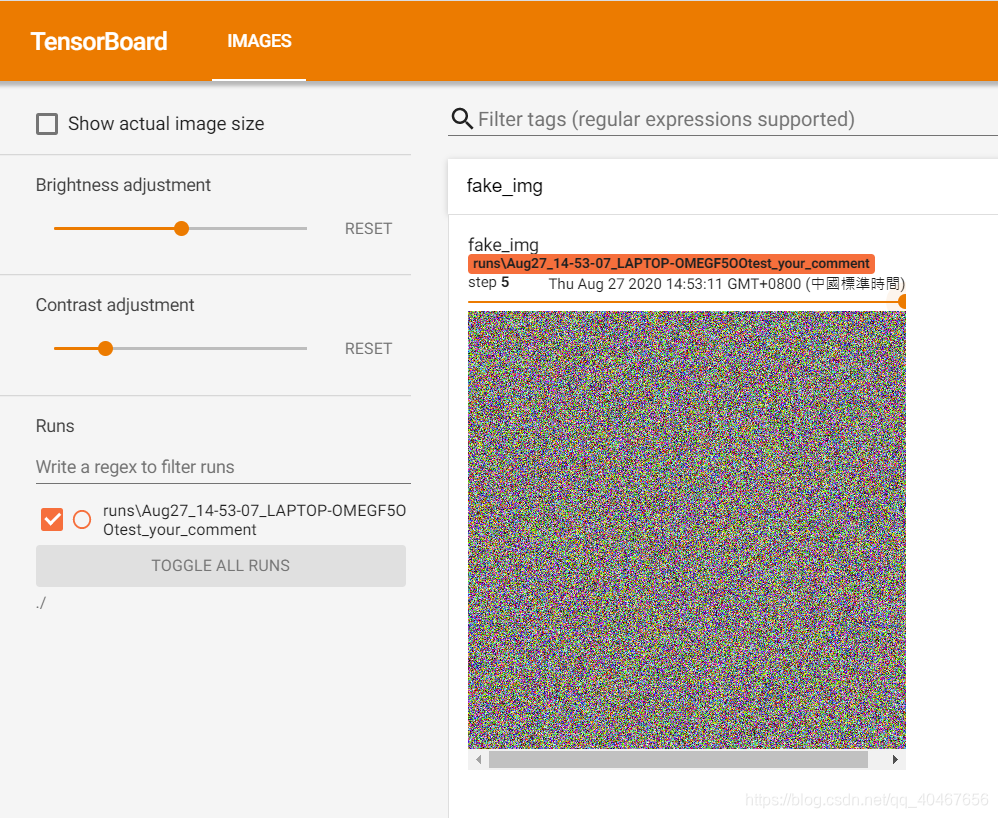
但是add_image单独使用的话有个缺点,就是图像只会排成一行,一次显示一张,通过拖动下面这个东西来切换不同的图像,非常麻烦:

所以接下来介绍torchvision.utils.make_grid,使用它制作网格图像再使用add_image进行显示。
make_grid(tensor, nrow=8, padding=2,
normalize=False, range=None, scale_each=False, pad_value=0)
功能:制作网格图像。
主要参数:
- tensor:图像数据,BCHW格式。
- nrow:行数,列数通过行数自动计算。
- padding:图像间距(像素单位)。
- normalize:是否将像素值标准化。
- range:标准化的范围。
- scale_each:是否单张图维度标准化。
- pad_value:padding的像素值,默认为0(黑色)。
举例:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
# train_dir = "path to your training data"
transform_compose = transforms.Compose([transforms.Resize((32, 64)), transforms.ToTensor()])
train_data = RMBDataset(data_dir=train_dir, transform=transform_compose)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data_batch, label_batch = next(iter(train_loader))
# img_grid = vutils.make_grid(data_batch, nrow=4, normalize=True, scale_each=True)
img_grid = vutils.make_grid(data_batch, nrow=4, normalize=False, scale_each=False)
writer.add_image("input img", img_grid, 0)
writer.close()
data_batch是我自己构造的一个包含了16张人民币图像的张量,行数为4,padding和pad_value都用默认,normalize和scale_each都为False,然后将构建好的网格图像送入add_image,显示结果如下所示:
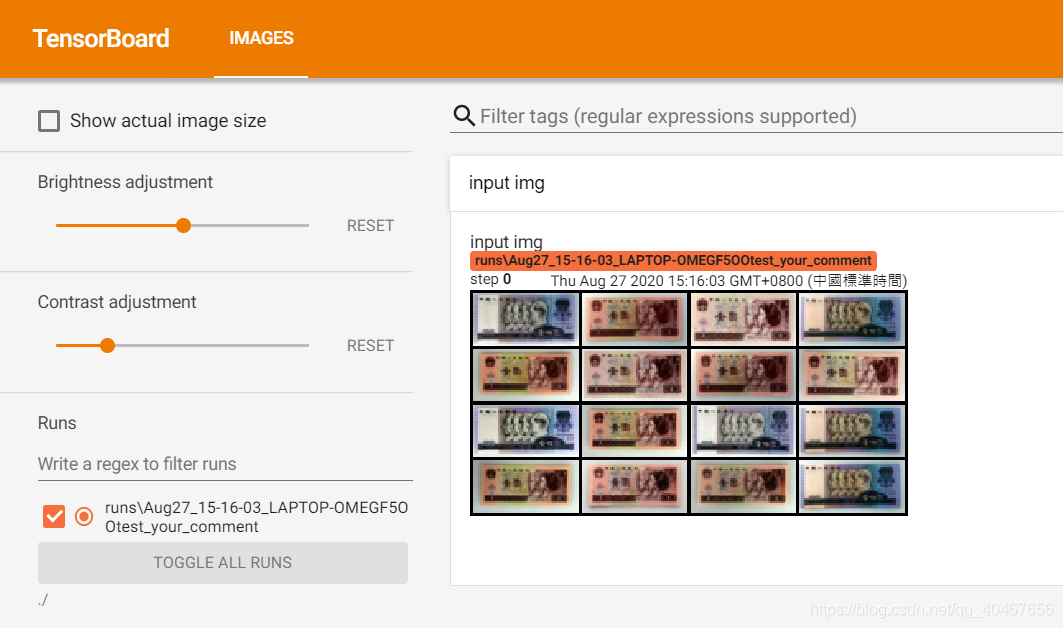
这样一次性全部显示要比拖动来的更为直观。
5.add_graph()
功能:可视化模型计算图(数据流方向),通常观察模型结构。
add_graph(self, model, input_to_model=None, verbose=False)
主要参数:
- model:模型,必须是nn.Module。
- input_to_model:输入给模型的数据。
- verbose:是否打印计算图结构信息。
举例:
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
# 模型
fake_img = torch.randn(1, 3, 32, 32)
lenet = LeNet(classes=2)
writer.add_graph(lenet, fake_img)
writer.close()
from torchsummary import summary
print(summary(lenet, (3, 32, 32), device="cpu"))
绘制出了计算图:
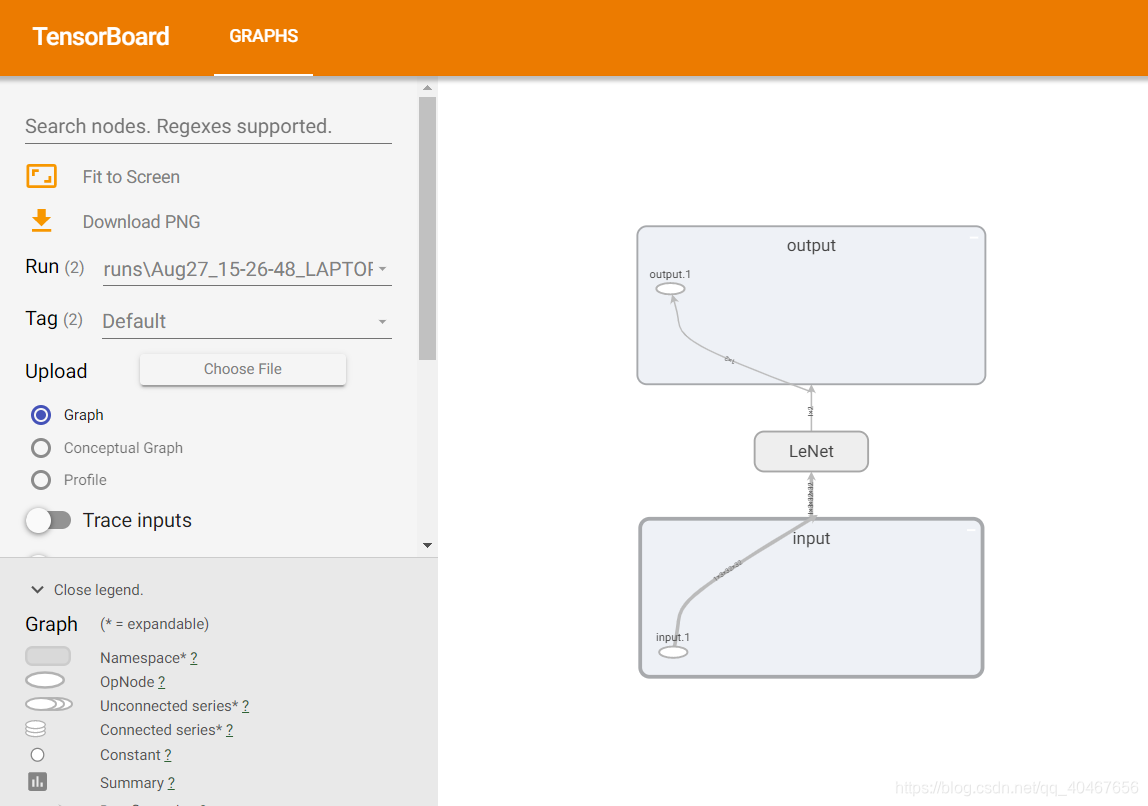
也可以查看LeNet的内部结构:

但是直接分析计算图是比较复杂的,这里还给出了一个更直观的包 torchsummary ,其中的summary函数可以总结出每一层网络层的输出尺寸、参数量以及占用多少内存等关键信息,上述LeNet的信息如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 456
Conv2d-2 [-1, 16, 10, 10] 2,416
Linear-3 [-1, 120] 48,120
Linear-4 [-1, 84] 10,164
Linear-5 [-1, 2] 170
================================================================
Total params: 61,326
Trainable params: 61,326
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.23
Estimated Total Size (MB): 0.30
----------------------------------------------------------------
None
torchsummary
功能:查看模型信息,便于调试。
summary(model, input_size, batch_size=-1, device="cuda")
主要参数:
- model:PyTorch模型。
- input_size:模型输入size。
- batch_size:就是字面意思。
- device:‘cuda’ 或 ‘cpu’















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









