







 本文探讨了三种针对图嵌入的攻击方法:成员推理攻击、图重建攻击和属性推理攻击。通过黑盒和白盒场景进行实验,发现置信度攻击在识别成员身份上更准确。在白盒设置中,敌人可以通过中间层模型输出重建图。同时,攻击者使用编码器-解码器结构尝试从图嵌入中恢复敏感属性或整个图。实验在cora、citeseer、pubmed数据集上进行,使用图卷积网络作为模型架构。
本文探讨了三种针对图嵌入的攻击方法:成员推理攻击、图重建攻击和属性推理攻击。通过黑盒和白盒场景进行实验,发现置信度攻击在识别成员身份上更准确。在白盒设置中,敌人可以通过中间层模型输出重建图。同时,攻击者使用编码器-解码器结构尝试从图嵌入中恢复敏感属性或整个图。实验在cora、citeseer、pubmed数据集上进行,使用图卷积网络作为模型架构。
本文贡献
本文研究了三种攻击方式:(从黑盒和白盒角度进行分析)
- 成员推理攻击(深度学习)
- 图重建攻击(深度学习)
- 属性推理攻击(随机游走)
成员推理攻击
黑盒设置中有两种
- 影子模型攻击:利用数据分布的辅助知识
- 置信度攻击:不使用数据分布的辅助知识
作者通过在cora、citeseer、pubmed上进行实验验证了置信度攻击方法比影子模型方法的准确度高
在白盒设置下,通过图嵌入来区分一个给定节点是否是训练图的一部分
图重建攻击:
给敌手一个子图的图嵌入,训练一个编码器-解码器来从图嵌入中得到整个图
属性推理攻击:
通过图嵌入来推断图上的敏感属性
成员推理攻击示意图:
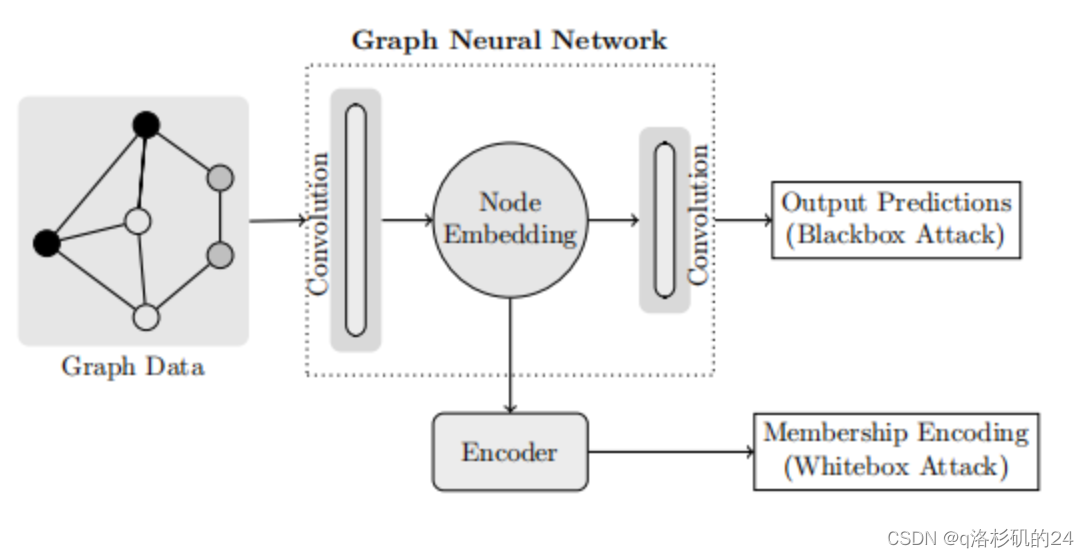
白盒攻击:
敌手可以访问中间层的模型输出,敌手以无监督的方式训练一个编码器-解码器,将中间嵌入映射到单一成员值,

给定不同训练和测试数据点的标量值,是用K-means聚类将节点聚为两类(成员和非成员)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









