









 GQA数据集由CVPR 2019提出,旨在克服传统VQA数据集的局限性,如语言先验和推理能力不足。该数据集通过复杂的构造流程,包括场景图生成、问题生成和答案偏差调整等步骤,最终包含2200多万个问题和11万多张图片,涵盖丰富的词汇和答案类型。GQA不仅提供了图像、问题和答案,还提供了详细的场景图和问题的功能表示。
GQA数据集由CVPR 2019提出,旨在克服传统VQA数据集的局限性,如语言先验和推理能力不足。该数据集通过复杂的构造流程,包括场景图生成、问题生成和答案偏差调整等步骤,最终包含2200多万个问题和11万多张图片,涵盖丰富的词汇和答案类型。GQA不仅提供了图像、问题和答案,还提供了详细的场景图和问题的功能表示。
GQA数据集是由2019年CVPR的一篇论文提出的,今年CVPR发表的好几篇论文的研究工作都是在GQA数据集上开展的,所有挺有必要了解一下的。论文中有数据集创建的详细过程,这里不多介绍,而是主要介绍一下这个数据集的特点和它的数据表示形式。
论文链接:CVPR 2019 Open Access Repository
数据集下载地址:GQA: Visual Reasoning in the Real World
背景

以往的VQA数据集总是被大家诟病存在各种缺陷,该文章就罗列了其中的几个问题:第一是,数据集总是存在明显的语言先验,比如说,当问及的一个桌子的材料的时候,答案十有八九是木头。这样一来,模型只需要学会挖掘训练数据的统计规律就能很好地回答问题,而不需要准确地理解场景;第二点是,数据集中的大多数问题没有用到组合式的语言,从而仅仅测试了模型的物体识别能力,模型缺乏基于视觉的推理能力。比如说,上图这个问题包含很多的对象和一些关系,这种组合式的问题对VQA模型来说是很难的,原先数据集压根儿就无法训练模型的推理能力;第三是,以前的数据集缺乏将问题中的关键词与图中的对应区域相联系的标记信息,这使得研究者难以定位出模型出错的原因。
为了解决以上这些问题,本文就构造了GQA数据集,用于真实世界图像推理和组合问题回答。
GQA数据集构造流程
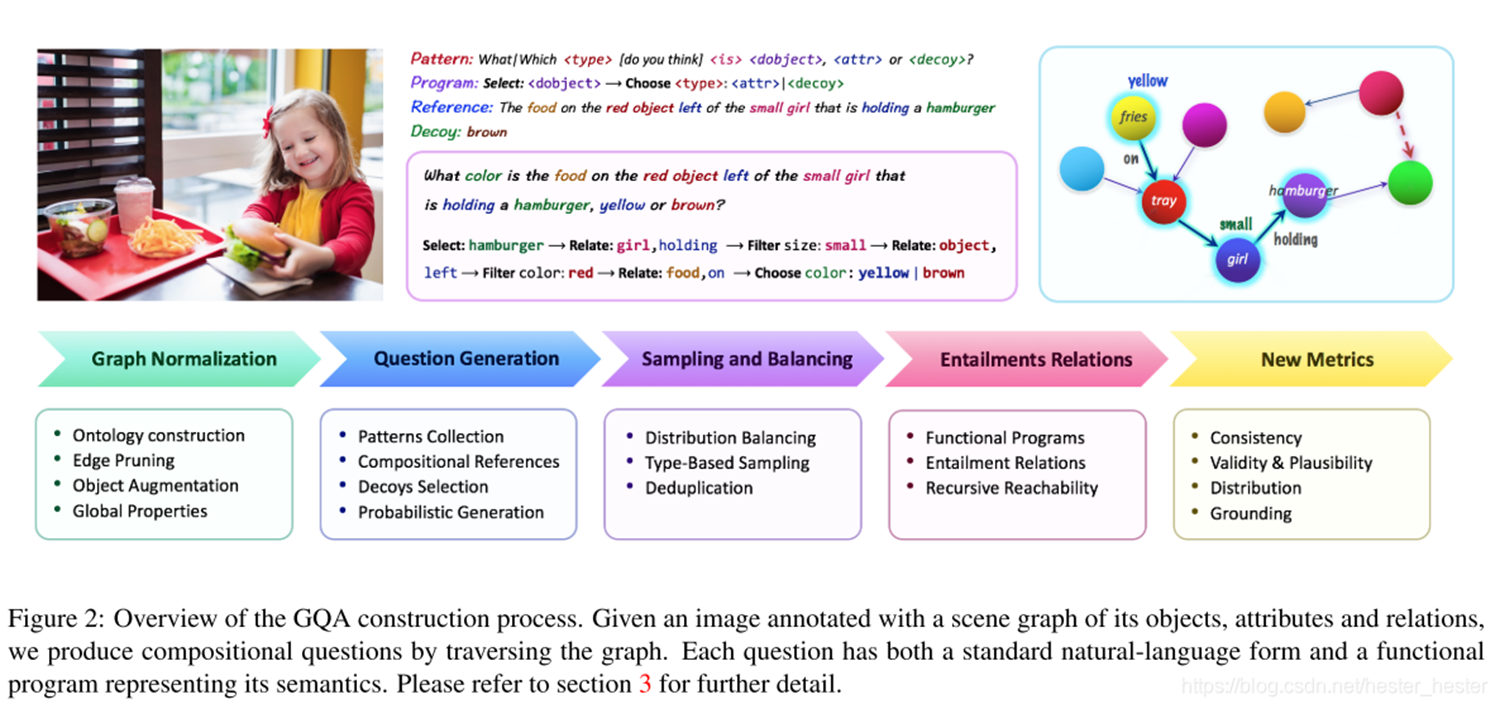
GQA数据集按照图中这些流程进行构造,构建的流程和细节非常多非常复杂,大的流程主要有四步:
(1)获取每张图像的场景图(这一步用的另一个数据集:Visual Genome数据集的研究成果);
(2)遍历图中的对象,对象的属性以及对象之间的关系,生成语义丰富且多样的问题;
(3)减少答案分布的偏差,从而得到一个平衡的数据集;
(4)讨论问题功能表示(functional representation),我的理解就是给出回答一个问题的所需要的推理步骤。
最终构建好的数据集包含22,669,678个问题和113,018张图片,要想回答这些问题,需要模型具有多种的推理技巧和推理步骤。(数据集中覆盖的词汇量有3,097个,答案类型有1,878个,虽然这个数据量比自然语言里面的问答数据集的数据量要少,但是在VQA任务中覆盖面已经较为广泛了。)
GQA数据表示形式
GQA数据集官网/下载地址在此处。

GQA数据集由三个部分组成:场景图、问题和图像。场景图包含了训练集和验证集中每一张图像的场景图信息;问题包含了回答这个问题所需要的一些推理步骤;图像这个文件夹下面除了有图片,还储存了每张图像中包含的所有对象的特征和储存了每张图像的空间特征。
allImages


对象特征和全局空间特征都存储在h5文件中。每张图像的空间特征是用Resnet-101提取的2048*7*7维度的向量。每张图像里面的对象特征用faster rcnn提取,并限制最多有100个对象,提取出来的特征是一个2048长度的一维向量,同时另外还保存了每个对象的bounding box的信息。
场景图
然后看场景图的表示形式。场景图信息都存在json文件里,一张图像的场景图包含了这个表里面的这些信息:图片的长、宽、拍摄地点、天气、图像里面的目标,目标的属性、目标的位置和关系等等。


这里我可视化了两张图片的场景图信息,左边这两张图标注的是图中对象的位置和类别信息,右边打印了对象的ID,属性,以及它和其他对象之间的关系,比如:吸管是白色的、塑料的,在香蕉的左边。
问题


对于问题信息的标注,GQA数据集针对每个问题都标注了上述表中这些信息,除了包含必须要有的图片id、问题和答案,这里还有问题分组信息、问题类型、语义信息、回答该问题的推理过程等。这里面很多的参数其实是在构建数据集的时候使用的,比如说用于控制数据分布均衡。

我们训练模型时要用的主要是问题、图像id和答案这三个参数。但是如果要研究VQA模型的推理过程和鲁棒性,这三个参数显然是不够的,所以这个数据集还标注了一个语意结构的信息。比如说要从上面图像推理得到问题的答案,第一步就是先在图片中选择蔬菜,第二步判断是否存在,然后选择坚果,判断是否存在,最后进行一个“或”的逻辑判断。

关于GQA更详细的信息,比如数据集构造过程、数据分布等等,请看原论文~
参考文献
[1] Hudson D A, Manning C D. Gqa: A new dataset for real-world visual reasoning and compositional question answering[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 6700-6709.

















 1316
1316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









