






一、目标检测
1.传统目标检测问题
机器视觉的任务:语义分割、图像分类、图像定位、目标检测(where&what)、目标跟踪、实例分割、(其他:图像标注、图像生成、超分辨率、着色、风格迁移、显著性检测、行为识别、人体姿态估计、场景理解)
目标检测是在给定的图片中精确找到物体所在位置where——标定,并标注出物体的类别what——分类,输入是图像输出则是带有标签的边界框。

传统目标检测的流程包括三个部分:目标区域选择——特征提取——分类器分类;目标区域的选择采用的是滑动窗口,即采用一个标准框在图上从左到右从上到下滑动,不仅要遍历位置还要遍历滑窗的尺寸以实现不同大小目标的识别。下图可以看出有许多没有目标的冗余框,当目标较小图片本身很大时,花费的时间较多。传统目标检测的输入是图片,输出为带有onehot编码的边界框,这种传统的滑窗本质是前景目标和背景的识别的二分类问题。

特征提取是通过人工提取器例如SIFT角点检测和HOG,这些特征提取方法鲁棒性差,质量不高。OpenCV入门学习笔记之Harris角点检测与SIFT特征匹配算法_角点检测算法入门-CSDN博客;OpenCV3特征提取与目标检测之HOG(一)——HOG的概述与原理_hog特征提取-CSDN博客;分类器一般采用SVM、AdaBoost的分类器。
2.YOLOv1(You Only Look Once)

为了改进滑动窗口中大量冗余窗口的方法,R-CNN提出用两步法,即首先找到目标可能的所在区域,再对特定区域采用CNN进行目标分类;在此基础上提出了Fast R-CNN和Faster R-CNN,这种方法耗时依然很长,YOLO框架的提出实现采用一步即可同时实现目标定位和目标分类,精度高耗时少。
假设一张图中只有一个目标,YOLO将这目标检测转换为有监督的分类问题,对于训练集中的图片都设置标签(1,x’,y',w',h'),1代表有目标;输入图片输出为目标类别和目标的边界框——(c,x,y,w,h)5维的向量,c为有无目标的置信度。输出边界框(bounding box,bb)如下图。边界框常用的位置表示方式有三种:(1)左上角坐标x,y+右下角坐标x,y(2)左上角坐标x,y,宽w高h(3)中心坐标x,y+w,h 都是四个维数据,在实际应用中这些数值要进行归一化,加快模型收敛。
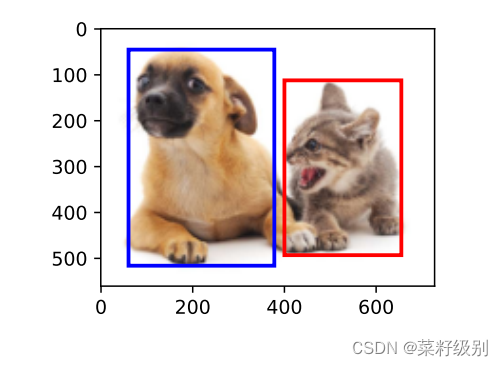
当图片中有多个目标时,为了实现you only look once,YOLO提出将一张图片划分为小块cell,对每个小块进行目标检测。这种划分可以实现每个cell下仅有一个目标,对于一个cell下检测到两个目标或者目标过程小时,划分过多的cell本身不现实,针对这些问题:两者大概率是同一个目标这是采用非极大值抑制NMS;如果是小目标增加一组新的检测网络;对于多类目标再增加一组用于类别识别的onehot编码例如三类是:001,010,100。

NMS非极大值抑制:对于两个相似度很高的识别框认为识别为同一个目标,这时采用非极大值抑制,衡量二者相似的标准即IOU,IOU是预测的bb和真实的物体位置的交并比,如下图。
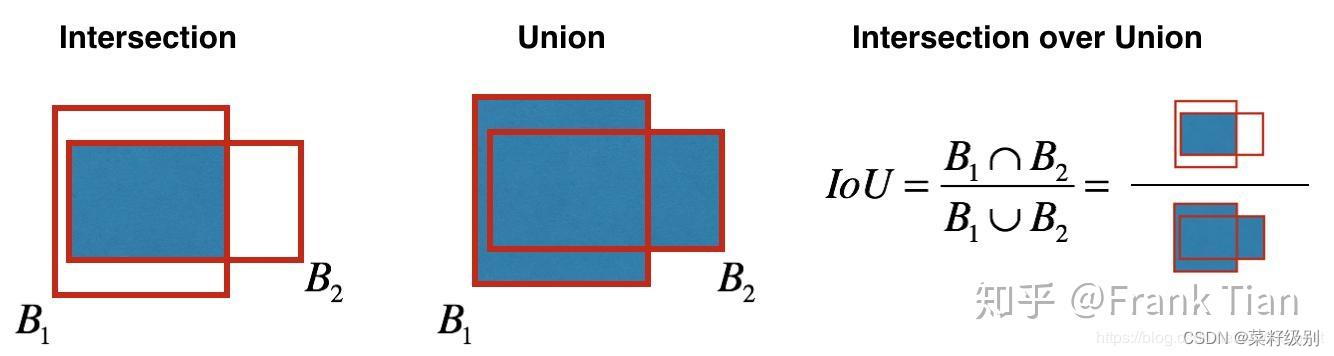
NMS算法要点:首先丢弃概率小于预定IOU阈值(例如0.5)的所有边界框;对于剩余的边界框:(1)选择具有最高概率的边界框并将其作为输出预测;(2)计算 “作为输出预测的边界框”,与其他边界框的相关联IoU值;(3)舍去IoU大于阈值的边界框;其实就是舍弃与“作为输出预测的边界框” 很相近的框;(4)重复步骤以上步骤直到所有边界框都被视为输出预测或被舍弃。
网络结构
在YOLO中,原始图片被分割为不同的小块,每个小块cell有两个bb,在YOLOv1中原始图片分为7*7,这样有7*7*2个bb,YOLO输入的图片维度为448*448*3,输出为7*7*30。


YOLO输出7*7*30维度解读:训练集是20类,有20维度显示目标属于各类的概率;每个bb输出为5(bb位置4维+检测到目标的置信度c),一个格有两个bb;20+5*2=30.
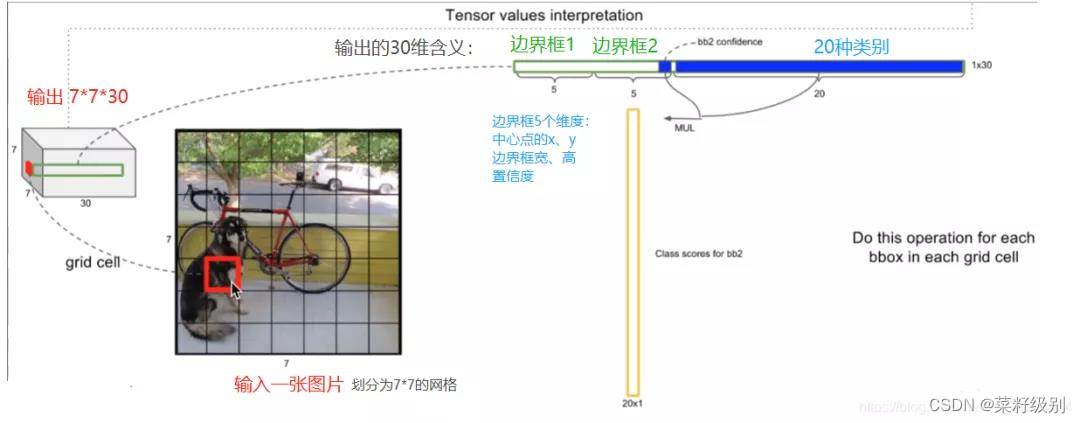
YOLOv1结构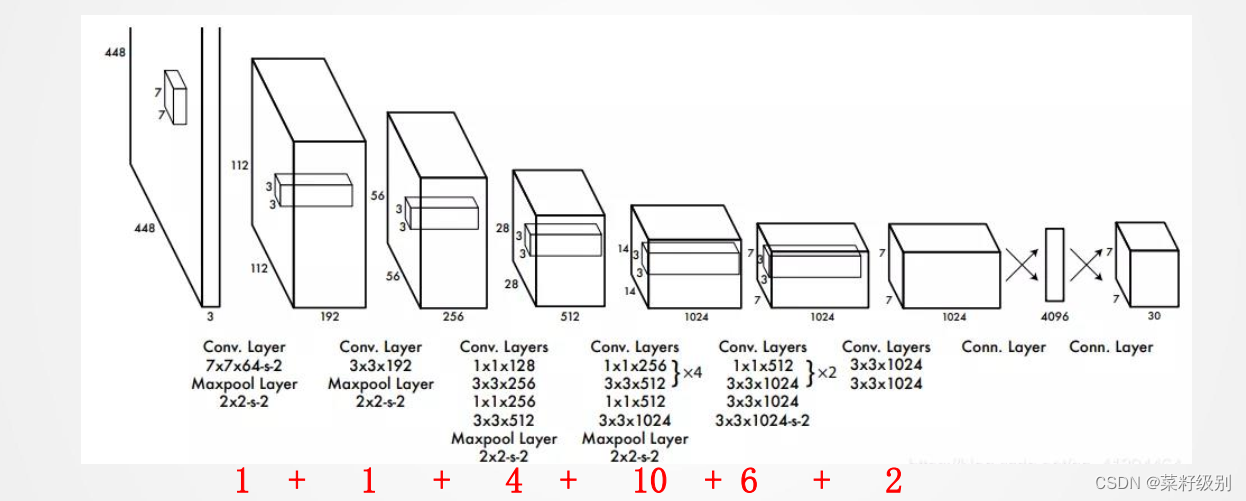
24层卷积+pooling和2个全连接层,其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层。
评价指标
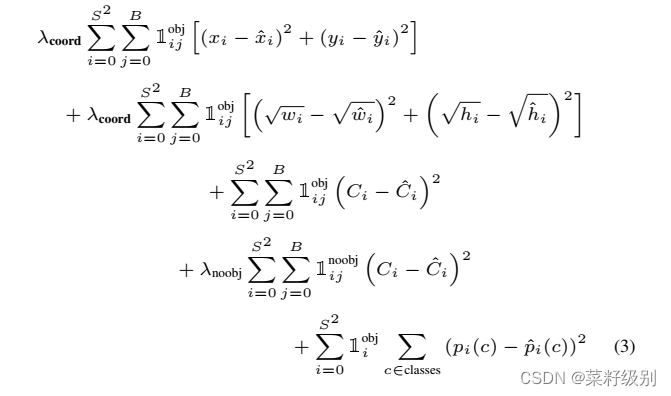
说明:S为划分的cell细度,B为每个cell有几个bb;有五项,每一项都有一个标识,检测到目标时为1,无目标时为0;为了只有在检测到目标时才进行计算;前两项为对目标位置的评估, 第二项开根号的原因考虑不同的锚框大小对于误差的灵敏度(因为不开根号误差是大框偏移量大,小框偏移量小)。第三四项分别为有目标区域的置信度预测误差和没有目标区域的置信度预测误差,最后一项即为对目标分类的预测概率误差。

模型训练

3.YOLOv3
假设有 个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆 × 𝑆 × (𝐵 × 5 + 𝐶),YOLO v1中,输出数量是30,YOLO v2和以后版本使用了自聚类的anchor box为bb, v2版本为𝐵 = 5, v3中𝐵 =9。YOLOv2开始引入了锚点机制和多尺度检测,提高了模型对不同大小目标的检测能力。
anchor box锚框:“这个概念最初是在Faster R-CNN中提出,此后在SSD、YOLOv2、YOLOv3等优秀的目标识别模型中得到了广泛的应用。”锚框是以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。“为什么提出 Anchor Box ?以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别”本质即在图像上预设好的不同大小,不同长宽比的参照框。
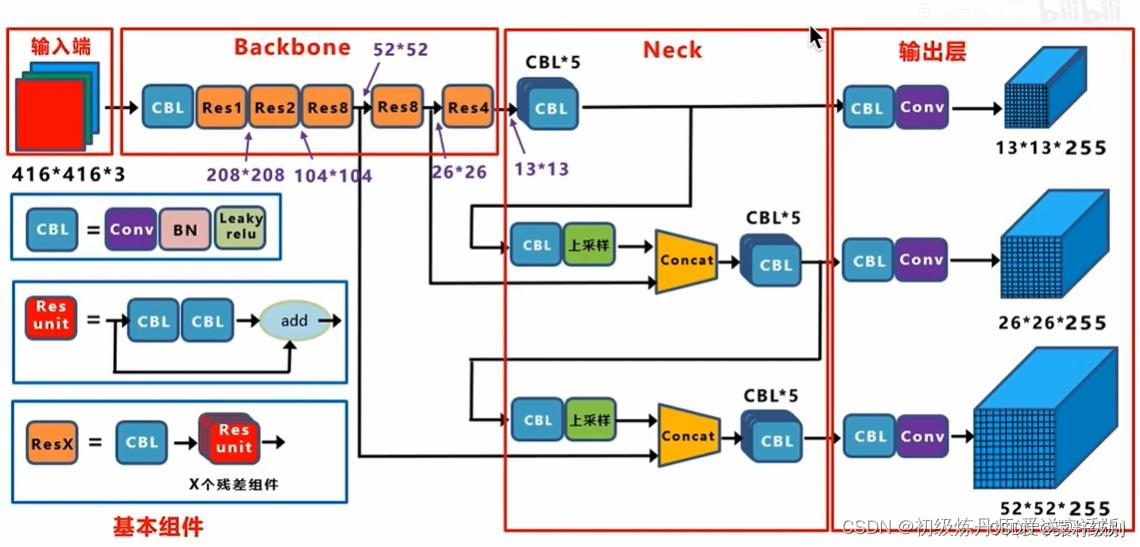
YOLOv3网络结构
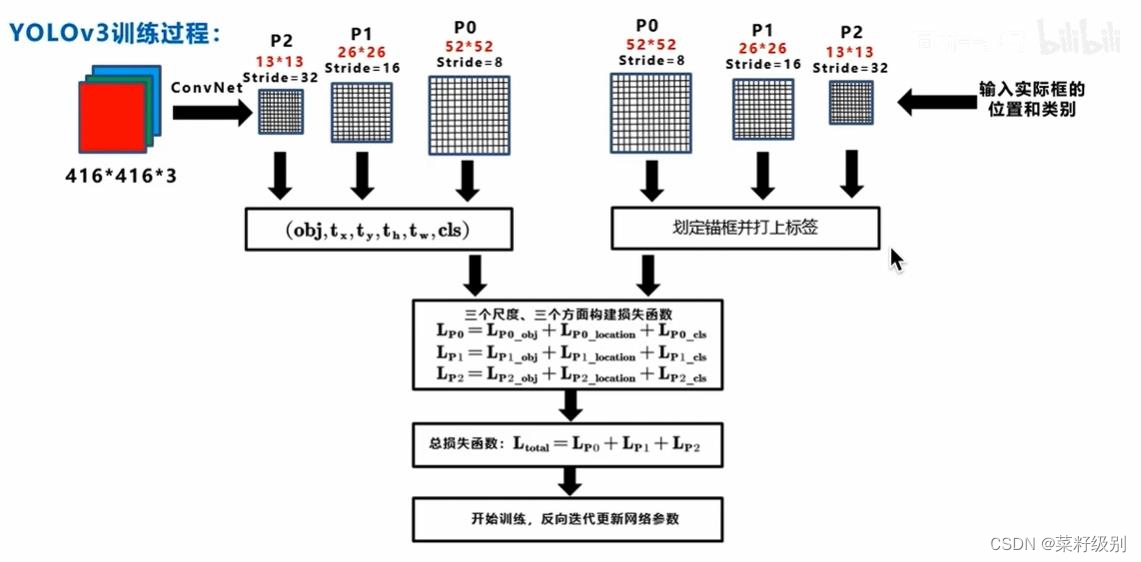
为预测不同尺度的目标将图片分成13x13个cell26x26个cell以及52x52个cell(32倍下采样,16倍下采样,8倍下采样,分别取预测大,中,小目标),每个cell生成三个预测框(anchor),维数为85 = 5 + 80;对一个图像产生10647个预测框:3 × (13 × 13 + 26 × 26 + 52 × 52)。
损失函数

模型训练
4.YOLOv5
网络结构

改进
1.预测框更细的划分:对一个图像产生25200个预测框:3 × 20 × 20 + 40 × 40 + 80 × 80;根据不同的数据集来自适应计算不同训练集中的最佳锚框值。
2.回归损失采用CIOU 损失

3.数据预处理阶段
(1)数据增强:𝑌𝑜𝑙𝑜𝑣5的输入端采用了和𝑌𝑜𝑙𝑜𝑣4一样的𝑀𝑜𝑠𝑎𝑖𝑐数据增强的方式, 采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接,使模型在更小的范围内识别目标。(2)Focus结构:进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片(4个通道),一共12个通道(RGB)。
二、语义分割
1.基本概念
语义分割即找到图片中所属同一目标的全部区域并分割出边界,即图像分割。其基本思想是 对图中每一个像素进行分类,得到对应标签。

发展历程:
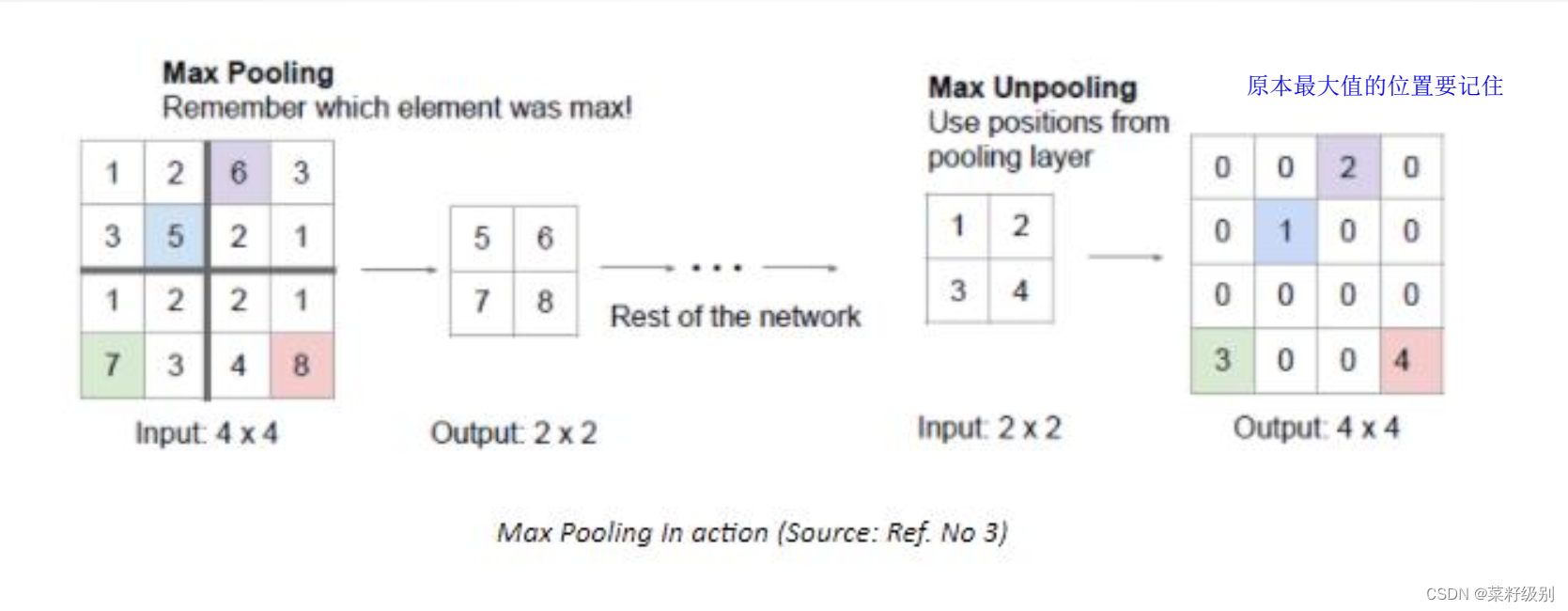
反卷积和反池化:
反卷积又称为转置卷积,相对于原来的卷积操作现在将输入看作卷积核,卷积核看作输入进行计算



反池化unpooling
2.FCN网络

FCN(Fully Convolutional Networks,全卷积网络)结构分为两个部分:全卷积部分和反卷积部分。全卷积部分借用了一些经典的CNN网络,并把最后的全连接层换成卷积,用于提取特征,形成热点图;反卷积部分则是将小尺寸的热点图上采样得到原尺寸的语义分割图像。图中蓝色是卷积层;绿色为Max Pooling层;黄色为求和运算;灰色: 裁剪。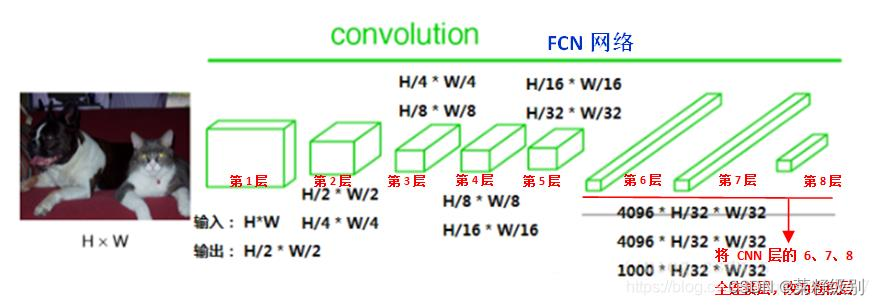 FCN中第6、 7、 8层都是通过1 × 1卷积得到的, 第6层的输出通道是4096, 第7层的输出通道是4096 , 第8层的输出是1000(类) ,即1000个特征图(称为heatmap)。
FCN中第6、 7、 8层都是通过1 × 1卷积得到的, 第6层的输出通道是4096, 第7层的输出通道是4096 , 第8层的输出是1000(类) ,即1000个特征图(称为heatmap)。
3.评价指标

参考【YOLO系列】--YOLOv1超详细解读/总结_yolov1提出论文-CSDN博客通俗易懂的YOLO系列(从V1到V5)模型解读! (qq.com)人工智能 - 目标检测:发展历史、技术全解与实战_目标检测 使用的人工智能技术 怎么写-CSDN博客目标检测(Object Detection)-CSDN博客Yolo V1、V2目标检测系统【详解】看不懂就在评论区diss我好吗_yolov1-CSDN博客















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









