







排序算法
冒泡排序

冒泡排序是所有排序算法中效率最低的,原因是数据交换次数太多
平均时间复杂度O(n^2),空间复杂度O(1)
冒泡排序是一个稳定排序
(稳定性:在原始的数据序列中,相同元素经过排序后,它们的前后顺序并没有发生改变,就叫做稳定的,否则叫做不稳定的排序。 稳不稳定没有绝对的好坏,主要看应用场景!! )
优化:一趟下来没有发生交换,说明已经排好序了,不需要再进行排序
#include <iostream>
using namespace std;
// 冒泡排序(从小到大)
void BubbleSort(int arr[], int size)
{
for (int i = 0; i < size - 1; ++i)// 趟数,这里从0开始
{
bool flag = false;
// 一趟的处理
for (int j = 0; j < size - i - 1; ++j)
{
if (arr[j] > arr[j + 1])
{
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = true;
}
}
// 一趟走完没有发生交换,则表明已完成排序,直接跳出循环
if (!flag)
return;
}
}
int main()
{
int arr[10];
srand(time(NULL)); // 随机数种子
// 随机数
for (int i = 0; i < 10; i++) {
arr[i] = rand() % 100 + 1;
}
for (int v : arr)
cout << v << " ";
cout << endl;
int size = sizeof(arr) / sizeof(arr[0]);
BubbleSort(arr, size);
for (int v : arr)
cout << v << " ";
cout << endl;
return 0;
}
选择排序
基本思路:每一趟找到本趟中最小(最大)的元素,然后与本趟的起始位置元素交换
性能分析:
-
与冒泡相比,交换次数减少了很多,每趟主要是进行比较,所以效率比冒泡高
-
选择排序是一个不稳定的排序算法(例如:对 5 5 3 进行排序)
-
平均时间复杂度O(n^2),空间复杂度O(1)
#include<iostream>
using namespace std;
void ChoiceSort(int arr[], int size)
{
// 从小到大排序
for (int i = 0; i < size - 1; ++i) // 趟数
{
int min = arr[i]; // 用本趟的起始元素初始最小值min
int k = i; // 记录本趟最小值的下标
for (int j = i+1; j < size; ++j)
{
if (min > arr[j])
{
// 更新min和k
min = arr[j];
k = j;
}
}
if (k != i)
{
//交换
int tmp = arr[i];
arr[i] = arr[k];
arr[k] = tmp;
}
}
}
插入排序
基本思想:假设第一个元素为一个有序序列,从第2个元素开始往前插入,保证插入后的序列依然有序
性能分析:
-
如果数据趋于有序,那么插入排序是所有排序算法中效率最高的排序算法!
-
排序过程中没有进行数据交换,比较次数也比较少
-
插入排序是一个稳定排序
-
最坏/平均时间复杂度:0(n^2); 最好时间复杂度:O(n)
-
空间复杂度:O(1)
void InsertSort(int arr[], int size)
{
// 从小到大排序
for (int i = 1; i < size; ++i) // 假定第一个元素有序,从第二个元素开始依次往前插入
{
int val = arr[i]; // 记住当前要进行插入的元素
int j = i - 1;
for (; j >= 0; --j)
{// 将要插入的元素与前面的有序序列,从后向前进行比较,目的是找到第一个<=val的元素
if (arr[j] <= val)
{// 从后往前找,找到第一个比val要小的元素
break;
}
arr[j + 1] = arr[j];// 将比较过的值往后移动,以腾出空间便于val的后续插入
}
// 在第一个<=val的元素后面插入val
arr[j + 1] = val;
}
}
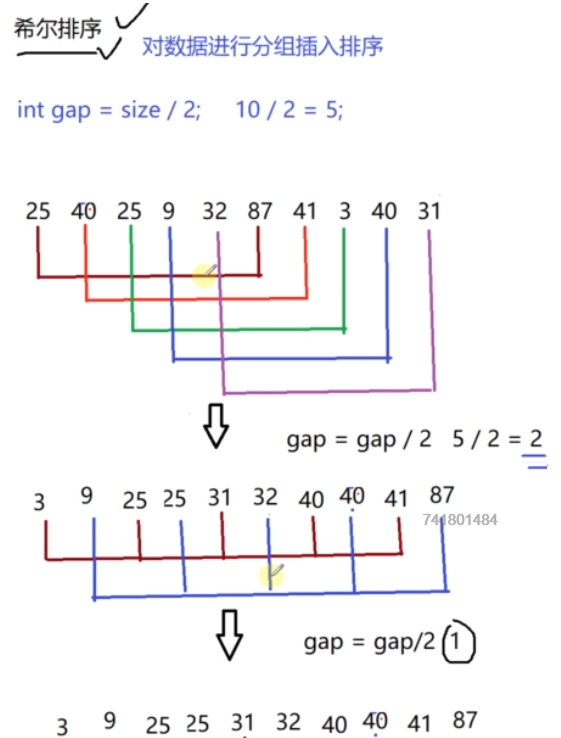
希尔排序
基本思路:希尔排序是对插入排序的优化,分组进行插入排序,先从全局上让数据趋于有序
性能分析:
- 不稳定(在不同分组的情况下,发生移动可能导致相同元素的相对位置发生改变)
- 依赖不同的增量序列设置,最好时间复杂度:O(n); 平均时间复杂度可以达到O(n^1.3),空间复杂度O(1)
void ShellSort(int arr[], int size)
{
for (int gap = size / 2; gap > 0; gap /= 2)
{
for (int i = gap; i < size; ++i) // 注意这里依然是++
{
int val = arr[i];
int j = i - gap;
for (; j >= 0; j-=gap)
{
if (arr[j] <= val)
{// 从后往前找,找到第一个比val要小的元素
break;
}
arr[j + gap] = arr[j];
}
arr[j + gap] = val;
}
}
}

快速排序
基本思想:选取一个基准数,把小于基准数的元素都调整到基准数的左边,把大于基准数的元素都调整到基准数的右边,然后再对基准数的左边和右边继续采取相同的操作,直至整个序列变成有序的。(从小到大排序)
1. 选取基准数val = arr[L] (这里以第一个元素为基准数,注意用一个val变量记住基准数的值,避免被覆盖)
2. 从R开始往前找第一个小于基准数的数字,然后放到L的地方, L++
3. 从L开始往后找第一个大于基准数的数字,然后放到R的地方,R--
4. 重复上述步骤(循环条件L<R) 最终确定基准数的位置,然后再分别对基准数左侧和右侧指向上述同样的操作(分治思想)
性能分析:
-
不稳定排序
-
平均时间复杂度:O(n)*O(logn) = O(nlogn) , 每一层是O(n), 有logn层
-
平均空间复杂度: O(logn), 快排递归的深度,开辟的函数栈帧占用的内存
-
待排序序列趋于有序的时候,快排的性能就会降低
-
*最坏时间复杂度:O(n)O(n) = O(n^2), 空间复杂度:O(n)
快排算法的优化策略:
- 随着快排算法的执行,数据逐渐趋于有序,快排性能下降,而数据趋于有序时,插入排序的性能最好,所以在一定范围内可以采用插入排序来代替快排
- 采用“三数取中法”找合适的基准数
// 快排分割函数,确定基准数位置
int Partation(int arr[], int l, int r)
{
// 选取基准数
int val = arr[l];
while (l < r)
{
//1.从右往左找第一个小于基准数的数,把它移到基准数的位置
while (l < r && arr[r] > val)
{
r--;
}
if (l < r)
{//找到比val小的数
// 把数移到基准数的位置
arr[l] = arr[r];
l++;
}
//2.从左往右边找到第一个大于基准数的数,把它移动到r的位置
while (l < r && arr[l] < val)
{
l++;
}
if (l < r)
{//找到比基准数大的数
// 把数移到r的位置
arr[r] = arr[l];
r--;
}
}
//l和r都指向基准数的位置,把保存的基准数放到该位置
arr[l] = val;
return l;
}
//实现递归函数时只要横向思考一层的实现就可以了
void QuickSort(int arr[], int l, int r)
{
//l=r仅有一个元素
if (l >= r)
return;
/*
// 可以进行的优化
if (r - l <= 50)
{
// 插入排序
}
*/
//快速分割函数,确定基准数的位置
int pos = Partation(arr, l, r);
QuickSort(arr, l, pos - 1);
QuickSort(arr, pos + 1, r);
}
归并排序
递的过程是在缩小数据规模的规程,递到可以直接得出结果的程度
归的过程是在进行数据合并,从而达到排序的效果!
那么问题来了,归并排序需要递到何种程度?又该如何进行归呢?
(1) 递到数据序列一定是有序的时候,即序列只有一个元素的时候
(2) 归的过程就是将两个分别有序的序列合并成一个全局有序的序列,不断向上合并
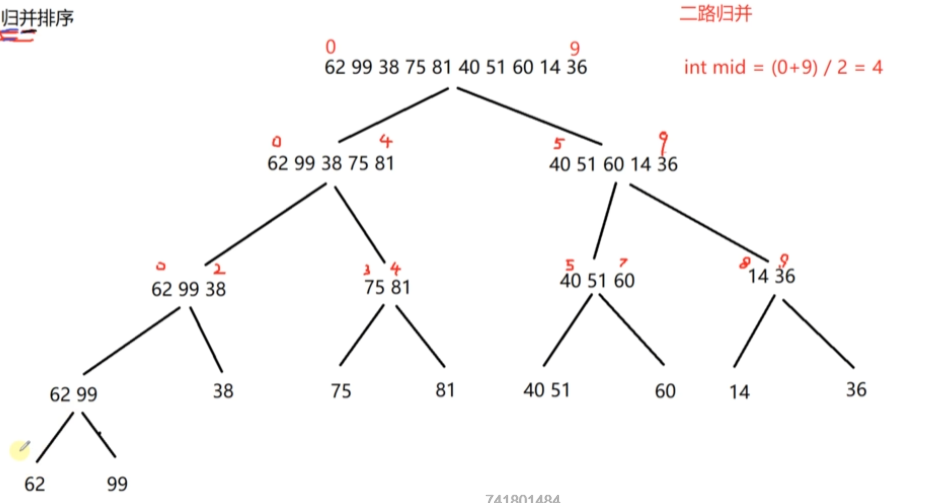
基本思想:采用分治思想,先对序列进行划分,再进行元素的有序合并
性能分析:
- 稳定排序
- 最好/最坏/平均时间复杂度:O(nlogn)
- 最好/最坏/平均空间复杂度:O(n) + O(logn) —> 取大值,即O(n) 【其中O(n)是额外开辟的数组,O(logn) 是递归过程开辟的函数栈帧占用的栈内存空间】
void Merge(int arr[], int begin, int mid, int end, int* p)
{
int i = begin; // 左侧序列的起始下标
int j = mid + 1; // 右侧序列的起始下标
int idx = 0;
while (i <= mid && j <= end)
{
if (arr[i] <= arr[j])
{
p[idx++] = arr[i++];
}
else
{
p[idx++] = arr[j++];
}
}
while (i < mid)
{
p[idx++] = arr[i++];
}
while (j < end)
{
p[idx++] = arr[j++];
}
//把调整好的有序数据拷贝到arr对应的位置
for (int i = begin, j=0; i < end; ++i,++j)
{
arr[i] = p[j];
}
return;
}
//递归实现归并排序
//比较完美的二叉树,层高logn,则递归调用logn次Merge,所以归并排序的时间复杂度O(nlogn)
void MergeSort(int arr[], int begin, int end, int* p)
{
//递过程的中止条件
if (begin >= end)
{
return;
}
//根据mid将数据分段,并向下递归执行分段操作
int mid = (begin + end) / 2;
MergeSort(arr,begin, mid, p);
MergeSort(arr, mid + 1, end, p);
//归并
//横向考虑代码,执行到这的时候,arr中[begin,mid],[mid+1,end]已经是两段有序的序列了
//O(n)
Merge(arr, begin, mid, end, p);
return;
}
// 对外部提供的函数
void MergeSort(int arr[], int size)
{
int* p = new int[size];//归并时需要使用的额外内存空间,空间复杂度O(n)
MergeSort(arr, 0, size - 1, p);
delete[]p;
return;
}
堆排序
二叉堆知识点
- 二叉堆逻辑上是一棵完全二叉树,存储方式上依然是用数组进行存储
(完全二叉树:除了最后一层,其他每一层都必须是满的,且最后一层的节点都是靠左边排列的,不能漏掉)
-
满足0 <= i <= (n-1)/2, 注意n代表最后元素的下标,在这个范围内的节点都是非叶子节点((n-1)/2是第一个非叶子节点的下标)
-
如果arr[i] <= arr[2*i + 1] && arr[i] <= arr[2*i+2], 就是小根堆
-
如果arr[i] >= arr[2*i + 1] && arr[i] >= arr[2*i+2], 就是大根堆
-
-
(孩子节点下标-1)/2 即得到孩子父节点的下标
-
大根堆的堆顶元素是所有元素中最大的,小根堆的堆顶元素是最小的
入堆和出堆
大根堆入堆示例:
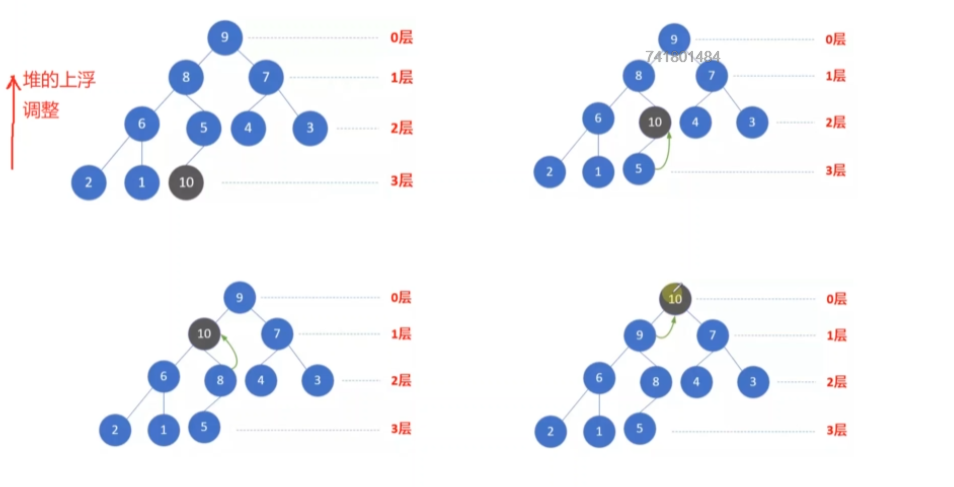
入堆实际上是在数组的末尾添加元素,然后开始堆的调整(上浮)
上浮操作:主要是通过(i-1)/2得到插入的节点的父节点的下标,然后和父节点元素比较大小,如果插入节点>父节点,那么父节点的值直接拿来覆盖孩子节点的值,然后i更新到父节点的下标,如此循环
大根堆出堆示例:

出堆只能出堆顶元素,出堆顶元素后把最后一个元素直接放到堆顶,然后开始堆的下沉调整
下沉操作:计算孩子节点(2i+1, 2i+2),然后和孩子节点进行比较,把最大的元素提上来,i更新成对应孩子节点的下标,然后继续和孩子节点进行比较,直到i更新到超过范围(0 <= i <= (n-1)/2, 注意n代表最后元素的下标, 这个范围内的节点有孩子)
基于大根堆的优先级队列实现
#include <iostream>
#include <functional>
#include <stdlib.h>
#include <time.h>
using namespace std;
class PriorityQueue
{
public:
using Comp = function<bool(int, int)>;
PriorityQueue(int cap = 20, Comp comp = greater<int>())
:size_(0)
,cap_(cap)
,comp_(comp)
{
que_ = new int[cap_];
}
//方便仅使用比较器来构造优先级队列
PriorityQueue(Comp comp)
:size_(0)
,cap_(20)
,comp_(comp)
{
que_ = new int[cap_];
}
~PriorityQueue()
{
delete[]que_;
que_ = nullptr;
}
// 入堆操作
void push(int val)
{
// 数组的2倍扩容
if (size_ == cap_)
{
expand(2 * cap_);
}
if (size_ == 0)
{
//若当前堆中没有元素,只要放入元素就行,没有上浮操作
que_[size_] = val;
}
else
{
//堆中有元素,把数据插入数组末尾,并执行上浮调整
que_[size_] = val;
SiftUp(size_, val); //size_也是末尾元素的下标,val就是要上浮的元素
}
size_++;
}
// 出堆操作
void pop()
{
if (empty())
throw "container is empty!";
size_--;
SiftDown(0, que_[size_]); // que_[size_]表示末尾元素
}
// 获取堆顶元素(下标为0)
int top()const
{
return que_[0];
}
// 判空
bool empty()const
{
return size_==0;
}
private:
void expand(int size)
{
int* p = new int[size];
// 因为该优先级队列存储的是int类型的数据,没有占用外部内存, 所以我们仅使用内存拷贝(浅拷贝)就可以
memcpy(p, que_, sizeof(int) * cap_);
delete[]que_;
que_ = p;
cap_ = size;
}
void SiftUp(int i, int val)
{//上浮操作,或者说是i从末尾位置不断向根节点下标(0)接近
while (i > 0)//根节点没有父节点
{
int father = (i - 1) / 2;
if (comp_(val, que_[father])) // 当前节点大于父节点
{
// 把父节点移下来
que_[i] = que_[father];
// i更新成父节点下标
i = father;
}
else
{
// 当前节点小于父节点,满足大小关系不需要再进行调整
break;
}
}
// 把val放入最终的位置
que_[i] = val;
}
void SiftDown(int i, int val)
{
//当i满足0<=i<=(size_-1-1)/2,i是有孩子节点的,size-1表示最后一个元素的下标
while (i < size_ / 2)
{
// child默认记录左孩子的坐标(因为i肯定有左孩子,但未必有右孩子)
int child = 2 * i + 1;
if (child + 1 < size_ && comp_(que_[child + 1], que_[child]))
{// 右孩子存在,且右孩子比左孩子大
// child就记录右孩子坐标
child = child + 1;
}
// 把i节点的值和最大孩子节点进行比较
if (comp_(que_[child], val))
{
// 把孩子节点元素往上提
que_[i] = que_[child];
// 向下更新i节点
i = child;
}
else
{
// 当前节点和孩子节点的大小满足大根堆关系,不再进行调整
break;
}
}
// 把val值放入调整后的位置
que_[i] = val;
}
int* que_; // 指向底层数组
int size_; // 数组中的元素个数
int cap_; // 底层容量大小
Comp comp_; // 比较器对象
};
int main()
{
//默认是构造基于大根堆的优先级队列
//PriorityQueue que;
PriorityQueue que([](int a, int b) {return a < b; });//基于基于小根堆的优先级队列
srand(time(NULL));
for (int i = 0; i < 10; ++i)
{
// 先添加到末尾,再执行上浮操作
que.push(rand() % 100 + 1);
}
while (!que.empty())
{//有序输出
cout << que.top() << " ";
que.pop();
}
cout << endl;
return 0;
}
堆排序算法
基本步骤:
-
从第一个非叶子节点开始【(n-1)/2,n是末尾元素下标】, 把二叉树调整成一个大根堆(从(n-1)/2开始一直调整到根)
-
把堆顶元素和末尾元素进行交换,然后不包含末尾元素继续执行第1、2步骤
void SiftDown(int arr[], int i, int size) // O(logn)
{
int val = arr[i];
//(从下往上)第一个非叶子节点(size-1-1)/2
while (i < size / 2)
{
int child = 2 * i + 1;
// 选出孩子节点
if (child + 1 < size && arr[child + 1] > arr[child])
{
child = child + 1;
}
//比较孩子节点和父节点大小
if (arr[child] > val)
{//把孩子节点换上来
arr[i] = arr[child];
i = child;//i下沉
}
else
{
break;
}
}
arr[i] = val;
return;
}
// 堆排序(从小到大)
void HeapSort(int arr[], int size)
{
//第一步:从第一个(从下往上)非叶子节点开始到堆顶元素执行下沉操作,将二叉堆调整成大根堆
int n = size - 1;//末尾元素的下标
for (int i = (n - 1) / 2; i >= 0; i--) // O(n) * O(logn) = O(nlogn)
{
// 对下标为i的节点进行下沉调整,size为数组的长度
SiftDown(arr, i, size);
}
//第二步:基于大根堆,将最后一个元素和堆顶元素进行交换,然后堆顶元素执行下沉
//注意每执行完一趟后,最后的元素都不用进行下一次的下沉调整
//目的就是为了每一趟都将一个堆顶元素往下放
for (int i = n; i > 0; i--)
{
//交换堆顶元素
int tmp = arr[0];
arr[0] = arr[i];
arr[i] = tmp;
//堆顶元素换下来后不要再考虑arr[i],所以传的是i
SiftDown(arr, 0, i);
}
return;
}
性能分析:
- 不稳定排序
- 最好/最坏/平均时间复杂度O(nlogn), 空间复杂度为O(1)
基数排序(桶排序)
基本思想:
-
找出位数最长的数字,确实桶排序要处理的趟数
-
由个位开始处理,把相应位上的数字放入相应序号的桶里(0-9号桶),完成后再按照桶的序号,依次从桶中取出数据,拷贝回原始的数组当中,然后接着从十位开始执行相同操作,直到执行完所有的趟数(比如:对应位上的数字如果为3,就放入3号桶)
-
当处理完所有的位数后,最终得到有序的序列
(小到大排序:从0号桶开始拷贝数据;)(大到小排序:从9号桶开始拷贝数据;)
基数排序的关键就是取每一位的数字:

即循环每次取出一个位上的数字
桶的实现
桶的实现就是一个二维数组,但是不是等列的,因为每个序号上放的数字是不同的,所以我们采用vector<vector<int>>
缺陷
- 对于存在浮点数的序列,无法处理
性能分析

#include <iostream>
#include <stdlib.h>
#include <string>
#include <vector>
using namespace std;
// 基数排序(整数的排序)
// 时间复杂度O(nd) 空间复杂度O(n)-->桶占用的内存资源
void RadixSort(int arr[], int size)
{
//1.先找到位数最长的元素,确定要循环的趟数(因为序列中可能有负数,所以要加上绝对值)
int maxData = abs(arr[0]);
for (int i = 1; i < size; i++)
{
if (maxData < abs(arr[i]))
{
maxData = abs(arr[i]);
}
}
int len = to_string(maxData).size();//获取字符串位数
int mod = 10;
int dev = 1;
vector<vector<int>> vecs;
// O(d), d表示最长位数
for (int i = 0; i < len; mod *= 10, dev *= 10, i++)/ / 趟数
{
vecs.resize(20);//20个桶,0到19,其中0-9存负数,10-19存正数
// 依次遍历数组元素,按照相应位数的值放入对应的桶中
for (int j = 0; j < size; j++)//O(n)
{
// 负数取mod会得到负数
int index = arr[j] % mod / dev + 10; //+10是为了让负数存到0-9桶,正数存到10-19桶
vecs[index].push_back(arr[j]);
}
//按序将桶中元素放入arr中
int idx = 0;
//0(20)*O(n)==>O(n)
for (auto vec : vecs) //O(20)
{
for (auto v : vec) //0(n)
{
arr[idx++] = v;
}
}
vecs.clear();//注意每次都要清空桶
}
}
总结
算法性能测试

使用不同的数据规模进行测试后的结果如上图所示
在数据量比较大的情况下堆排序的执行时间最长,性能最低,分析原因:
- 不管是快排还是归并排序等,遍历元素的时候都是按照顺序进行遍历的,对CPU缓存是友好的,即cpu缓存命中率高(局部性原理),但是堆排序需要进行上浮或下沉操作,访问的是父子节点,而它们并不挨着,这对于CPU缓存并不友好
- 堆排序的过程中,进行元素下沉调整所作的无效比较过多。(每次下沉完,调整成大根堆后,都会把堆顶元素和末尾元素交换,那末尾元素一般都是比较小的,这也意味着下一次进行调整的时候,堆顶元素又会被调整到靠近末尾的地方)
排序算法常见问题
STL里sort算法用的是什么排序算法?
使用的是快速排序,但是随着快排算法的执行,数据逐渐有序,待排序序列个数<=32(默认),则转为插入排序,此外,如果使用快排,递归层数太深,将转为堆排序
排序的时间复杂度不是稳定的nlogn,最坏情况会变成n^2,怎么解决恶化问题?
- 见上一问
- 随取合理的基准数,比如三数取中法
排序算法递归实现时,怎么解决递归层次过深的问题?
递归层数过多导致:
- 函数调用开销大,
- 占用栈内存太多,导致栈内存溢出,程序挂掉
怎么解决呢?
- 参考sort算法,当递归层数过深时,转为不进行递归的堆排序算法

内排序:数据都在内存上
外排序:内存小,而数据量大,无法一次性将数据加载到内存上

















 2838
2838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











