






为了完成一篇结课论文,内容是对使用深度卷积神经网络模型的一些相关实验进行优化,所以就进行了相关知识的学习。
一 动态通道剪枝模块简介(Dynamic Channel Pruning,DCP)
正常的深度卷积神经网络是如下图所示,当输入数据量非常庞大时,可能会有很多冗余的计算,造成不必要的算力损失,降低效率。而当网络模型在完成迭代式的训练后,推理时就不需要这么多的参数,因此我们就可以通过剪枝,减少网络模型的计算量而达到优化的效果。
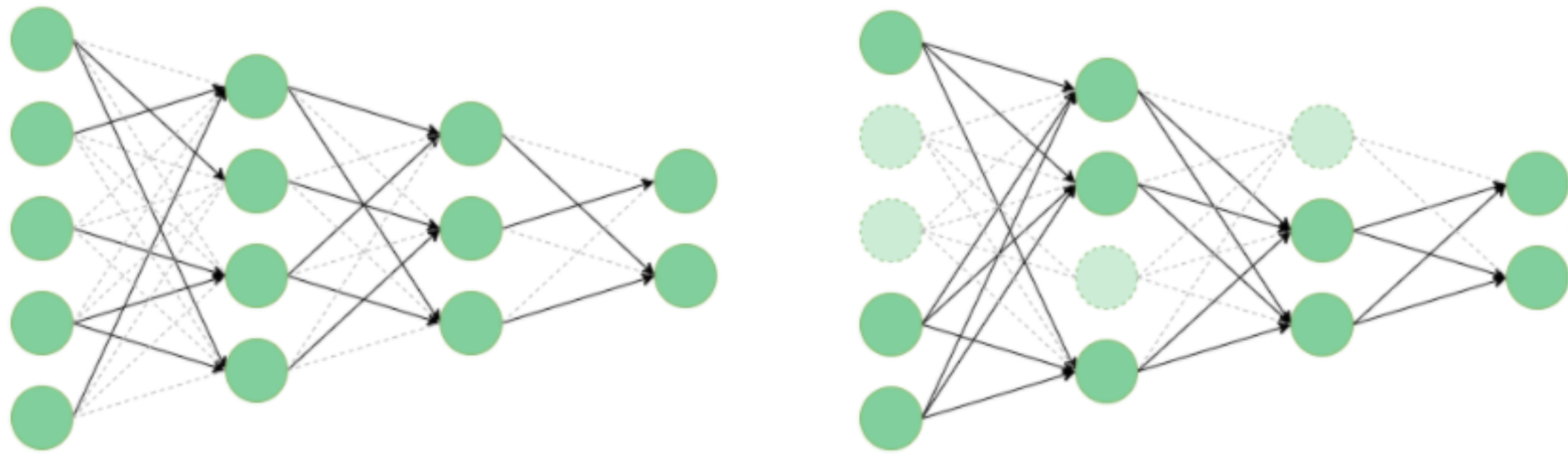
我们要根据输入的内容对网络通道进行动态调整,在保证模型性能的前提下,减少冗余计算。与静态剪枝的区别就是,动态剪枝可以根据输入的不同,有选择地关闭部分通道,自适应平衡精度和效率。
二 动态剪枝模块原理及使用
2.1 核心原理
为了保留住好的通道,我们就需要对每个通道进行重要性评估。通常基于梯度、激活值、注意力权重来分配重要性评分。根据输入样本的特征动态计算阈值,激活高于阈值的通道,关闭低于阈值的通道,即被剪枝。通过引入可微松弛函数(如Gumbel-Softmax、梯度重参数化),在训练阶段联合优化网络权重和剪枝策略,实现梯度回传的连续性。

2.2实现步骤
这里呢我是学习的用稀疏约束和遗传算法协同优化卷积核冗余通道。
传统的剪枝基于固定的稀疏约束,通过设定全局阈值裁剪权重较小的通道,导致重要特征丢失,继而导致精度的下降。因此我们再融合遗传算法,动态的优化通道。步骤如下:
(1)初始化:编码每层通道的裁剪状态,生成初始的剪枝方案。
(2)适应度函数(权重):评估剪枝后的模型在验证集的准确率(Acc)与参数量(Params),根据公式形成综合指标:
(3)遗传操作:通过交叉(单点交叉率0.7)、变异(位翻转率0.05)迭代优化种群,迭代50代后输出最优的剪枝方案。
这里再交代一下什么叫做遗传操作,就是模拟自然选择、交叉和变异的过程,逐步优化神经网络的结构和参数。遗传操作的核心步骤通常如下:
(1)初始化种群:随机生成一组数据,每组参数或一种网络结构代表一个个体。
(2)适应度评估:根据目标任务,计算每个个体的适应度。
(3)选择:保留适应度高的,淘汰适应度低的。
(4)交叉:通过交换父代的基因(即部分参数)生成子代。
(5)变异:对子代的基因进行随机扰动,增加多样性。
(6)重复迭代:直到迭代到预设的次数。
遗传操作能跳出局部最优解,寻找全局最优,但是计算成本高。同时较高的交叉率可能破坏已有的优良个体。可以用于权重的优化,逼近最优解。
(4)稀疏修正:对保留的通道施加L1正则化。
在讲解一下L1正则化:就是再模型的损失函数中增加一个与权重绝对值有关的惩罚,在训练的过程中可以减少不重要的权重。简化模型的结构,提高泛化能力:
为新损失函数,
为原损失函数,
控制正则化的强度,
为权重
通过L1正则化,让模型只保留重要的链接或者特征,同时防止了过拟合。
正则化还有L2正则化,L1正则化直接去掉了不重要的,而L2正则化则是权重整体缩小,一般不会直接去掉。
三 代码使用案例
3.1原始测试
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 设置设备(GPU/CPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 超参数
batch_size = 64
learning_rate = 0.001
num_epochs = 10
# 数据预处理与加载
transform = transforms.Compose([
transforms.RandomHorizontalFlip(), # 数据增强:随机水平翻转
transforms.RandomCrop(32, padding=4),# 数据增强:随机裁剪
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化到[-1, 1]
])
train_dataset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义深度卷积神经网络模型
class DeepCNN(nn.Module):
def __init__(self, num_classes=10):
super(DeepCNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出: 64x16x16
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出: 128x8x8
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2), # 输出: 256x4x4
)
self.classifier = nn.Sequential(
nn.Linear(256 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(1024, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1) # 展平为 (batch_size, 256*4*4)
x = self.classifier(x)
return x
model = DeepCNN().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{total_step}], Loss: {loss.item():.4f}')
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'测试集准确率: {100 * correct / total:.2f}%')
# 保存模型
torch.save(model.state_dict(), 'deep_cnn_cifar10.pth')这里使用的测试集是CIFAR-10数据集,包含10个类别的RGB彩色图片,每个图片的尺寸为32*32。
我们使用上述深度卷积代码得到的准确率为:84.15%
![]()
3.2 经过稀疏约束和遗传算法协同优化后测试
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Subset
import numpy as np
import random
from sklearn.model_selection import train_test_split
from torch.nn.utils import prune
from torch.optim.lr_scheduler import CosineAnnealingLR
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据增强与加载
def prepare_data():
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
full_train = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train)
# 划分训练集和验证集
indices = list(range(len(full_train)))
train_idx, val_idx = train_test_split(indices, test_size=0.1, random_state=42)
train_dataset = Subset(full_train, train_idx)
val_dataset = Subset(full_train, val_idx)
test_dataset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform_test)
return train_dataset, val_dataset, test_dataset
train_dataset, val_dataset, test_dataset = prepare_data()
# 改进的模型架构
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_channels)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(in_channels)
self.shortcut = nn.Sequential()
def forward(self, x):
residual = x
x = F.relu(self.bn1(self.conv1(x)))
x = self.bn2(self.conv2(x))
x += self.shortcut(residual)
return F.relu(x)
class EnhancedCNN(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(64, 2)
self.layer2 = self._make_layer(128, 2, stride=2)
self.layer3 = self._make_layer(256, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((4, 4))
self.fc = nn.Linear(256*4*4, num_classes)
def _make_layer(self, channels, blocks, stride=1):
layers = []
if stride != 1:
layers.append(nn.Conv2d(channels//2, channels, kernel_size=3, stride=stride, padding=1, bias=False))
layers.append(nn.BatchNorm2d(channels))
layers.append(nn.ReLU())
for _ in range(blocks):
layers.append(ResidualBlock(channels))
return nn.Sequential(*layers)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 渐进式剪枝器
class ProgressivePruner:
def __init__(self, model, total_prune_rate=0.5):
self.model = model
self.total_prune_rate = total_prune_rate
self.current_step = 0
self.total_steps = 8
def step(self):
if self.current_step >= self.total_steps:
return
self.current_step += 1
current_rate = self.total_prune_rate * (self.current_step / self.total_steps)
parameters_to_prune = [
(module, 'weight') for module in self.model.modules()
if isinstance(module, (nn.Conv2d, nn.Linear))
]
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=current_rate,
)
# 永久移除剪枝参数
for module, _ in parameters_to_prune:
prune.remove(module, 'weight')
# 遗传算法优化器
class GeneticOptimizer:
def __init__(self, population_size=8, generations=5):
self.population = [self.create_individual() for _ in range(population_size)]
self.generations = generations
@staticmethod
def create_individual():
return {
'prune_rate': np.clip(random.gauss(0.4, 0.15), 0.2, 0.6),
'lr': 10**random.uniform(-4, -2),
'batch_size': int(2**random.randint(5, 8)) # 32-256
}
def evaluate(self, individual, quick_eval=True):
# 训练设置
batch_size = individual['batch_size']
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
model = EnhancedCNN().to(device)
optimizer = optim.AdamW(model.parameters(), lr=individual['lr'])
pruner = ProgressivePruner(model, individual['prune_rate'])
scheduler = CosineAnnealingLR(optimizer, T_max=5)
# 快速评估模式
epochs = 5 if quick_eval else 15
best_acc = 0
for epoch in range(epochs):
# 训练阶段
model.train()
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
# 渐进剪枝(从第3个epoch开始)
if epoch >= 2:
pruner.step()
scheduler.step()
# 验证阶段
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_acc = 100 * correct / total
if val_acc > best_acc:
best_acc = val_acc
return best_acc
def evolve(self):
for gen in range(self.generations):
print(f"=== Generation {gen+1}/{self.generations} ===")
# 评估种群
fitness = []
for idx, ind in enumerate(self.population):
print(f"Evaluating individual {idx+1}:")
print(f" Prune Rate: {ind['prune_rate']:.2f}")
print(f" Learning Rate: {ind['lr']:.4f}")
print(f" Batch Size: {ind['batch_size']}")
acc = self.evaluate(ind)
fitness.append(acc)
print(f" Validation Accuracy: {acc:.2f}%\n")
# 选择精英
sorted_pop = sorted(zip(self.population, fitness), key=lambda x: -x[1])
elites = [x[0] for x in sorted_pop[:2]]
# 生成下一代
new_pop = elites.copy()
while len(new_pop) < len(self.population):
# 轮盘赌选择
parents = random.choices(
[x[0] for x in sorted_pop],
weights=[f+1e-6 for f in fitness],
k=2
)
# 交叉
child = {}
for key in parents[0]:
if random.random() < 0.5:
child[key] = parents[0][key]
else:
child[key] = parents[1][key]
# 变异
if random.random() < 0.3:
child['prune_rate'] = np.clip(child['prune_rate'] + random.uniform(-0.1, 0.1), 0.2, 0.6)
if random.random() < 0.3:
child['lr'] = 10**(np.log10(child['lr']) + random.uniform(-0.5, 0.5))
if random.random() < 0.3:
child['batch_size'] = int(2**random.randint(5, 8))
new_pop.append(child)
self.population = new_pop
# 返回最佳个体
best_ind = max(zip(self.population, fitness), key=lambda x: x[1])[0]
return best_ind
# 主流程
if __name__ == "__main__":
# 遗传算法搜索
ga = GeneticOptimizer(population_size=6, generations=3)
best_params = ga.evolve()
print("\n=== Best Parameters ===")
print(f"Prune Rate: {best_params['prune_rate']:.2f}")
print(f"Learning Rate: {best_params['lr']:.4f}")
print(f"Batch Size: {best_params['batch_size']}")
# 完整训练
train_loader = DataLoader(train_dataset, batch_size=best_params['batch_size'], shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)
model = EnhancedCNN().to(device)
optimizer = optim.AdamW(model.parameters(), lr=best_params['lr'], weight_decay=5e-4)
scheduler = CosineAnnealingLR(optimizer, T_max=30)
pruner = ProgressivePruner(model, best_params['prune_rate'])
# 三阶段训练
print("\n=== Training Phase 1: Pretraining ===")
for epoch in range(10):
model.train()
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step()
print(f"Epoch {epoch+1}/10 | Loss: {total_loss/len(train_loader):.4f}")
print("\n=== Training Phase 2: Progressive Pruning ===")
for epoch in range(10):
model.train()
# 剪枝
if epoch >= 2:
pruner.step()
# 正常训练
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Pruning Epoch {epoch+1}/10 | Loss: {total_loss/len(train_loader):.4f}")
print("\n=== Training Phase 3: Fine-tuning ===")
for epoch in range(10):
model.train()
total_loss = 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Fine-tuning Epoch {epoch+1}/10 | Loss: {total_loss/len(train_loader):.4f}")
# 最终评估
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"\nFinal Test Accuracy: {100 * correct / total:.2f}%")
torch.save(model.state_dict(), "optimized_model.pth")上述代码训练抛出的结果为:

我觉得可以使用小一点的训练集,我用的这个太大了,训练的很慢,很浪费时间,上面代码的学习率是随机的10的-4到-2次方。


















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









