







文章目录
c语言编译过程

1、编译预处理
读取c源程序,对其中的伪指令(以#开头的指令)和特殊符号进行处理。
预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。下一步,此输出文件将作为编译程序的输出而被翻译成为机器指令。
2、编译阶段
经过预编译得到的输出文件中,将只有常量。如数字、字符串、变量的定义,以及C语言的关键字,如main,if,else,for,while,{,},+,-,*,\等等。预编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
3、优化阶段
优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
4、汇编过程
把汇编语言代码翻译成目标机器指令的过程。
5、链接程序
主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
GCC
我们使用最经典的helloworld程序:

gcc 与 g++ 分别是 gnu 的 c & c++ 编译器 gcc/g++ 在执行编译工作的时候,总共需要4步:
-
预处理生成 .i 文件[预处理器cpp]
执行gcc指令:gcc -E 1.c -o 1.i生成.i 文件:

可以看到它把头文件替换掉了。 -
将预处理后的文件转换成汇编语言, 生成 .s 文件[编译器egcs]
执行gcc指令:gcc -S 1.i -o 1.s生成.s 文件:

现在已经是汇编代码了。 -
有汇编变为目标代码(机器代码)生成 .o 文件[汇编器as]
执行gcc指令:gcc -c 1.s -o 1.o生成.o 文件:

现在已经是二进制文件了。 -
连接目标代码, 生成可执行程序 [链接器ld]
执行gcc指令:gcc 1.o -o 1.out生成.out 文件:

gcc 命令的常用选项
(来自菜鸟教程)
| 选项 | 解释 |
|---|---|
| -ansi | 关闭 gnu c中与 ansi c 不兼容的特性, 激活 ansi c 的专有特性(包括禁止一些 asm inline typeof 关键字, 以及 UNIX,vax 等预处理宏)。 |
| -o FILE | 生成指定的输出文件。用在生成可执行文件时。 |
| -c | 只激活预处理,编译,和汇编,也就是他只把程序做成obj文件 |
| -E | 只运行 C 预编译器。 |
| -S | 只激活预处理和编译,就是指把文件编译成为汇编代码。 |
| -IDIRECTORY | 指定额外的头文件搜索路径DIRECTORY。 |
| -LDIRECTORY | 连接时搜索指定的函数库LIBRARY。 |
| -shared | 生成共享目标文件。通常用在建立共享库时。 |
| -static | 禁止使用共享连接。 |
| -g | 生成调试信息。GNU 调试器(如gdb)可利用该信息。 |
| -M | 生成文件关联的信息。 |
| -MM | 生成文件关联的信息,但是它将忽略由 #include<file> 造成的依赖关系。 |
| -MD | 和-M相同,但是输出将导入到.d的文件里面。 |
| -MMD | 和 -MM 相同,但是输出将导入到 .d 的文件里面。 |
| -w | 不生成任何警告信息。 |
| -Wall | 生成所有警告信息。 |
| -m486 | 针对 486 进行代码优化。 |
| -O0 | 不进行优化处理。 |
| -O 或 -O1 | 优化生成代码。 |
| -O2 | 进一步优化。 |
| -O3 | 比 -O2 更进一步优化,包括 inline 函数。 |
| -DMACRO | 以字符串"1"定义 MACRO 宏。 |
| -DMACRO=DEFN | 以字符串"DEFN"定义 MACRO 宏。 |
| -UMACRO | 取消对 MACRO 宏的定义。 |
| -x language filename | 设定文件所使用的语言, 使后缀名无效, 对以后的多个有效。 |
| -x none filename | 关掉上一个选项,也就是让gcc根据文件名后缀,自动识别文件类型 。 |
| -pipe | 使用管道代替编译中临时文件, 在使用非 gnu 汇编工具的时候, 可能有些问题。 |
静态链接库
由链接器在链接时将库的内容加入到可执行程序中。
- 优点:对运行环境的依赖性较小,具有较好的兼容性
- 缺点:生成的程序比较大,需要更多的系统资源,在装入内存时会消耗更多的时间库函数有了更新,必须重新编译应用程序
采用动态链接,编译helloworld程序(gcc hello.c -static -o hello_static),726kb:

制作静态链接库
静态链链接库在linux中后缀为.a,以lib 开头,如libtestlib.a
程序:
mytest.c
#include <stdio.h>
#include "mylib.h"
int main(void)
{
int a = 10, b = 20;
printf("max = %d\n", max(a, b));
printf("min = %d\n", min(a, b));
return 0;
}
mylib.h
extern int max(int x, int y);
extern int min(int x, int y);
mylib.c
int max(int x, int y)
{
return x > y ? x : y;
}
int min(int x, int y)
{
return x < y ? x : y;
}
制作:
gcc -c mylib.c -o mylib.o # 编译目标文件
ar rc libtestlib.a mylib.o # 制作静态库
使用:
# 编译程序时,编译器默认会
# 到/lib/、/usr/lib下查找库函数
# 到/usr/include下查找头文件
gcc -o mytest mytest.c libtestlib.a # 库文件、头文件均在当前目录下
gcc -o mytest mytest.c -Llib -ltestlib -Iinclude # 库文件在lib目录下、头文件在include目录下
动态链接库
连接器在链接时仅仅建立与所需库函数的之间的链接关系,在程序运行时才将所需资源调入可执行程序。
- 优点:在需要的时候才会调入对应的资源函数简化程序的升级;有着较小的程序体积实现进程之间的资源共享(避免重复拷贝)
- 缺点:依赖动态库,不能独立运行动态库依赖版本问题严重
系统默认采用动态链接,编译helloworld程序(gcc hello.c -o hello_share),8.3kb:

制作动态链接库
静态链链接库在linux中后缀为.so,以lib 开头,如libtestlib.so
制作:
gcc -shared mylib.c -o libtestlib.so # 使用gcc编译、制作动态链接库
使用:
gcc -o mytest mytest.c libtestlib.so # 库函数、头文件均在当前目录下
gcc -o mytest mytest.c -Llib -ltestlib -Iinclude # 库文件在lib目录下、头文件在include目录下
注:当静态库与动态库重名时,系统会优先连接动态库,或者我们可以加入-static指定使用静态库。
make
参考跟我一起写 Makefile(基本上照搬)
make 是一个命令工具,是一个解释 makefile 中指令的命令工具。
makefile
makefile 关系到了整个工程的编译规则。
makefile 一旦写好,只需要一个 make 命令,整个工程完全自动编译,极大的提高了软件开发的效率。
Makefile 告诉 make 命令如何编译和链接这几个文件。规则是:
- 如果这个工程没有编译过,那么我们的所有 C 文件都要编译并被链接。
- 如果这个工程的某几个 C 文件被修改,那么我们只编译被修改的 C 文件,并链接目标程序。
- 如果这个工程的头文件被改变了,那么我们需要编译引用了这几个头文件的 C 文件, 并链接目标程序。
makefile规则
target : prerequisites...
<Tab>command
<Tab>...
<Tab>...
- target:一个目标文件,可以是 Object File,也可以是执行文件,还可以是一个Label(可以是不用的编译或是和编译无关的命令)。
- prerequisites:生成 target 所依赖的文件或是目标。
- command:make 需要执行的命令。(任意的 Shell 命令)
这是一个文件的依赖关系,target 这一个或多个的目标文件依赖于 prerequisites 中的文件,其生成规则定义在 command 中。说白一点就是说,prerequisites 中如果有一个以上的文件比 target 文件要新的话,command 所定义的命令就会被执行。这就是 Makefile 的规则。也就是 Makefile 中核心的内容。
例子
首先我们有几个文件:
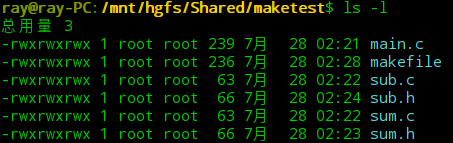
内容分别是:
main.c
#include <stdio.h>
#include "sum.h"
#include "sub.h"
int main(int argc, const char *argv[])
{
int x = 1000;
int y = 900;
printf("%d + %d = %d\n", x, y, sum(x, y));
printf("%d - %d = %d\n", x, y, sub(x, y));
return 0;
}
sub.c
#include "sub.h"
int sub(int a, int b)
{
return a - b;
}
sum.c
#include "sum.h"
int sum(int a, int b)
{
return a + b;
}
sub.h
#ifndef _SUB_H
#define _SUB_H
int sub(int a, int b);
#endif
sum.h
#ifndef _SUM_H
#define _SUM_H
int sum(int a, int b);
#endif
第一版makefile
main:main.o sub.o sum.o
gcc main.o sub.o sum.o -o main
main.o:main.c sub.h sum.h
gcc -c main.c -o main.o
sub.o:sub.c sub.h
gcc -c sub.c -o sub.o
sum.o:sum.c sum.h
gcc -c sum.c -o sum.o
clean:
rm -rf *.o main a.out
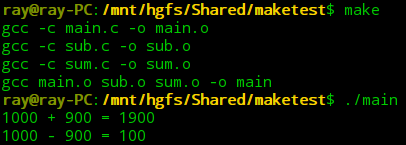
编译和执行:
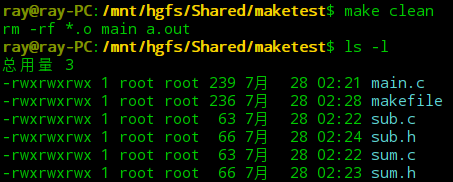
清理生成文件:
第二版makefile
我们可以使用makefile变量来代替一些值,使得我们以后修改起来更加轻松(比如说我们编译器不想用gcc,只需要改一处即可)。
CC=gcc
obj=main
obj1=sub
obj2=sum
OBJ=main.o sub.o sum.o
$(obj):$(OBJ)
$(CC) $(OBJ) -o $(obj)
$(obj).o:$(obj).c sub.h sum.h
$(CC) -c $(obj).c -o $(obj).o
$(obj1).o:$(obj1).c sub.h
$(CC) -c $(obj1).c -o $(obj1).o
$(obj2).o:$(obj2).c sum.h
$(CC) -c $(obj2).c -o $(obj2).o
clean:
rm -rf *.o $(obj) a.out
第三版makefile
我们可以发现我们写了很多重复的代码。可以使用预定义变量和通配符改进。
CC=gcc
obj=main
OBJ=main.o sub.o sum.o
CFLAGS=-Wall -g
$(obj):$(OBJ)
$(CC) $^ -o $@
%*.o:%*.c
$(CC) $(CFLAGS) -c $< -o $@
clean:
rm -rf *.o $(obj) a.out
makefile综述
主要内容:
- 显式规则。显式规则说明了,如何生成一个或多的的目标文件。这是由 Makefile 的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
- 隐晦规则。由于我们的 make 有自动推导的功能,所以隐晦的规则可以让我们比较粗糙 地简略地书写 Makefile,这是由 make 所支持的。
- 变量的定义。在 Makefile 中我们要定义一系列的变量,变量一般都是字符串,这个有点你 C 语言中的宏,当 Makefile 被执行时,其中的变量都会被扩展到相应的引用位置上。
- 文件指示。其包括了三个部分,一个是在一个 Makefile 中引用另一个 Makefile,就像 C 语言中的
#include一样;另一个是指根据某些情况指定 Makefile 中的有效部分,就像 C 语言 中的预编译#if一样;还有就是定义一个多行的命令。 - 注释。Makefile 中只有行注释,和 UNIX 的 Shell 脚本一样,其注释是用“#”字符,这个就像 C/C++中的“//”一样。如果你要在你的 Makefile 中使用“#”字符,可以用反斜框进行转义,如:
\#
文件名
默认的情况下,make 命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、 “Makefile”的文件,找到了解释这个文件。
你可以使用别的文件名来书写 Makefile,比如: “Make.Linux”,“Make.Solaris”, “Make.AIX”等,如果要指定特定的 Makefile,你可以使用 make 的“-f”和“–file”参数, 如:make -f Make.Linux 或 make --file Make.AIX。
引用其它的 Makefile
include 的语法是:include <filename>
filename 可以是当前操作系统 Shell 的文件模式(可以保含路径和通配符) 。
make 命令开始时,会把找寻 include 所指出的其它 Makefile,并把其内容安置在当前的位置。 就好像 C/C++的#include 指令一样。如果文件都没有指定绝对路径或是相对路径的话,make 会在当前目录下首先寻找,如果当前目录下没有找到,那么,make 还会在下面的几个目录 下找:
- 如果 make 执行时,有“-I”或“–include-dir”参数,那么 make 就会在这个参数所 指定的目录下去寻找。
- 如果目录
<prefix>/include(一般是:/usr/local/bin或/usr/include)存在的话,make 也会去找。
如果你想让 make 不理那些无法读取的文件,而继续执行,你可以在 include 前加一个减号“-”。 和其它版本 make兼容的相关命令是 sinclude,其作用和“-”是一样的。
环境变量
如果你的当前环境中定义了环境变量 MAKEFILES,那么 make 会把这个变量中的值做一 个类似于 include 的动作。建议不要使用这个环境变量,因为只要这个变量一被定义,那么当你使用 make 时,所有的 Makefile 都会受到它的影响。
工作方式
GNU 的 make 工作时的执行步骤入下:
- 读入所有的 Makefile。
- 读入被 include 的其它 Makefile。
- 初始化文件中的变量。
- 推导隐晦规则,并分析所有规则。
- 为所有的目标文件创建依赖关系链。
- 根据依赖关系,决定哪些目标要重新生成。
- 执行生成命令。
书写规则
在 Makefile 中,规则的顺序是很重要的,因为,Makefile 中只应该有一个终目标,其它的目标都是被这个目标所连带出来的,所以一定要让 make 知道你的终目标是什么。一般来说,定义在 Makefile 中的目标可能会有很多,但是第一条规则中的目标将被确立为终的目标。如果第一条规则中的目标有很多个,那么,第一个目标会成为终的目标。make 所完成的也就是这个目标。
多目标
Makefile 的规则中的目标可以不止一个,其支持多目标,有可能我们的多个目标同时依赖于一个文件,并且其生成的命令大体类似。于是我们就能把其合并起来。多个目标的生成规则的执行命令是同一个,可能会可我们带来麻烦,但是我们可以使用自动化变量。
如:
bigoutput littleoutput : text.g
generate text.g -$(subst output,,$@) > $@
相当于:
bigoutput : text.g
generate text.g -big > bigoutput
littleoutput : text.g
generate text.g -little > littleoutput
静态模式
静态模式可以更加容易地定义多目标的规则,可以让我们的规则变得更加的有弹性和灵活。 我们还是先来看一下语法:
targets : target-pattern : prereq-patterns
<Tab>command
<Tab>...
<Tab>...
- targets 定义了一系列的目标文件,可以有通配符。是目标的一个集合。
- target-parrtern 是指明了 targets 的模式,也就是的目标集模式。
- prereq-parrterns 是目标的依赖模式,它对 target-parrtern 形成的模式再进行一次依赖目标的定义。
还是举个例子来说明一下吧。如果我们的 target-parrtern定义成“%.o”,意思是我们的targets集合中都是以“.o”结尾的,而如果我们的prereq-parrterns定义成“%.c”,意思是对target-parrtern所形成的目标集进行二次定义,其计算方法是,取target-parrtern模式中的“%”(也就是去掉了[.o]这个结尾),并为其加上[.c]这个结尾,形成的新集合。
比如:
objects = foo.o bar.o
all: $(objects)
$(objects): %.o: %.c
$(CC) -c $(CFLAGS) $< -o $@
相当于:
foo.o : foo.c
$(CC) -c $(CFLAGS) foo.c -o foo.o
bar.o : bar.c
$(CC) -c $(CFLAGS) bar.c -o bar.o
自动生成依赖性
我们gcc有个生成文件关联的信息的功能:

GNU 组织建议把编译器为每一个源文件的自动生成的依赖关系放到一个文件中,为每一个“name.c”的文件都生成一个“name.d” 的 Makefile 文件,[.d]文件中就存放对应[.c]文件的依赖关系。
于是,我们可以写出[.c]文件和[.d]文件的依赖关系,并让 make 自动更新或自成[.d]文件,并 把其包含在我们的主 Makefile 中,这样,我们就可以自动化地生成每个文件的依赖关系了。
这里,我们给出了一个模式规则来产生[.d]文件:
%.d: %.c
@set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
这个规则的意思是,所有的[.d]文件依赖于[.c]文件,
@set -e就是当命令以非零状态退出时,则退出shell。
rm -f $@的意思是删除所有的目标,也就是[.d]文件。
第二行的意思是,为每个依赖文件$<,也就是[.c]文件生成依赖文件,$@表示模式“%.d”文件,如果有一个 C 文件是 name.c,那么“%”就是“name”,$$$$ 意为一个随机编号,第二行生成的文件有可能是“name.d.12345”。
第三行使用 sed 命令做了 一个替换。
第四行就是删除临时文件。
于是,我们的[.d]文件也会自动更新了,并会自动生成了,当然,你还可以在这个[.d]文件中加入的不只是依赖关系,包括生成的命令也可一并加入,让每个[.d]文件都包含一个完赖的规则。
第四版makefile
CC=gcc
obj=main
CFLAGS=-Wall -g
#使用$(wildcard *.c)来获取工作目录下的所有.c文件的列表
sources:=$(wildcard *.c)
objects:=$(sources:.c=.o)
#这里,dependence是所有.d文件的列表.即把串sources串里的.c换成.d
dependence:=$(sources:.c=.d)
$(obj):$(objects)
$(CC) $(CFLAGS) $^ -o $@
%.d: %.c
@set -e; rm -f $@; \
$(CC) -MM $(CPPFLAGS) $< > $@.$$$$; \
sed 's,\($*\)\.o[ :]*,\1.o $@ : ,g' < $@.$$$$ > $@; \
rm -f $@.$$$$
#注意该句要放在终极目标规则之后,否则.d文件里的规则会被误当作终极规则了
-include $(dependence)
clean:
rm -rf *.o *.d $(obj) a.out

嵌套使用make
在一些大的工程中,我们会把我们不同模块或是不同功能的源文件放在不同的目录中,我们 可以在每个目录中都书写一个该目录的 Makefile,这有利于让我们的 Makefile 变得更加地简洁,而不至于把所有的东西全部写在一个 Makefile 中,这样会很难维护我们的 Makefile,这 个技术对于我们模块编译和分段编译有着非常大的好处。
例如,我们有一个子目录叫 subdir,这个目录下有个 Makefile 文件,来指明了这个目录下文件的编译规则。那么我们总控的 Makefile 可以这样书写:
subsystem:
cd subdir && $(MAKE)
相当于:
subsystem:
$(MAKE) -C subdir
我们把这个 Makefile 叫做“总控 Makefile”,总控 Makefile 的变量可以传递到下级的 Makefile 中(如果你显示的声明),但是不会覆盖下层的 Makefile 中所定义的变量,除非指定了“-e” 参数。
如果你要传递变量到下级 Makefile 中,那么你可以使用这样的声明:export <variable ...> 。
如果你不想让某些变量传递到下级 Makefile 中,那么你可以这样声明:unexport <variable ...> 。
makefile变量
makefile变量类似于c语言中的宏,当makefile被make工具解析时,其中的变量会被展开。
作用:
- 保存文件名列表
- 保存文件目录列表
- 保存编译器名
- 保存编译参数
- 保存编译的输出
- …
分类:
- 自定义变量:在makefile文件中定义的变量。make工具传给makefile的变量。
- 系统环境变量:make工具解析makefile前,读取系统环境变量并设置为makefile的变量。
- 预定义变量(自动变量)
常用预定义变量 含义 $@ 表示规则中的目标文件集 $% 仅当目标是函数库文件中,表示规则中的目标成员名。 $< 依赖文件列表中的第一个文件 $^ 依赖文件列表中除去重复文件的部分 $? 所有比目标新的依赖目标的集合。以空格分隔。 AR 归档维护程序的程序名,默认值为ar ARFLAGS 归档维护程序的选项 AS 汇编程序的名称,默认值为as ASFLAGS 汇编程序的选项 CC c编译器的名称,默认值为cc CFLAGS c编译器的选项 CPP c预编译器的名称,默认值为$(CC) -E CPPFLAGS c预编译器的选项 CXX C++编译器的名称,默认值为g++ CXXFLAGS C++编译器的选项
定义变量:
变量名=变量值(变量是可以使用后面的变量来定义的)
变量名:=变量值(前面的变量不能使用后面的变量,只能使用前面已定义好了的变量。)
变量名?=变量值(如果变量名没有被定义过,那么变量变量名的值就是变量值,如果 变量名先前被定义过,那么这条语将什么也不做。)
引用变量:$(变量名)或${变量名}(把变量的值再当成变量)
替换变量中的共有的部分:$(var:a=b)或${var:a=b},把变量“var”中所有以“a”字串“结尾”的“a”替换成“b”字串。
追加变量值 :变量名+=变量值
如果有变量是通常make的命令行参数设置的,那么Makefile中对这个变量的赋值会被忽略。如果你想在 Makefile 中设置这类参数的值,那么,你可以使用“override”指示符。其语法是:override 变量名=变量值
定义命令包
如果 Makefile 中出现一些相同命令序列,那么我们可以为这些相同的命令序列定义一个变 量。定义这种命令序列的语法以“define”开始,以“endef”结束。要使用这个命令包,我们就好像使用变量一样。
条件表达式
语法为:
conditional-directive
<text-if-true>
endif
conditional-directive
<text-if-true>
else
<text-if-false>
endif
其中conditional-directive表示条件关键字:
| 关键字 | 用法 | 作用 |
|---|---|---|
| ifeq | ifeq (arg1, arg2) | 比较参数“arg1”和“arg2”的值是否相同。 |
| ifneq | ifneq (arg1, arg2) | 其比较参数“arg1”和“arg2”的值是否相同,如果不同,则为真。 |
| ifdef | ifdef var | 如果变量var的值非空,那到表达式为真。否则,表达式为假。 |
| ifndef | ifndef var | 如果变量var的值空,那到表达式为真。否则,表达式为假。 |
函数
函数调用:$(function arguments) 或${function arguments}
function就是函数名,make 支持的函数不多。arguments是函数的参数,参数间以逗号“,”分隔,而函数名和参数之间以“空格”分隔。
字符串处理函数
| 函数 | 名称 | 功能 | 返回 |
|---|---|---|---|
| $(subst from,to,text) | 字符串替换函数 | 把字串text中的from字符串替换成to | 返回被替换过后的字符串 |
| $(patsubst pattern,replacement,text) | 模式字符串替换函数 | 查找text中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式pattern,如果匹配的话,则以replacement替换。 | 返回被替换过后的字符串 |
| $(strip string) | 去空格函数 | 去掉string字串中开头和结尾的空字符 | 返回被去掉空格的字符串值 |
| $(findstring find,in) | 查找字符串函数 | 在字串in中查找find字串 | 如果找到,那么返回find,否则返回空字符串。 |
| $(filter pattern…,text) | 过滤函数 | 以pattern模式过滤text字符串中的单词,保留符合模式pattern的单词。可以有多个模式。 | 返回符合模式pattern的字串 |
| $(filter-out pattern…,text) | 反过滤函数 | 以pattern模式过滤text字符串中的单词,保留符合模式pattern的单词。可以有多个模式。 | 返回不符合模式pattern的字串 |
| $(sort list) | 排序函数 | 给字符串list中的单词排序(升序) | 返回排序后的字符串 |
| $(word n,text) | 取单词函数 | 取字符串text中第n个单词。(从一开始) | 返回字符串text中第n个单词。如果n比text中的单词数要大,那么返回空字符串。 |
| $(wordlist s,e,text) | 取单词串函数 | 从字符串text中取从s开始到e的单词串。s和e是一个数字。 | 返回字符串text中从s到e的单词字串。如果s比text中的单词数要大, 那么返回空字符串。如果e大于text的单词数,那么返回从s开始,到text结束的单词串。 |
| $(words text) | 单词个数统计函数 | 统计text中字符串中的单词个数 | 返回text中的单词数 |
| $(firstword text) | 首单词函数 | 取字符串text中的第一个单词 | 返回字符串text的第一个单词。 |
文件名操作函数
| 函数 | 名称 | 功能 | 返回 |
|---|---|---|---|
| $(dir names…) | 取目录函数 | 从文件名序列names中取出目录部分。目录部分是指后一个反斜杠(“/”)之 前的部分。如果没有反斜杠,那么返回“./”。 | 返回文件名序列names的目录部分 |
| $(notdir names…) | 取文件函数 | 从文件名序列names中取出非目录部分。非目录部分是指后一个反斜杠(“/”) 之后的部分 | 返回文件名序列names的非目录部分 |
| $(suffix names…) | 取后缀函数 | 从文件名序列names中取出各个文件名的后缀 | 返回文件名序列names的后缀序列,如果文件没有后缀,则返回空字串。 |
| $(basename names…) | 取前缀函数 | 从文件名序列names中取出各个文件名的前缀部分 | 返回文件名序列names的前缀序列,如果文件没有前缀,则返回空字串。 |
| $(addsuffix suffix,names…) | 加后缀函数 | 把后缀suffix加到names中的每个单词后面。 | 返回加过后缀的文件名序列 |
| $(addprefix prefix,names…) | 加前缀函数 | 把前缀prefix加到names中的每个单词后面 | 返回加过前缀的文件名序列 |
| $(join list1,list2) | 连接函数 | 把list2中的单词对应地加到list1的单词后面。如果list1的单词个数要比list2的多,那么,list1中的多出来的单词将保持原样。如果list2的单词个数要比list1多,那么,list2多出来的单词将被复制到list2中。 | 返回连接过后的字符串 |
foreach函数
$(foreach var,list,text) 把参数list中的单词逐一取出放到参数var所指定的变量中,然后再执行text所包含的表达式。每一次text会返回一个字符串,循环过程中,text的所返回的每个字符串会以空格分隔,后当整个循环结束时,text所返回的每个字符串所组成的整个字符串(以空格分隔)将会是 foreach 函数的返回值。 所以,var好是一个变量名,list可以是一个表达式,而text中一般会使用var这个参数来依次枚举list中的单词。
if函数
$(if condition,then-part) 或 $(if condition,then-part,else-part)
condition参数是 if 的表达式,如果其返回的为非空字符串,那么这个表达式就相当于 返回真,于是,then-part会被计算,否则else-part会被计算。
if 函数的返回值:如果condition为真(非空字符串),那个then-part会是整个函数 的返回值,如果condition为假(空字符串),那么else-part会是整个函数的返回值,此时 如果else-part没有被定义,那么,整个函数返回空字串。
call 函数
call 函数是唯一一个可以用来创建新的参数化的函数。你可以写一个非常复杂的表达式,这 个表达式中,你可以定义许多参数,然后你可以用 call 函数来向这个表达式传递参数。
$(call expression,parm1,parm2,parm3...) :expression参数中的变量,如$(1),$(2),$(3)等,会被参数parm1, parm2,parm3依次取代。而expression的返回值就是 call 函数的返回值。
origin 函数
origin函数不像其它的函数,他并不操作变量的值,他只是告诉你你的这个变量是哪里来的。
$(origin variable) variable是变量的名字,不应该是引用。
| 返回值 | 意义 |
|---|---|
| undefined | variable从来没有定义过 |
| default | variable是一个默认的定义,比如“CC”这个变量。 |
| environment | variable是一个环境变量,并且当 Makefile 被执行时,“-e”参数没有被打开。 |
| file | variable被定义在 Makefile 中 |
| command line | variable被命令行定义的 |
| override | variable被 override 指示符重新定义的 |
| automatic | variable是一个命令运行中的自动化变量。 |
shell 函数
$(shell shell命令 variable) 这个函数会新生成一个 Shell 程序来执行命令,要注意其运行性能。
控制 make 的函数
$(error text ...) 产生一个致命的错误。函数不会在一被使用就会产生 错误信息,所以如果你把其定义在某个变量中,并在后续的脚本中使用这个变量,那么也是 可以的。
$(warning text ...) 很像 error 函数,只是它并不会让 make 退出,只是输出一段警告信息,而 make 继续执行。
隐含规则
“隐含规则”也就是一种惯例,make 会按照这种“惯例”心照不喧地来运行,那怕我们的 Makefile 中没有书写这样的规则。例如,把[.c]文件编译成[.o]文件这一规则,你根本就不用写出来,make 会自动推导出这种规则,并生成我们需要的[.o]文件。
“隐含规则”会使用一些我们系统变量,我们可以改变这些系统变量的值来定制隐含规则的 运行时的参数。如系统变量“CFLAGS”可以控制编译时的编译器参数。
我们还可以通过“模式规则”的方式写下自己的隐含规则。用“后缀规则”来定义隐含规则会有许多的限制。使用“模式规则”会更回得智能和清楚,但“后缀规则”可以用来保证我们 Makefile 的兼容性。 如%.o:%.c表示任何一个.o文件都依赖于.c文件
makefile构建工具
我们从他提供的一个例子入手:

main.c:
#include <stdio.h>
int main()
{
printf("Hello XBuild!\n");
return 0;
}
Makefile:
sinclude ../../scripts/env.mk
NAME := hello
SRC += main.c
运行结果:
















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









