







一.初识Python
1.Python的热度
Python是近几年非常火爆的一门编程语言,根据TIOBE编程语言排行榜可以看出,该语言热度一直居高不下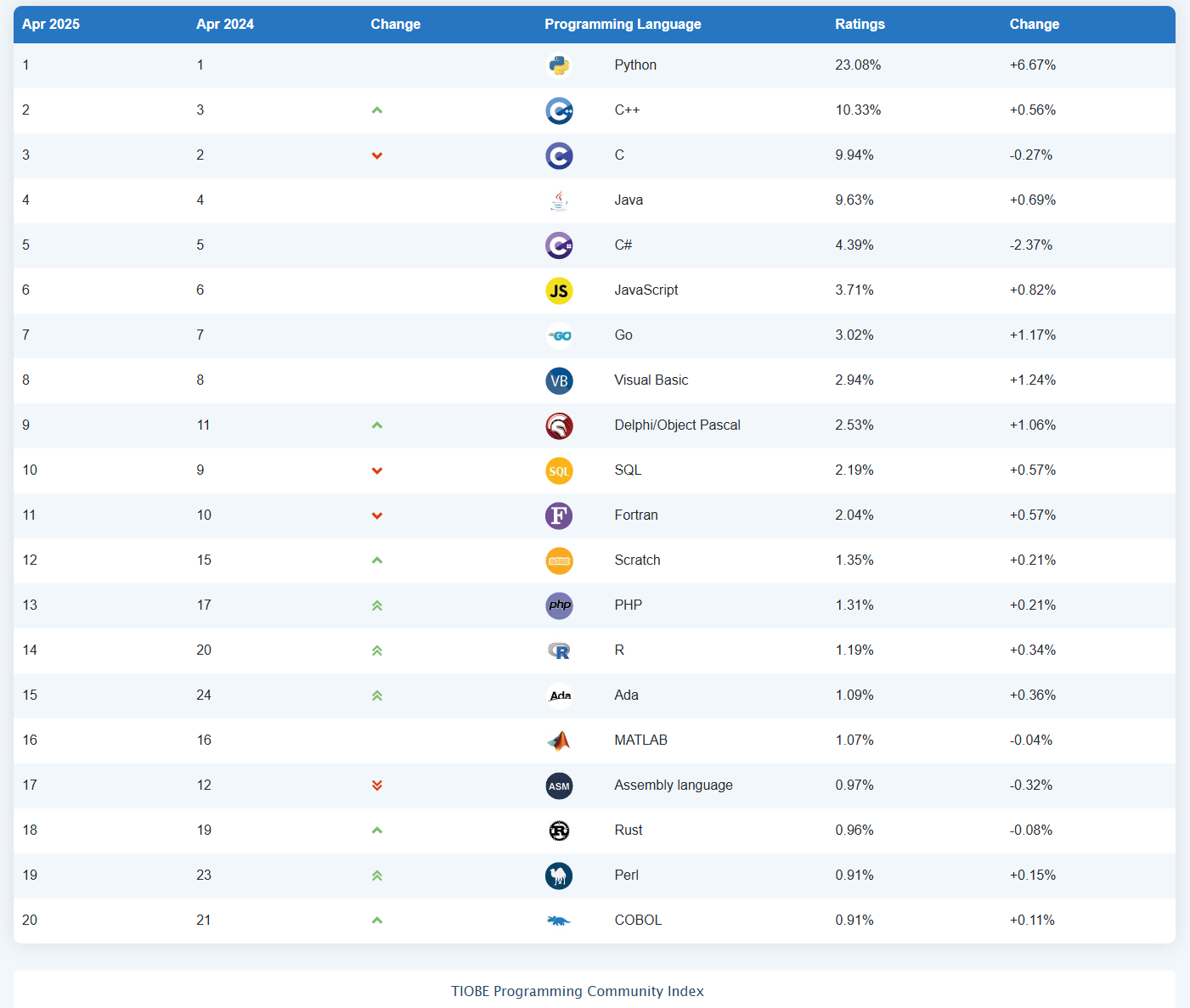
2.Python的优点
- 易于学习:python有相对较少的关键字,结构简单,和⼀个明确定义的语法,学习起来更加简单
- 易于阅读:python代码定义的更清晰
-
易于维护:python的成功在于它的源代码是相当容易维护
-
⼀个⼴泛的标准库:python的最⼤的优势之⼀是丰富的库,跨平台的,在UNIX,Windows和
Macintosh兼容很好.python拥有⼀个强⼤的标准库,Python语⾔的核⼼只包含数字、字符串、列表、字典、⽂件等常⻅类型和函数,⽽由Python标准库提供了系统管理、⽹络通信、⽂本处理、数据库接⼝、图形系统、XML处理等额外的功能 -
python社区提供了⼤量的第三⽅模块,使⽤⽅式与标准库类似。它们的功能覆盖科学计算、⼈⼯智能、机器学习、Web开发、数据库接⼝、图形系统多个领域
-
可移植:基于其开放源代码的特性,Python已经被移植(也就是使其⼯作)到许多平台
-
GUI编程:python⽀持GUI可以创建和移植到许多系统调⽤
-
可嵌⼊:你可以将python嵌⼊到C/C++程序,让你的程序的用户获得"脚本化"的能⼒
-
免费、开源,⾯向对象
二.软件安装
1.python解释器
Python的解释器是⼀种可以解释、执⾏Python代码的软件程序。Python官⽅提供了多个解释器,包括CPython、Jython、IronPython、PyPy等。其中,CPython是最常⽤的⼀个,也是官⽅默认的解释器。
2.集成开发环境(IDE)
集成开发环境( IDE ,Integrated Development Environment)⸺集成了开发软件需要的所有⼯具,⼀般包括以下⼯具:
• 图形用户界⾯
• 代码编辑器(⽀持代码补全/⾃动缩进)
• 编译器/解释器
• 调试器(断点/单步执⾏)
Pycharm
推荐初学者使⽤
官⽹:https://www.jetbrains.com/pycharm/
中⽂版:https://www.jetbrains.com.cn/pycharm/
3.Pycharm优点
PyCharm是Python的⼀款⾮常优秀的集成开发环境
- PyCharm 除了具有⼀般IDE所必备功能外,还可以在Windows 、 Linux 、 macOS 下使⽤
- PyCharm 适合开发⼤型项⽬
- ⼀个项⽬通常会包含很多源⽂件
- 每个源⽂件的代码⾏数是有限的,通常在⼏百⾏之内
- 每个源⽂件各司其职,共同完成复杂的业务功能
4.安装Python3
点击Downloads
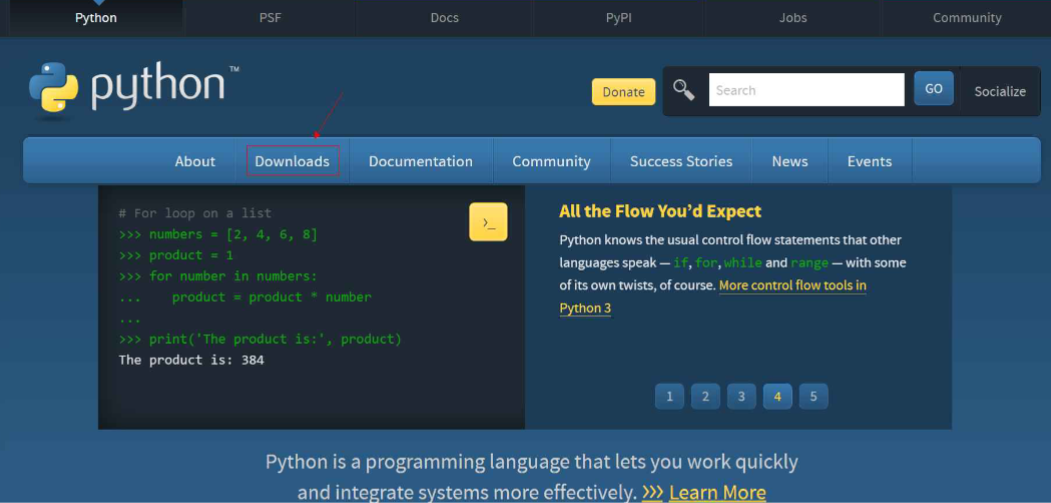
选择windows
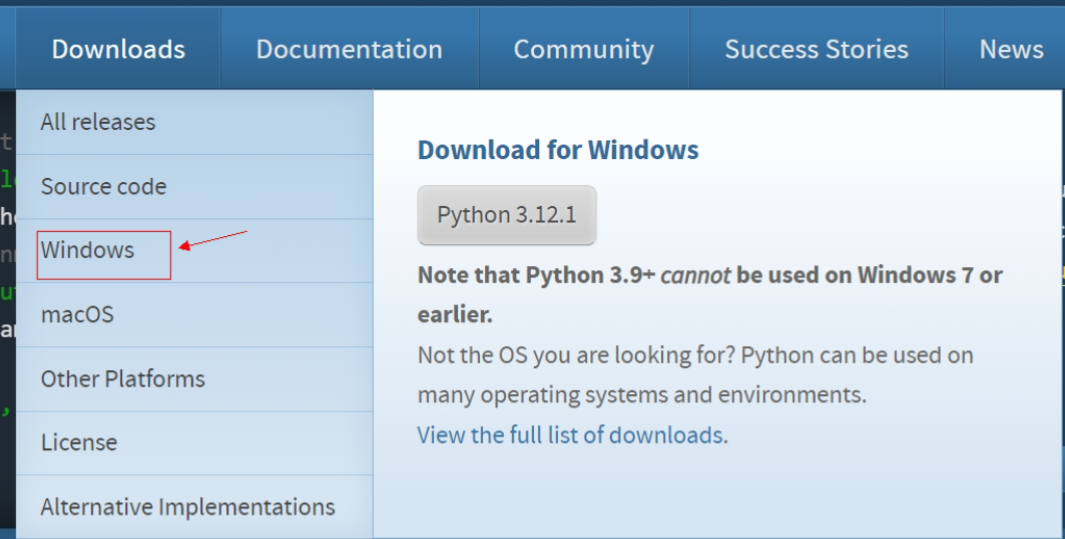
选择版本-点击下载
双击安装,进⾏安装
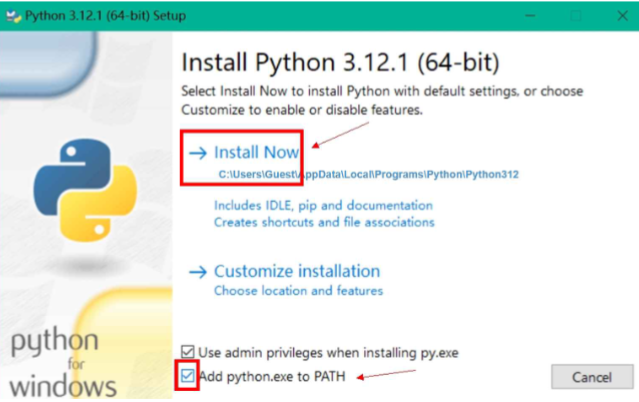
等待安装
安装成功,点击close
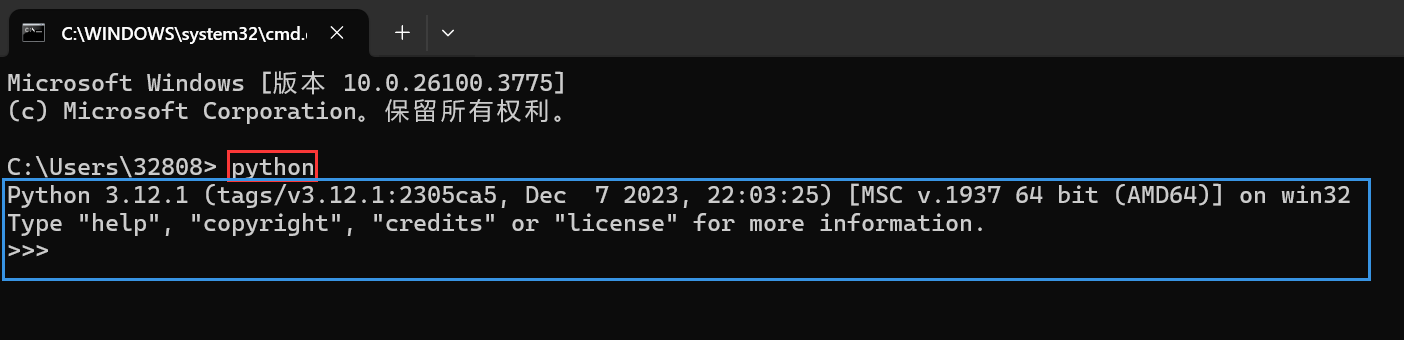
打开windwos终端验证(按住win+R键,输入cmd,在命令行中输入python)
出现下图中的三⾏⽂字,则表⽰安装成功。
5.安装Pycharm
去官⽹下载pycharm
https://www.jetbrains.com.cn/pycharm/
点击下载

点击“下⼀步”
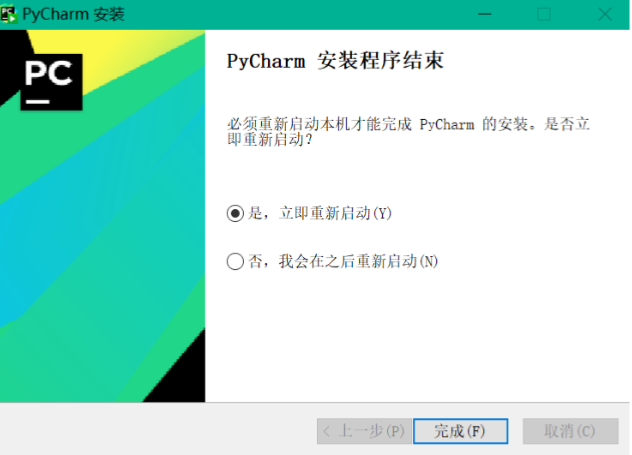
启动软件
• 选择->ok
• 勾选->点击继续
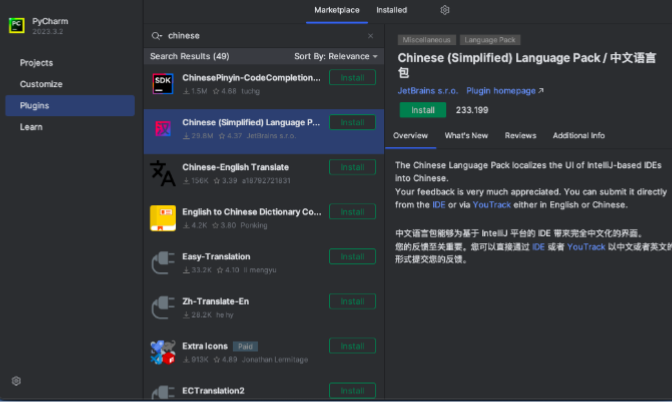
• 汉化⽅法
◦ 点击Plugins,搜索chinese
◦ 选择中⽂语⾔包
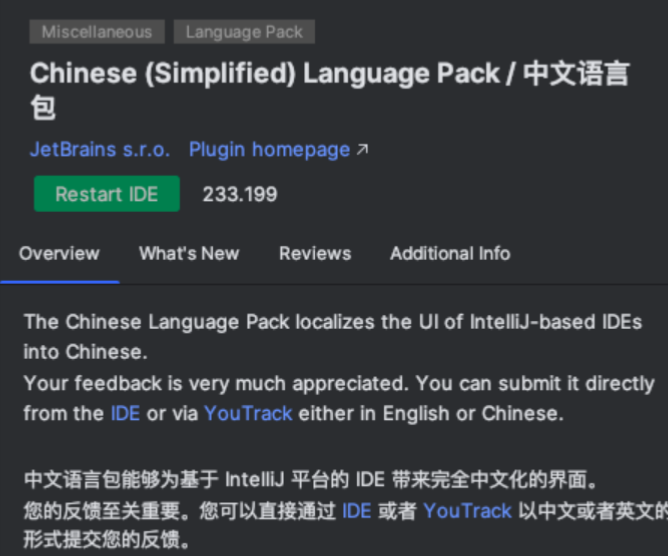
◦ 点击install
◦ 点击restart IDE,重启ide
6.使用Pycharm
新建项⽬
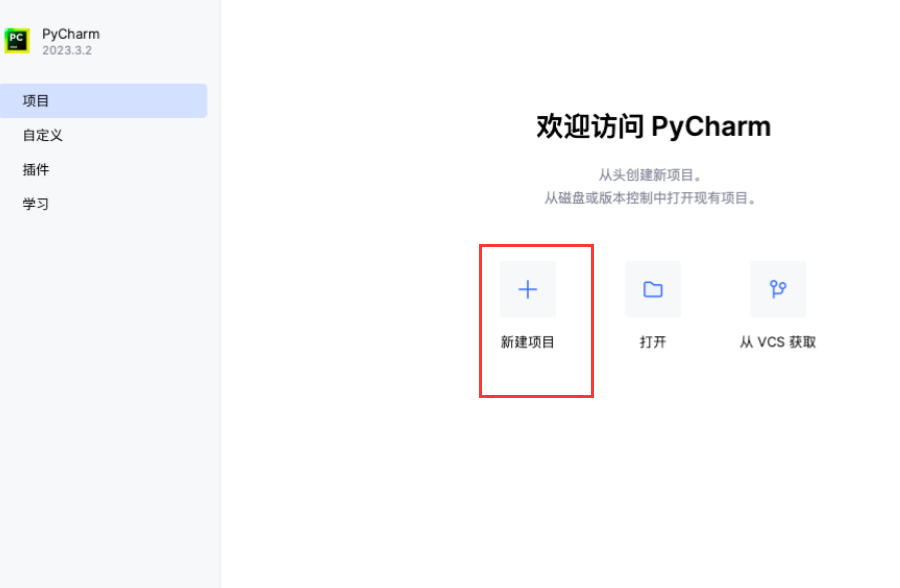
新建 Python学习 项⽬
• 选择创建⼯程位置
• 选择解释器
• 点击创建
创建成功后再新建python源代码
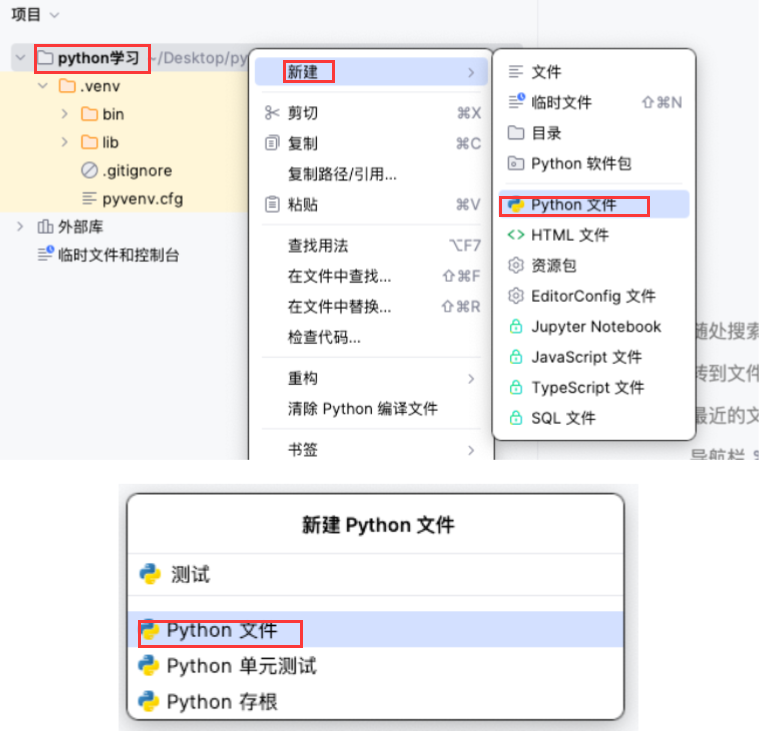
在 Python学习⽬录下新建 测试 .py ⽂件
在⽂件夹名称上点击⿏标右键,新建→python⽂件
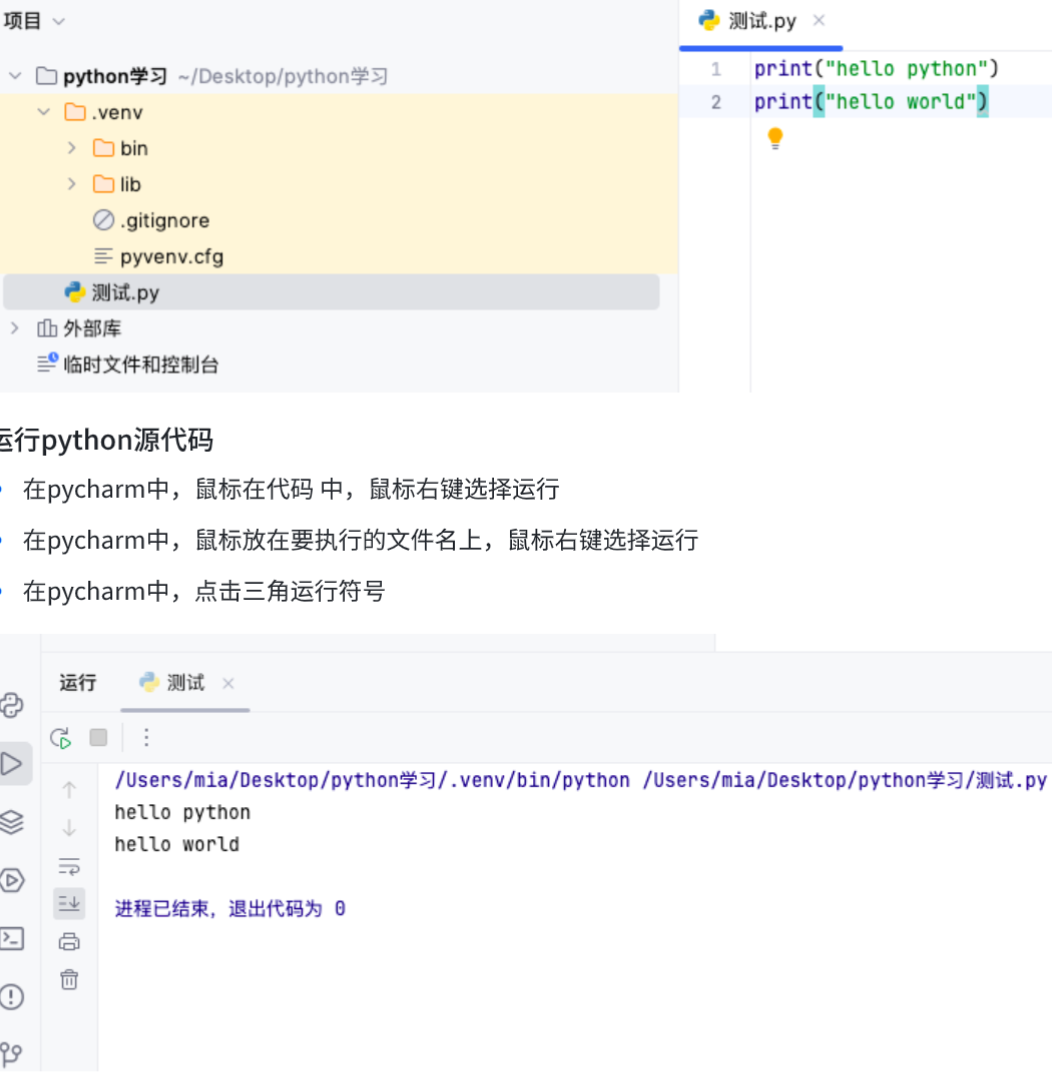
编辑python源代码
print("hello python")
print("hello world")
#print是python中我们学习的第⼀个函数
#print函数的作⽤,可以把 " " 内部的内容,输出到屏幕上

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









