







 通过R语言分析NBA球员投篮数据,包括数据导入、处理、可视化及线性回归等步骤,探讨球员得分与投篮次数的相关性。
通过R语言分析NBA球员投篮数据,包括数据导入、处理、可视化及线性回归等步骤,探讨球员得分与投篮次数的相关性。
数据集下载地址:
链接:https://pan.baidu.com/s/1KN_A9JLMvHcl0hHTBSQ4HA
提取码:spsa
第一步骤:(导入csv数据)
使用read.table()导入一个带分隔符的文本文件,其输出类型为数据框。语法如下:
read.table(file , header=F , sep=”” ,quote , row.names , col.names , na.strings=”NA” , colClasses , skip , stringsAsFactors=T, blank.lines.skip=T, strip.white=F, text,…)
| 参数 | 参数的解释 |
|---|---|
| file | 需要读入的文件名或者路径。当需要读入的文件在R的工作目录下时,file=files.name,否则file=”文件的存储路径”,如以下代码中所示。也可以更改需读入文件的储存目录为R的工作目录,然后file=file.names即可读入文件,但此法比较繁琐,一般不推荐。 |
| header | 是否文件的读入第一行,默认值为FALSE。 |
| sep | 文件中分开数据的分隔符。默认为sep=”“,表示分隔符为一个或多个空格、换行或回车。若分隔符为逗号,则sep=”,”;若为制表符,则sep=”\t”。 |
| quote | 设置如何引用字符型变量。若没有分隔符,则quote=”\”。 |
| row.names | 用于指定行名的可选参数。 |
| col.names | 若header=F,用于指定列名的可选参数.如col.names=c(“name”,”English”)。 |
| na.strings | 用于表示缺失值的字符向量。默认为NA。即将NA判断为缺失值,也可自行定义表示缺失值的字符。 |
| colClasses | 每一列的变量类型。如colClasses=c(“numeric”,”character”)表示将第一列定义为数值型,第二列定义为字符型。 |
| skip | 读取数据前跳过的行数。 |
| stringsAsFactors | 字符向量是否需转化为因子,默认值为T,可能会被colClasses所覆盖。处理大型文本文件时,设置为F可提高处理速度。 |
| blank.lines.skip | 是否跳过空白行,默认值为T。 |
| strip.white | 是否消除空白字符,默认值为F。 |
| text | 一个指定文字进行处理的字符串。若text被设置了,则无需设置file,如以上直接在程序中嵌入数据集的代码所示。 |
下面使用read.table()来读取一个分隔符为逗号,名为“shot_logs”的csv文件,代码如下:
第二步骤:(处理数据)
数据(kaggle)来源:https://www.kaggle.com/dansbecker/nba-shot-logs/discussion/22971
鉴于许多小伙伴都打不开kaggle,这里给出百度云网盘的地址。btw,fanqiang 还是比较基本的。。。。。
链接:https://pan.baidu.com/s/1KN_A9JLMvHcl0hHTBSQ4HA
百度链接
提取码:spsa
#datamining demo
setwd("D://data")#设置命名空间,即文件所在的位置
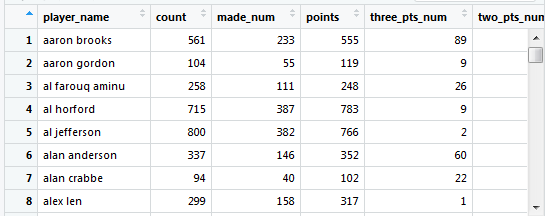
shot_logs<-read.table("shot_logs.csv",header = T,sep = ",")有关于header:(如下图header即为:player_name,如果导入数据后需要使用头行的名称,则需要将header设为T(true))
#加载包
library(dplyr)
library(magrittr)
library(ggplot2)
library(ggthemes)
library(reshape2)
#datamining demo
setwd("D://data")
shot_logs<-read.table("shot_logs.csv",header = T,sep = ",")
#定义函数,用于计算后面每位球员的2分球命中次数
two_get<-function(x){ #定义一个函数
count<-length(x)
n<-0
for(i in 1:count){
if(x[i]==2) n<-n+1 #n++
}
return(n)
}
#定义函数,用于计算后面每位球员的3分球命中次数
three_get<-function(x){
count<-length(x)
n<-0
for(i in 1:count){
if(x[i]==3) n<-n+1
}
return(n)
} #统计每位球员的投篮次数、命中次数、总得分、1分2分3分命中次数
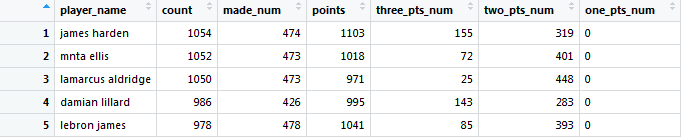
by_name<-group_by(shot_logs,player_name)%>%
summarise(count=n(),
made_num=sum(FGM),
points=sum(FGM*PTS_TYPE),
three_pts_num=three_get(as.numeric(PTS)),
two_pts_num=two_get(as.numeric(PTS)),
one_pts_num=made_num-two_pts_num-three_pts_num)
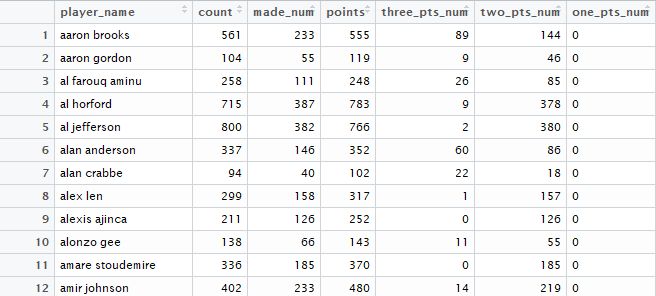
console编译:by_name
可获得如下图
:
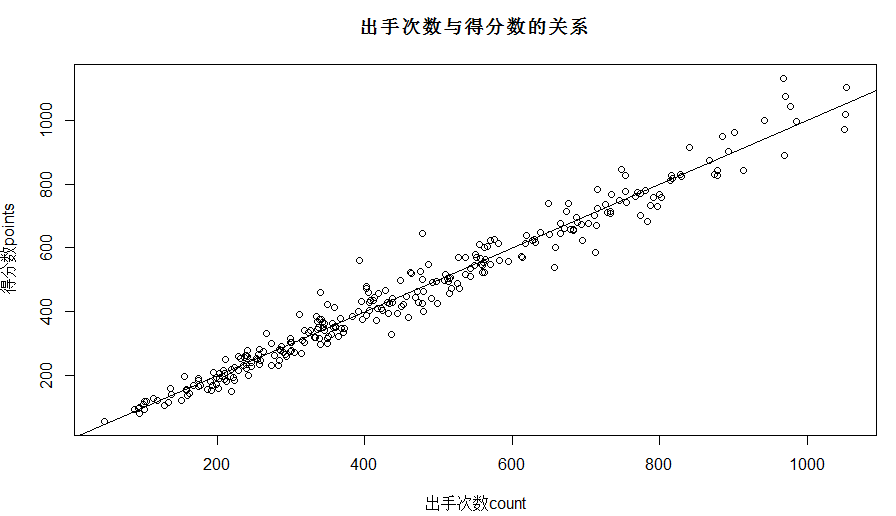
目标1:观测球员出手次数与得分是否线性相关
把count变量作为自变量,points变量作为因变量,用lm()函数做一个简单的一元线性回归:
revelant<-lm(by_name$points~by_name$count,data = by_name)
#用summary()函数得到相关参数
summary(revelant)
#用plot()函数绘制图形
plot(by_name$count,by_name$points,main="出手次数与得分数的关系",xlab = "出手次数count",ylab = '得分数points')#单双引号都可以
abline(revelant)获得的参数:Call:
lm(formula = by_name$points ~ by_name$count, data = by_name)
Residuals:
Min 1Q Median 3Q Max
-125.019 -22.961 -3.369 17.396 169.290
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.11594 5.41983 0.021 0.983
by_name$count 0.99706 0.01062 93.876 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 40.86 on 279 degrees of freedom
Multiple R-squared: 0.9693, Adjusted R-squared: 0.9692
F-statistic: 8813 on 1 and 279 DF, p-value: < 2.2e-16
根据summary()函数得到的参数我们可以看到,两个变量之间的相关系数是0.997,P值为2e-16远远小于0.05,而R-squared判定系数为0.969(表示回归直线可解释96.9%的总变差),说明两者显著相关,从图上也可以看出其相关性非常好,散点基本落在直线两侧,这也说明教练对于球员上场的安排情况十分合理,不存在投篮次数过多而得分较少或者得分很高但是投篮机会却很少的情况。
目标2:查看总得分前五名的球员和出手次数前五名的球员
代码如下:
#得分前五
by_name.1<-by_name[order(-by_name$points),]
by_name.1<-by_name.1[1:5,]
#出手次数前五
by_name.2<-by_name[order(-by_name$count),]
by_name.2<-by_name.2[1:5,]得分前5:
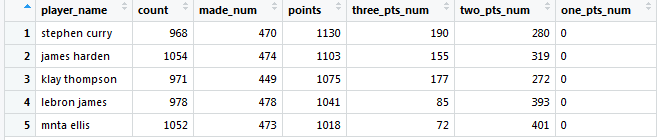
出手次数
目标3:得分前五名的球员在不同距离的投篮命中情况
#从数据原中挑出前五名球员的完整数据
data.1<-filter(shot_logs,
player_name=='mnta ellis'|
player_name=='lebron james'|
player_name=='klay thompson'|
player_name=='james harden'|
player_name=='stephen curry')
#根据不同球员的投篮次数和命中次数绘制分面直方图
ggplot(data=data.1,aes(SHOT_DIST,fill=factor(FGM)))+
geom_histogram()+
facet_grid(.~player_name)+
theme_few()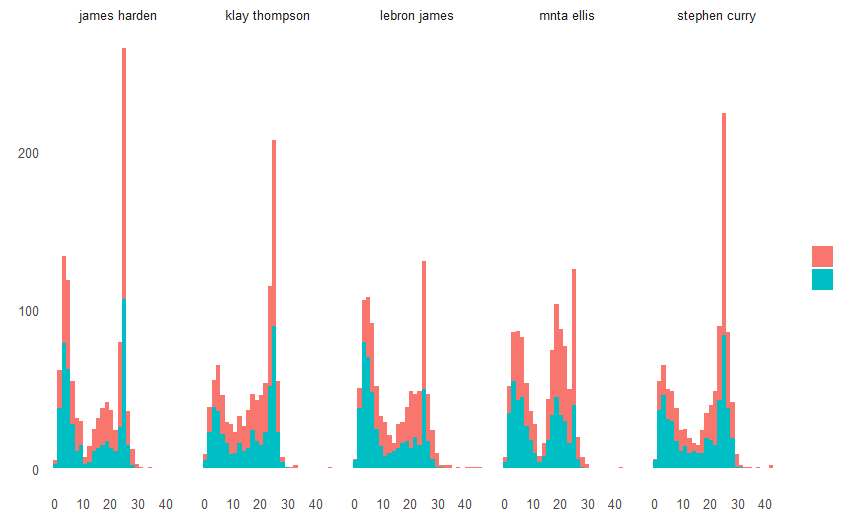
stephen curry(库里)的表现相对来说是比较稳定的,而lebron james(詹姆斯)则在三分线内表现较好
目标4:得分前五名的球员命中2分球和3分球所占比例
#只留下命中的数据
data.2<-filter(data.1,data.1$FGM==1)
#根据得分情况绘制堆叠图
ggplot(data = data.2,aes(x=player_name,fill=factor(PTS)))+
geom_bar()+
theme_few()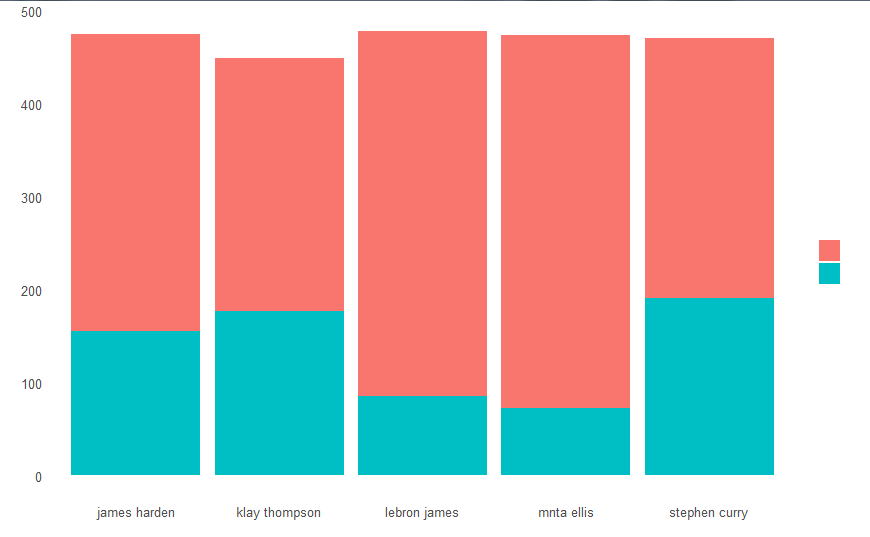
stephen curry(库里)的三分和二分比例最协调,而lebron james(詹姆斯)二分命中次数更多一些。
目标5:得分前五名的球员命中次数与距离的变化情况
ggplot(data=data.2,aes(x=SHOT_DIST))+
geom_density()+
facet_grid(player_name~.)+
theme_few()
项目推荐:
Java微服务实战296集大型视频-谷粒商城【附代码和课件】
Java开发微服务畅购商城实战【全357集大项目】-附代码和课件


















 2970
2970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









