







目录
概述:
本实验对霍普金森大学统计的新冠数据进行处理,对各个国家新增病例进行可视化,并且使用LSTM、GRUNet时间序列预测模型对数据进行训练拟合,并讨论不同的序列长度对网络预测的影响,并对美国的每日新增病例进行预测,对我国累计确诊病例进行预测,以俄罗斯为例分析每日新增和累计确诊病例预测难度,并对结果进行分析。
分析问题:
新冠病毒肆虐全球,美国每天新增感染人数已接近100万人,从19年以来,新冠势头不减,能够合理、正确的预测新冠病毒的走向,对于安排恢复生产、生活,具有十分重要的意义和价值。
每日新增病例属于时间序列数据,每日新增病例数不仅与病毒的感染能力有关,也和地区的人口、国家防疫措施、疫苗接种情况、病毒种类等有关系。所以是个十分复杂的问题,在此为简单起见,仅将其看作时间序列数据,由于找不到感染不同种类新冠病毒的病例数据,故将其都看作同一种病毒对待,使用课上讲过的典型的RNN系列网络进行预测求解。
方法介绍:
RNN网络:
循环神经网络是指一个随着时间的推移,重复发生的结构。在自然语言处理(NLP),语音图像等多个领域均有非常广泛的应用。RNN网络和其他网络最大的不同就在于RNN能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。如同人类能够凭借自己过往的记忆更好地认识这个世界一样。RNN也实现了类似于人脑的这一机制,对所处理过的信息留存有一定的记忆,而不像其他类型的神经网络并不能对处理过的信息留存记忆。
循环神经网络通过使用带自反馈的神经元,能够处理任意长度的时序数。给定一个输入序列x1:T=x1,x2,…,xt,…,xT,循环神经网络通过下面公式更新带反馈边的隐藏层的活性值ht
ht=fht-1,xt

循环神经网络
LSTM:
Long Short Term 网络,一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力。
相比普通的RNN,LSTM能够在更长的序列中有更好的表现。在原始RNN的基础上,LSTM网络主要改进在以下两个方面:
新的内部状态。LSTM网络引入一个新的内部状态ct∈RD专门进行线性的循环信息传递,同时(非线性地)输出信息给隐藏层的外部状态ht∈RD,内部状态ct通过下面的公式计算:
ct=ft⊙ct-1+it⊙ct#2
ht=ot⊙tanhct#3
其中ft∈[0,1]D、it∈[0,1]D和ot∈[0,1]D为三个门来控制信息传递的路径;⊙为向量元素乘积;ct-1为上一时刻的记忆单元;ct∈RD是通过非线性函数得到的候选状态:
ct=tanhWcxt+Ucht-1+bc#4
在每个时刻𝑡,LSTM 网络的内部状态ct记录了到当前时刻为止的历史信息。
门控机制。在数字电路中,门为一个二值变量{0, 1},0代表关闭状态,不许任何信息通过;1代表开放状态,允许所有信息通过。
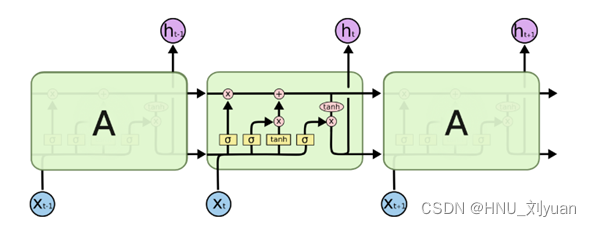
LSTM网络的循环单元结构
GRU:
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流行的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。GRU和LSTM在很多情况下实际表现上相差无几,但是更容易计算。GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。与LSTM相比,GRU内部少了一个“门控”,参数比LSTM少,但是却也能够达到与LSTM相当的功能。
其中h'的更新公式如下:
ht=1-z☉ht-1+z☉h'
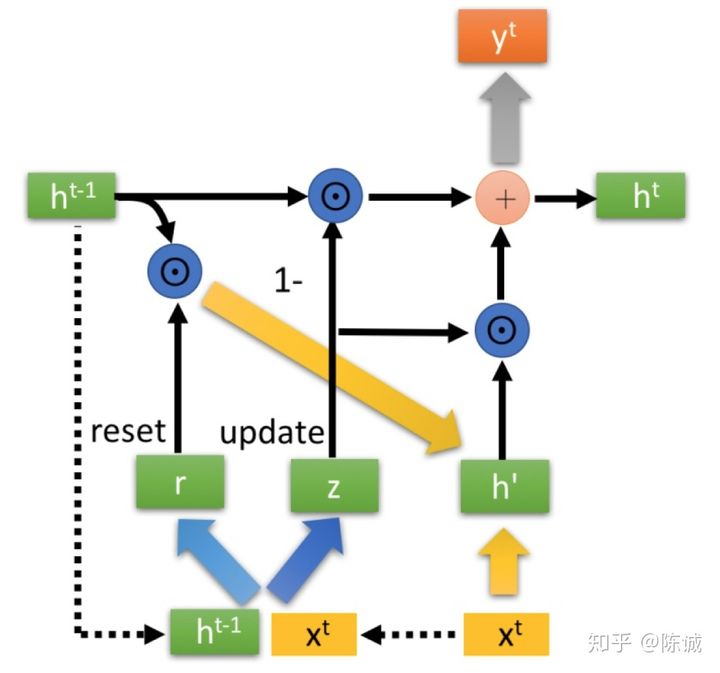
GRU结构
新冠数据:
数据集来自于GitHub上美国霍普金森大学统计的全球新冠感染人数,链接如下:COVID-19/csse_covid_19_data at master · CSSEGISandData/COVID-19 · GitHub
通过对几个国家每日新增数据进行可视化可以得到:
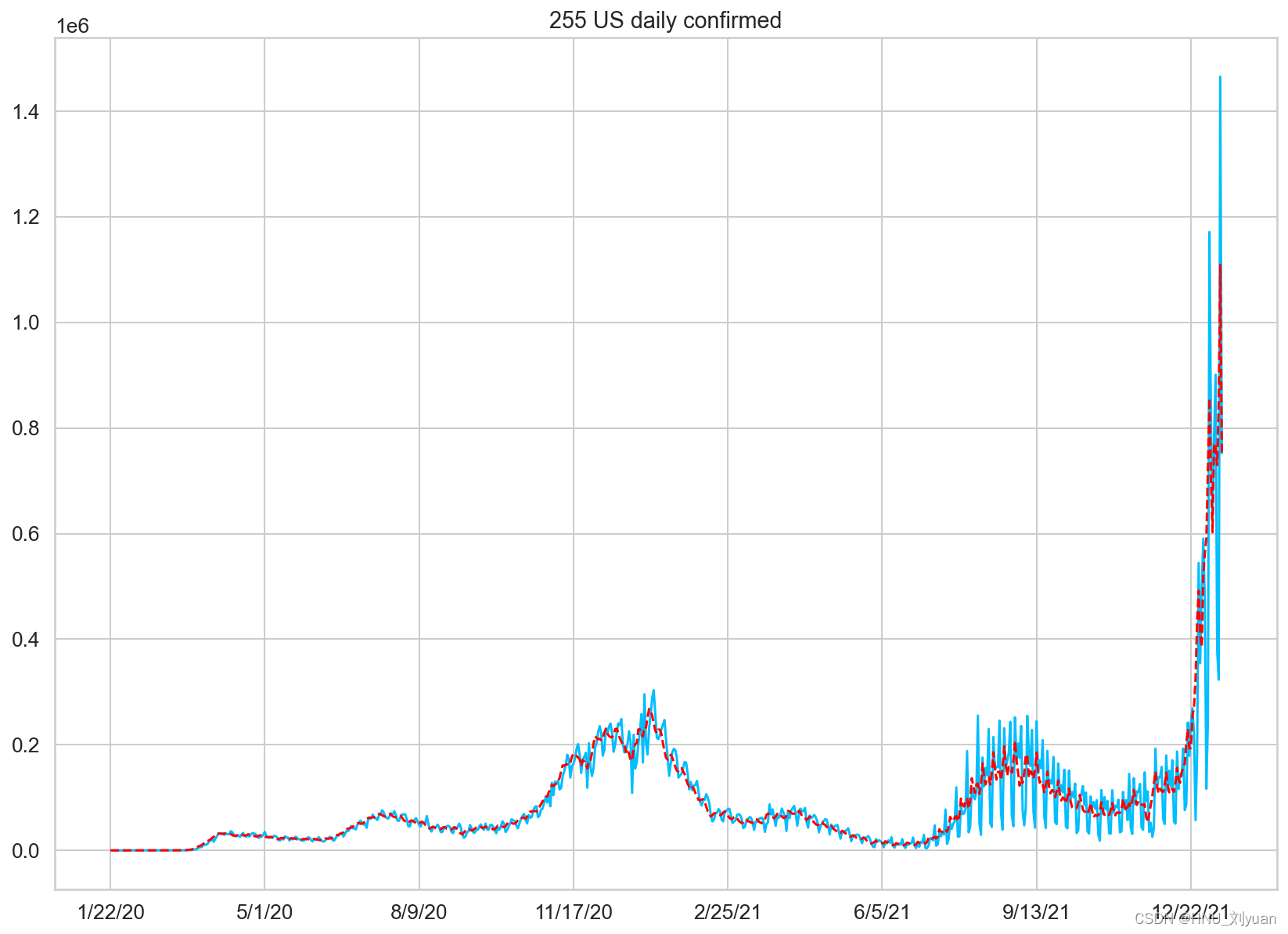
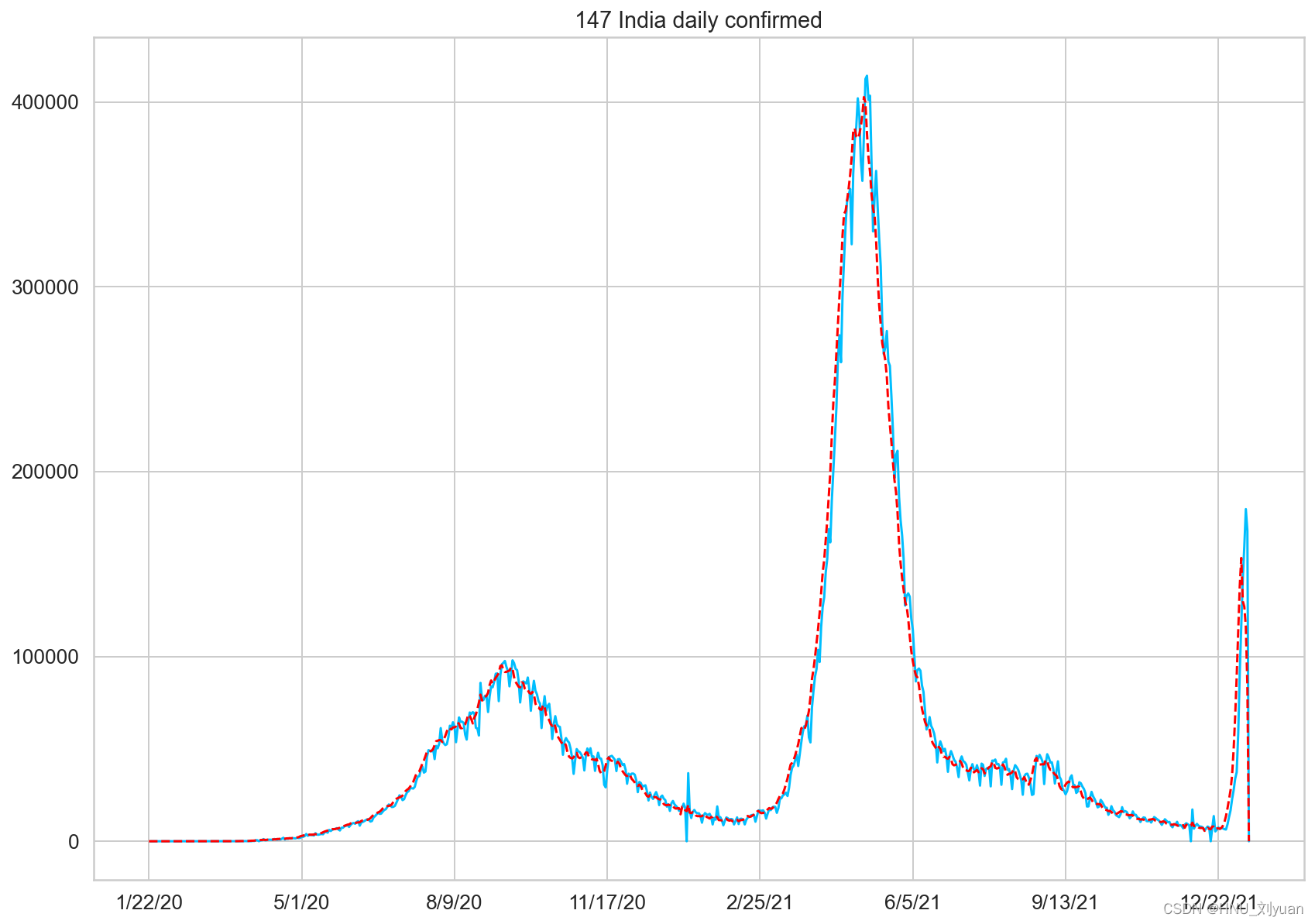
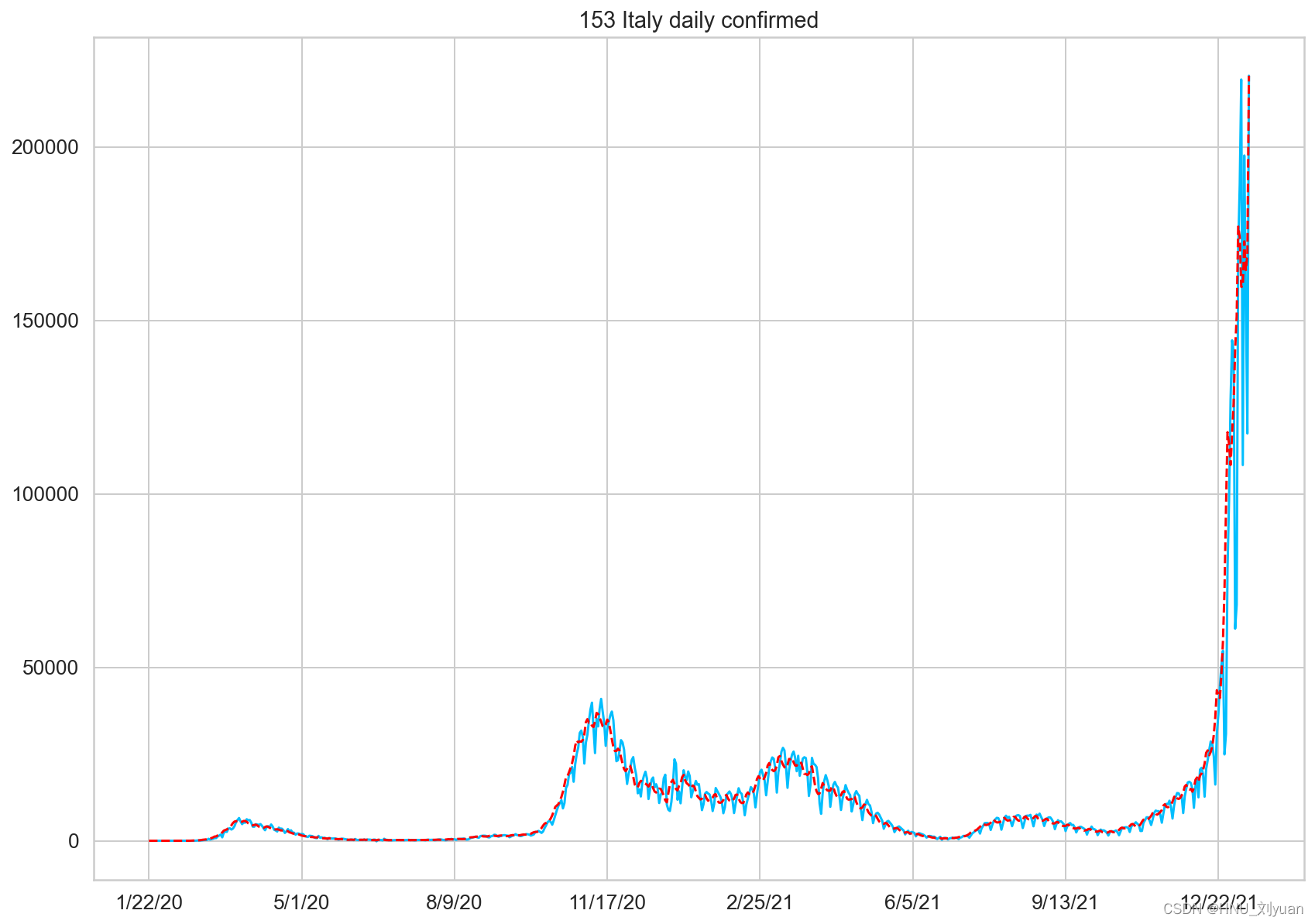
部分国家地区单日新增确诊人数
其中蓝线为每日新增人数,红线为平滑后的数值。可以看出,每日新增的数据是震荡的,不那么平滑,并且可能存在好几个峰值。对于大部分国家而言,在2021年底新增确诊人数都有一个较大的提升,推测应该是由于变异病毒奥密克戎的影响,传染率更高。
全球疫情可视化:
使用pyecharts库对全球疫情进行可视化得到:
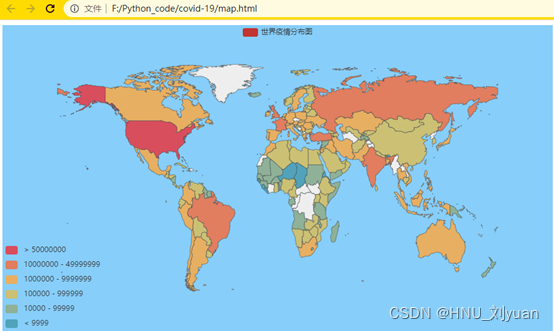
全球疫情可视化
从地图上来看,几乎所有的国家都遭到了疫情的影响,其中美国的确诊人数最多,巴西、俄罗斯和印度,确诊人数次之,也较严重。少数几个国家由于没有统计数据,所以是空白。
实验模型:
采用两种模型进行预测,即LSTM和GRUNet,进行对比:
LSTM:
- class LSTMNet(nn.Module):
- def __init__(self, input_size = 1):
- super(LSTMNet, self).__init__()
- self.rnn = nn.LSTM(
- input_size=input_size,
- hidden_size=64,
- num_layers=1,
- batch_first=True,
- )
- self.out = nn.Sequential(
- nn.Linear(64, 1)
- )
- self.relu = nn.ReLU()
- def forward(self, x):
- r_out, (h_n, h_c) = self.rnn(x.view(len(x), seq_length, -1), None)
- out = self.out(r_out[:, -1])
- out = self.relu(out)
- return out
GRUNet:
- class GRUNet(nn.Module):
- def __init__(self, input_size = 1):
- super(GRUNet, self).__init__()
- self.rnn = nn.GRU(
- input_size=input_size,
- hidden_size=64,
- num_layers=1,
- batch_first=True,
- bidirectional=True
- )
- self.out = nn.Sequential(
- nn.Linear(128, 1)
- )
- self.avgpool = nn.AdaptiveAvgPool2d((1,128))
- def forward(self, x):
- r_out, (h_n, h_c) = self.rnn(x, None)
- out = self.avgpool(r_out.unsqueeze(0))
- out = out.squeeze(2).squeeze(0)
- out = self.out(out)
- return out
LSTM一般是对序列数据进行预测,将数据集按照一定的比例划分成训练数据和测试数据,送入LSTM的数据有着固定的长度,即seq_length,根据seq_length单位长度的数据,预测下一个数据。首先要将训练数据进行划分成训练数据和标签,使用以下函数进行划分:
- def create_sequences(data, seq_length):
- xs = []
- ys = []
- for i in range(len(data)-seq_length-1):
- x = data[i:(i+seq_length)]
- y = data[i+seq_length]
- xs.append(x)
- ys.append(y)
return np.array(xs), np.array(ys)
数据集序列数据生成:
假如seq_length为5,训练数据为[1,2,3,4,5,6,7,8,9]时,可以得到如下的训练数据划分:
训练集序列数据生成示意表
| 训练数据 | 预测数据 | ||||
| 1 | 2 | 3 | 4 | 5 | 6 |
| 2 | 3 | 4 | 5 | 6 | 7 |
| 3 | 4 | 5 | 6 | 7 | 8 |
| 4 | 5 | 6 | 7 | 8 | 9 |
一般来说,当seq_length越大,计算的复杂度越大,同时预测精度也会更高。
自己生成1-1000的线型数据,作为测试,划分不同比例的数据作为训练集和测试集,探究seq_length对拟合数据的影响。固定测试集的比例为0.3,当seq_length为5时,即使用5个数据预测下一数据,预测的数据作为输入再预测下一个数据。得到:
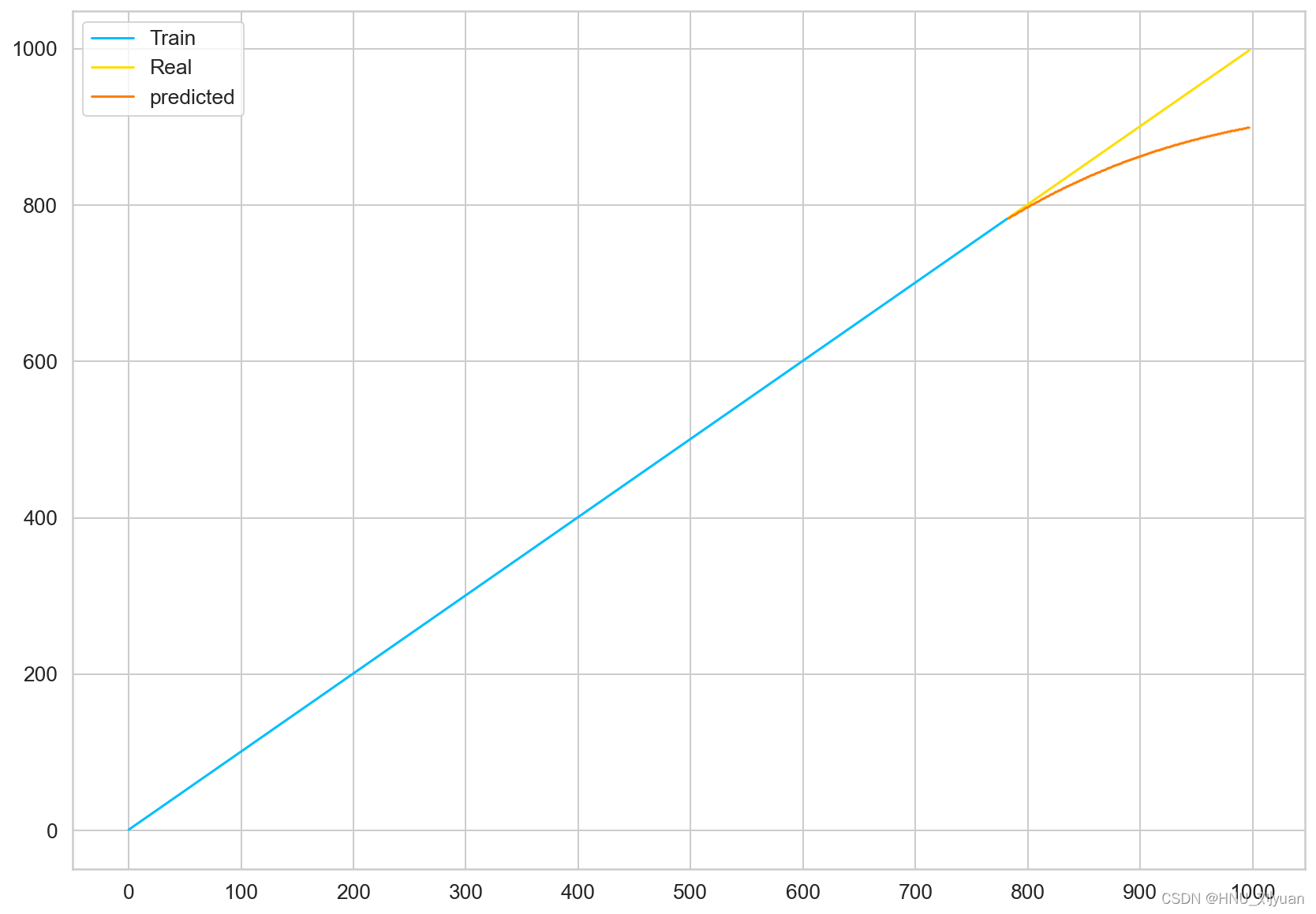
Seq_length=5,对直线进行拟合
将其进行归一化和真实数据进行平方差计算得到,误差评价值:0.565。从图上可以看出,预测数据在下半段有向下的趋势。
当seq_length为15时,即使用15个数据预测下一数据,预测的数据作为输入再预测下一个数据。得到:
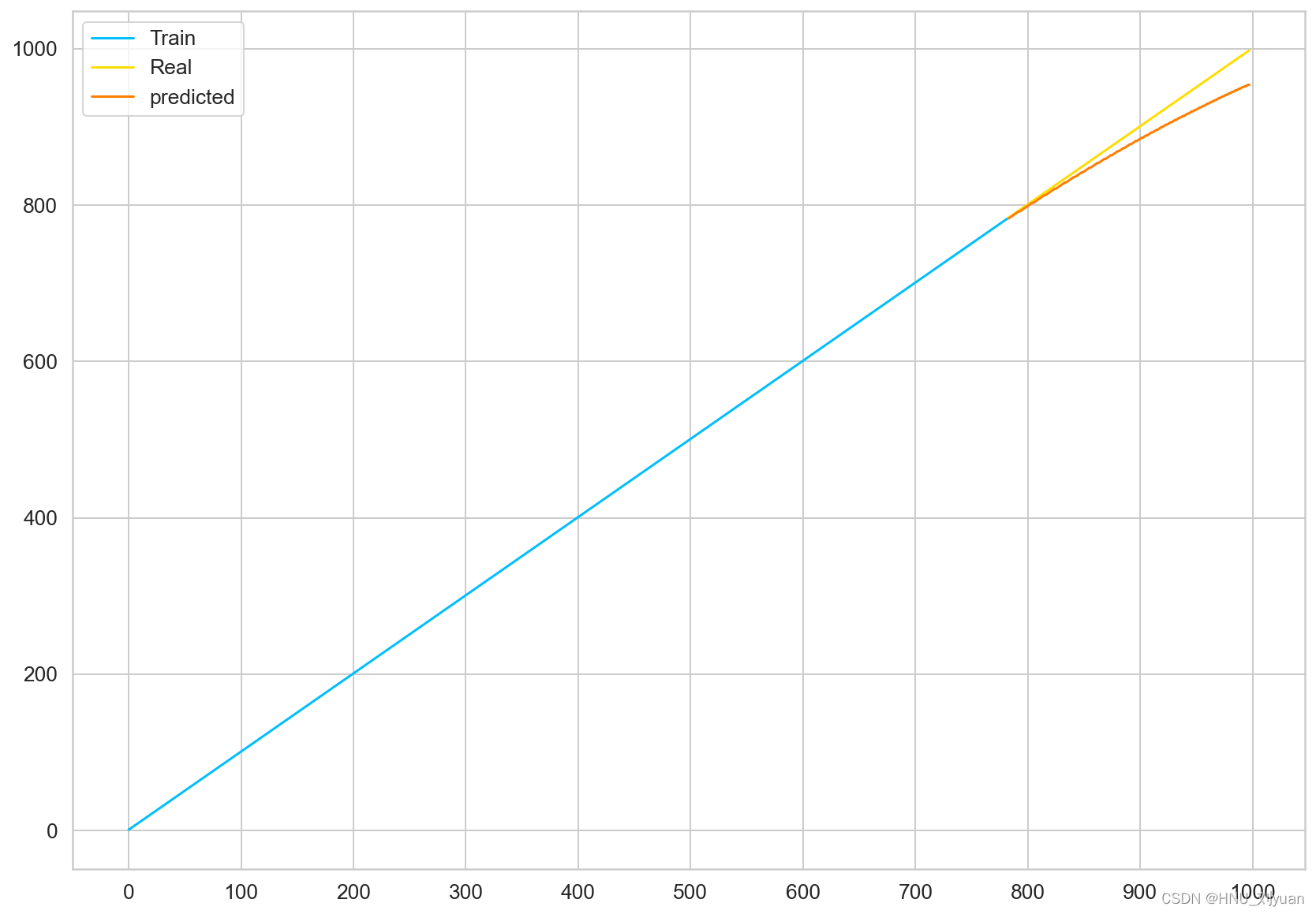 Seq_length=15,对直线进行拟合
Seq_length=15,对直线进行拟合
同样将其进行归一化和真实数据进行平方差计算得到,误差评价值:0.105。从图上可以看出,和seq_length为5时相比,其预测效果要好得多,但是也有向下的趋势。
使用原始数据中的每日新增数据当做训练集(预测总的患病人数可能更简单),使用GRUNet进行训练得到:
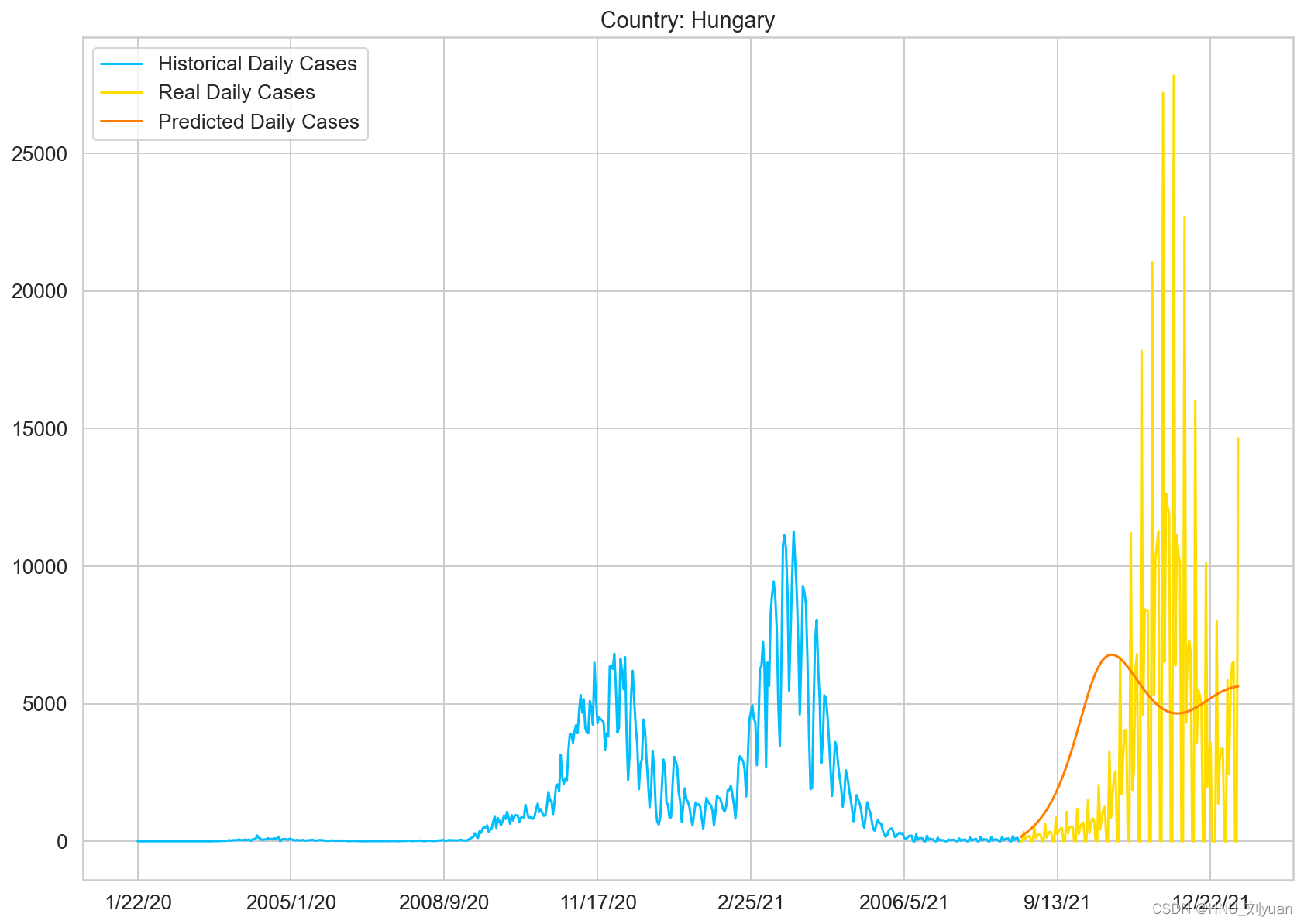
使用GRUNet对原始数据进行预测
可以看到原始数据的抖动非常大,不利于预测,所以使用长度为5的序列进行“均值滤波”处理,处理之后的数据稍微平滑,得到的预测结果如下:
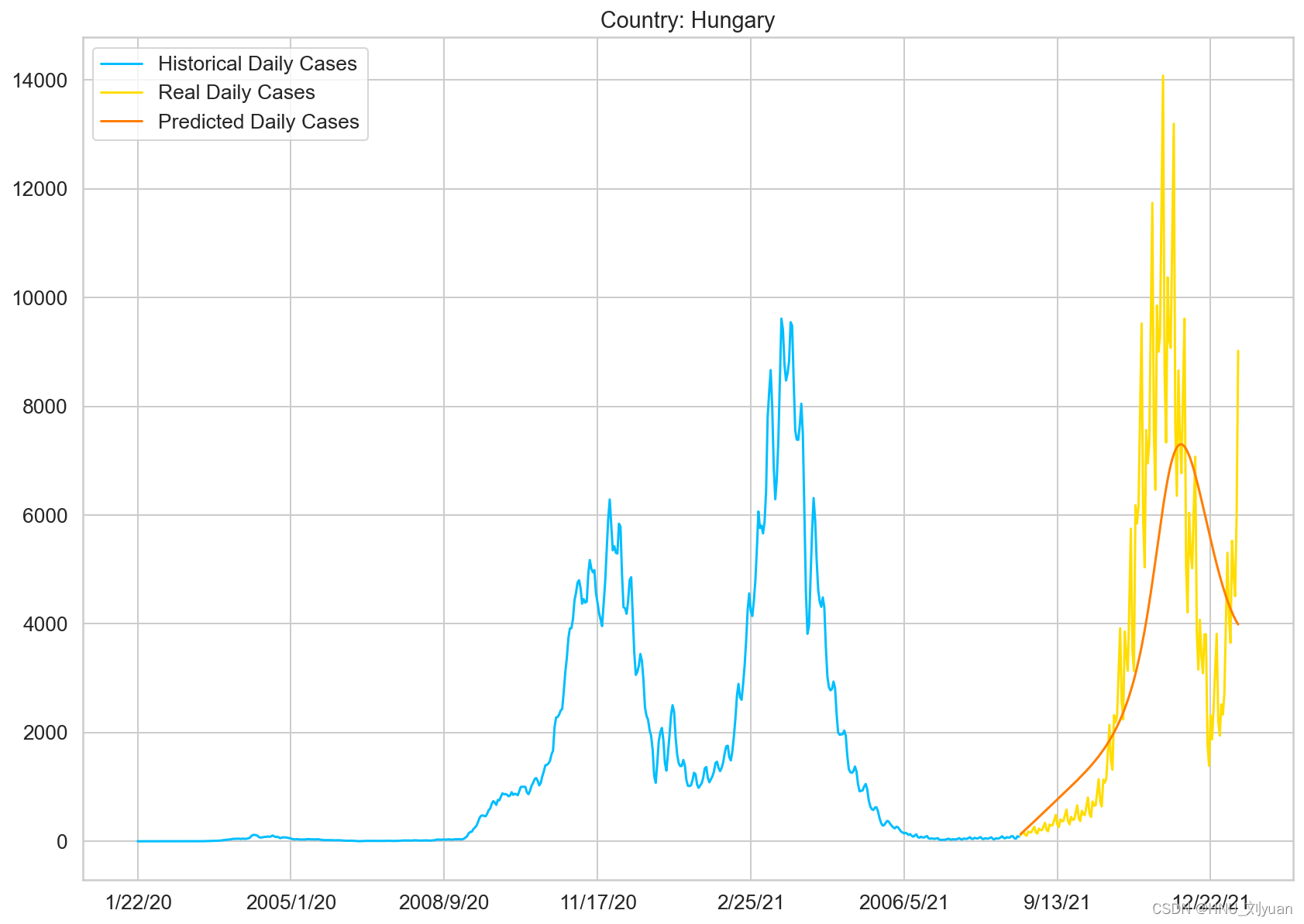
使用GRUNet对平滑后数据进行预测
让人十分惊奇的是,模型居然能够预测出下一个波峰的到来,虽然存在一定的偏差。
再将网络改为LSTM,预测序列长度为30,进行训练得到预测结果如下:
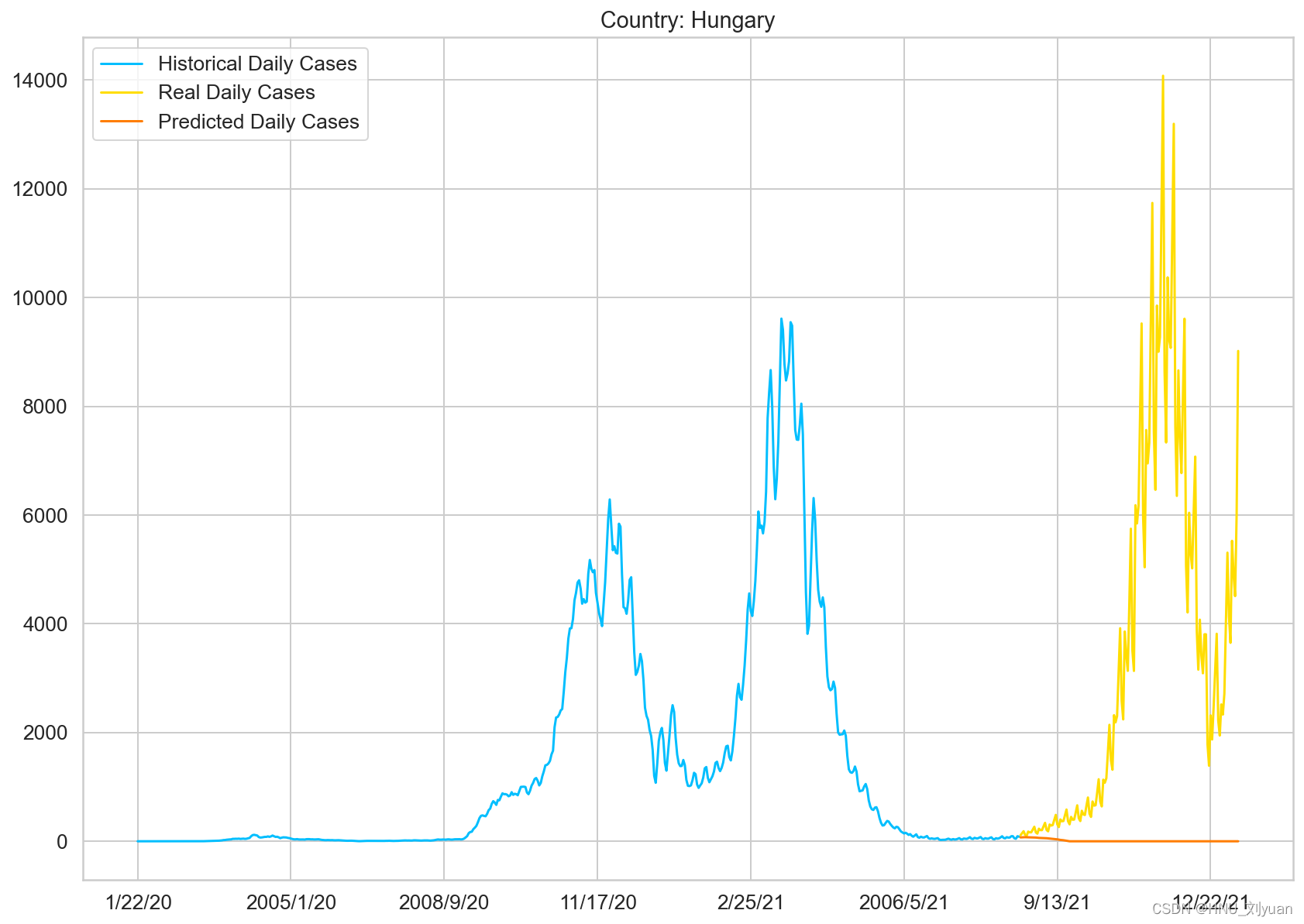
使用LSTM对平滑后数据进行预测
可以结果图可以看出,预测趋势与GRUNet相差很大,根据LSTM给出的预测,后期应该是无新增病例,这个趋势也是比较符合左侧变化趋势的直观感觉的,但是后期又出现了一个小高峰。不同类型的网络,对疫情的预测差别较大。
对美国每日新增病例进行预测
对美国每日新增的数据进行可视化得到:
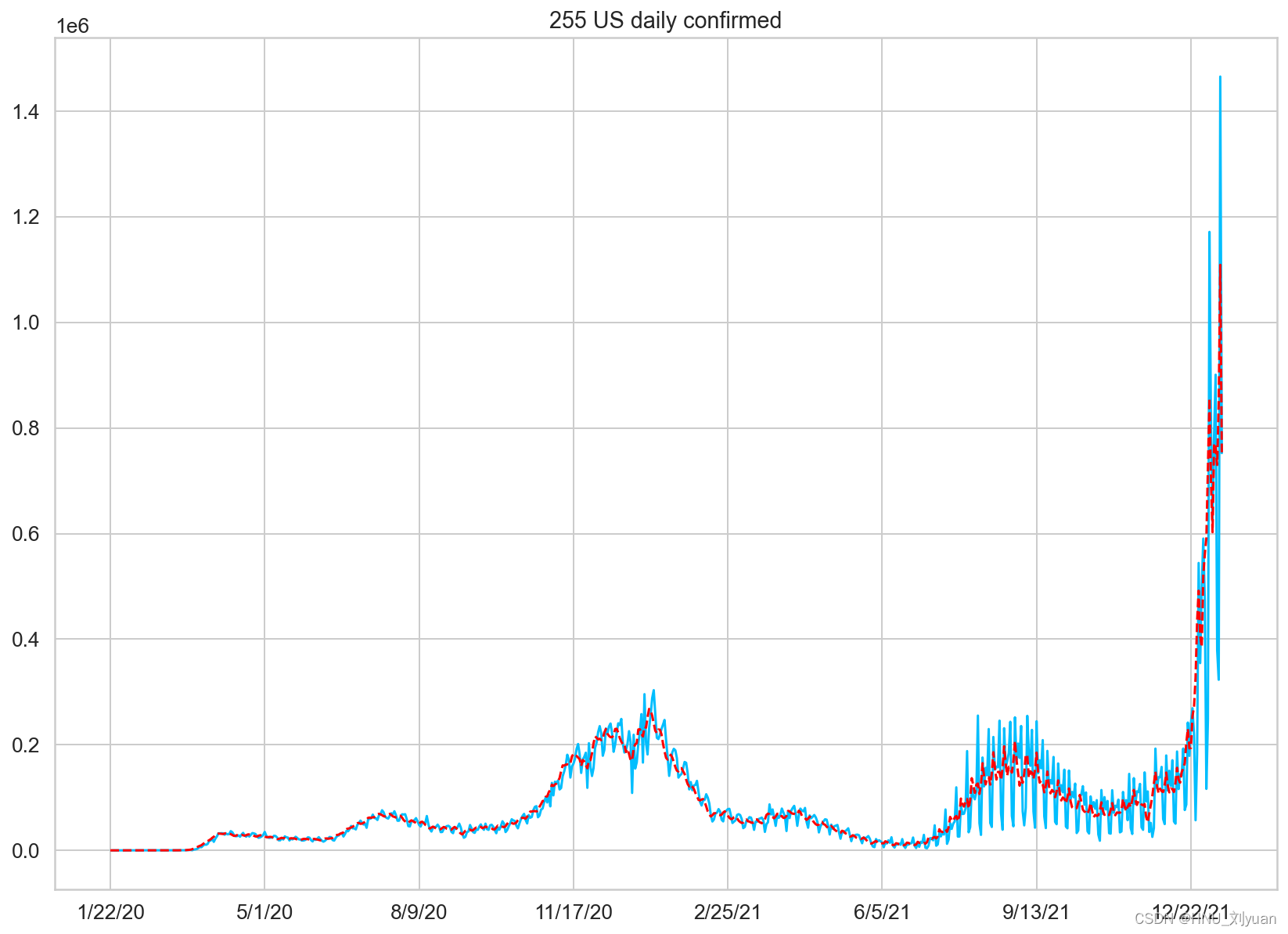
美国单日新增病例可视化
美国每日新增确诊人数之前在20万左右浮动,但是到了21年末,确诊人数激增,猜测应该是病毒变异的影响,新冠病毒变异产生了感染性较强的贝塔病毒,最近又有了奥密克戎,奥密克戎使得美国单日新增人数来到了100万左右,感染人数增加了四、五倍之多。可见变异病毒感染能力之强。
LSTM对美国进行预测:
对美国模型的数据使用LSTM训练1500个epoch,初始学习率为1e-3,学习率调整策略为余弦衰减,损失函数设置为MSE,训练过程中的lr衰减、loss变化图以及预测图如下图所示:
学习率的变化
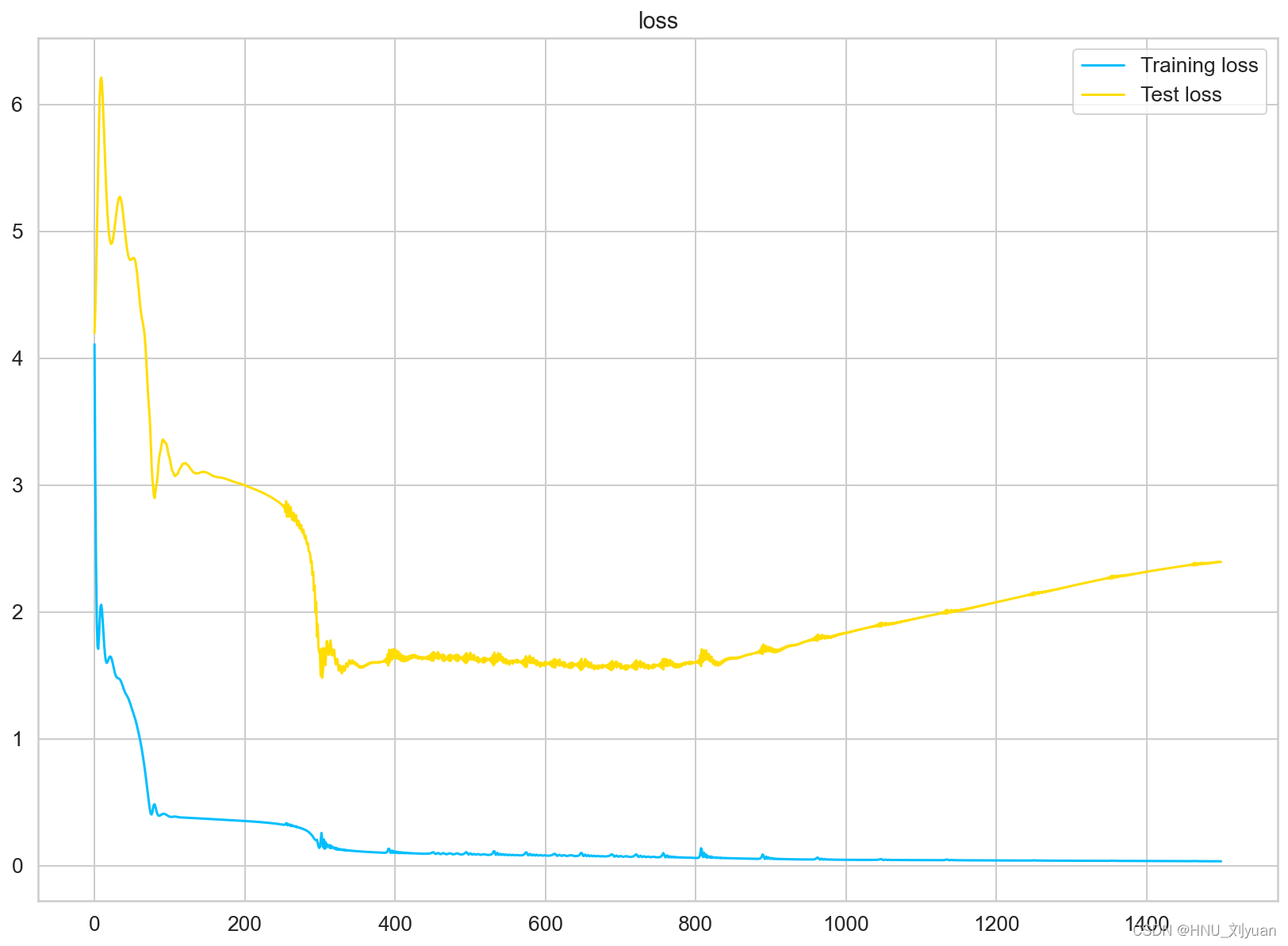
使用LSTM对美国进行训练过程中loss的变化
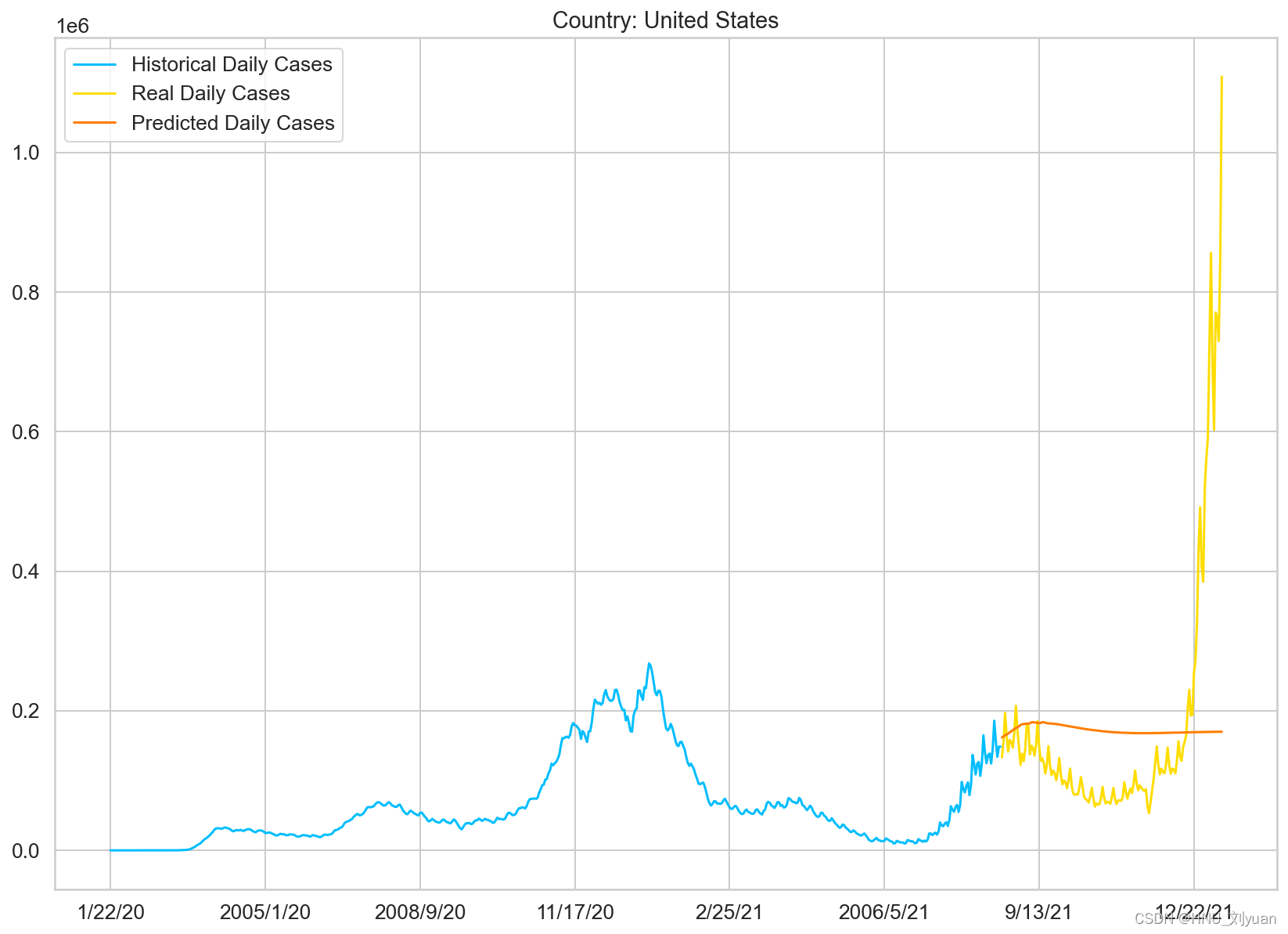
使用LSTM对美国每日新增疫情的预测
GRUNet对美国进行预测:
使用相同的训练设置训练GRUNet得到:
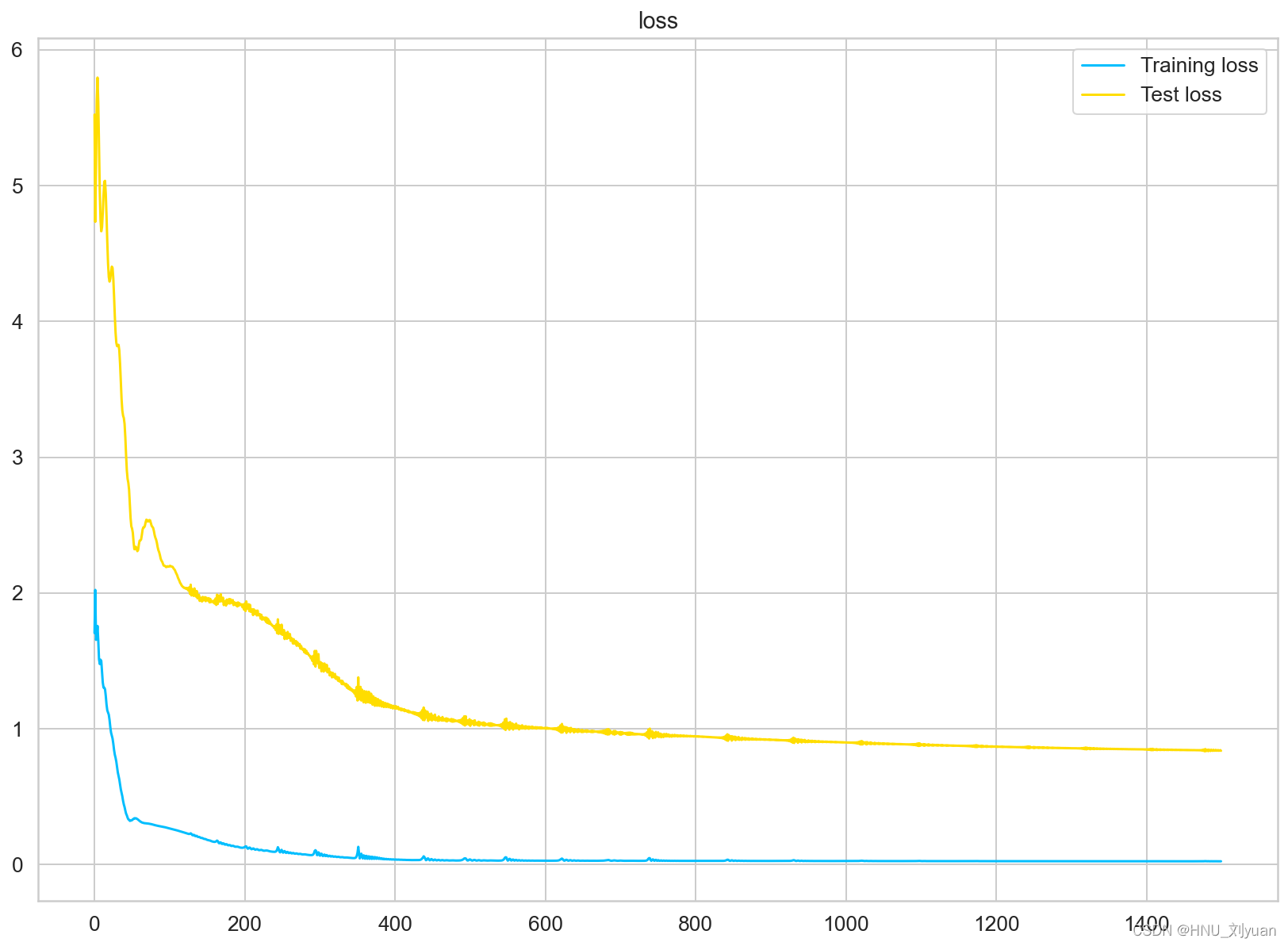
使用GRUNet对美国进行训练过程中loss的变化
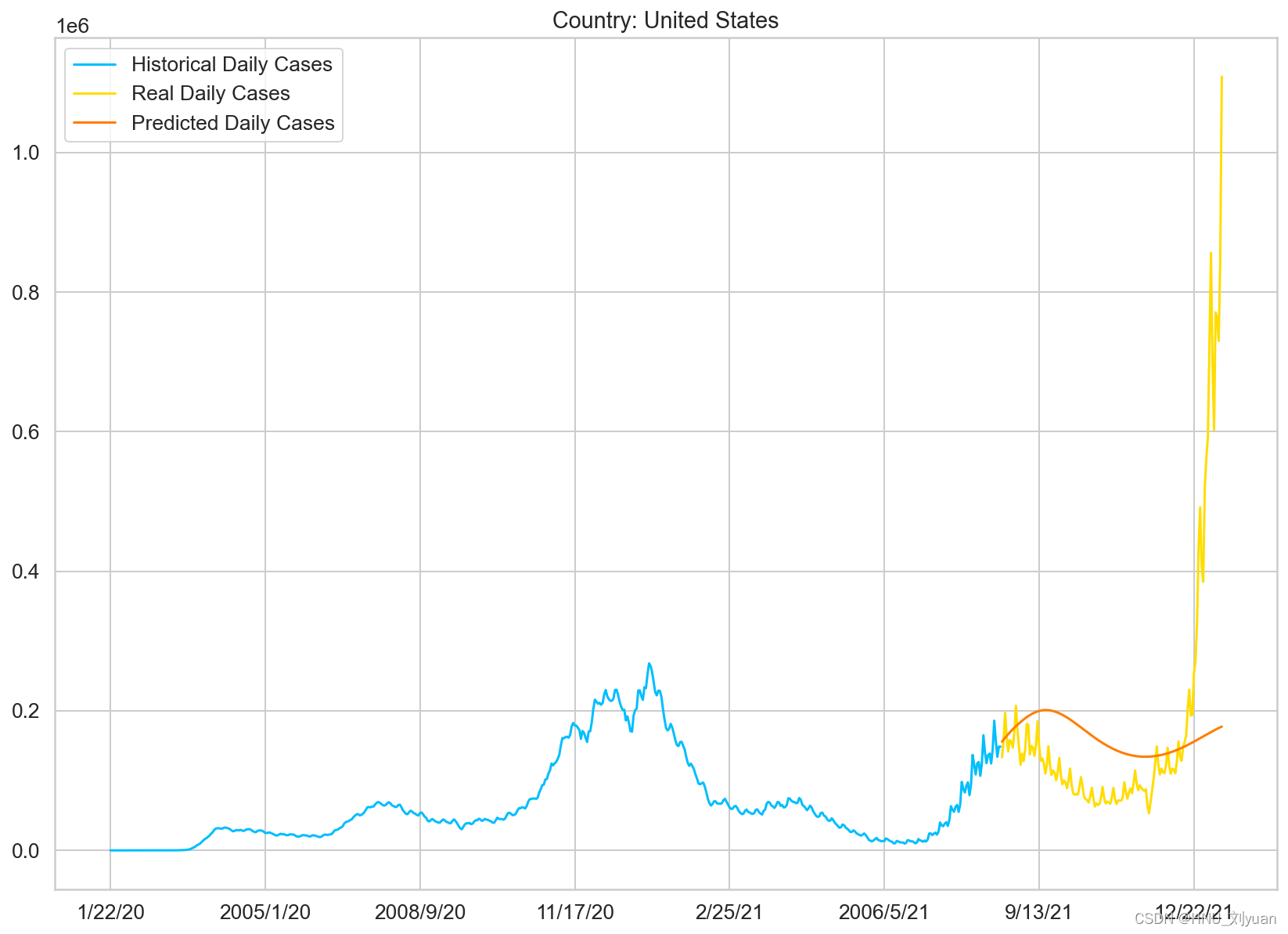
使用GRUNet对美国每日新增疫情的预测
从预测结果可以看出模型并不能够很好的预测美国未来单日新增人数,因为病毒是在变异的,后面的传染性更强,这些信息是无法从之前的序列数据中推测出来,所以由于美国没有很好的进行抗疫,任由病毒发展,加上病毒的变异,所以两种模型都不能够很好的预测出来未来的走势。
每日新增和累计感染预测难度对比
以俄罗斯为例,分别使用两个模型对每日新增病例数和累计新增病例数进行预测,得到:

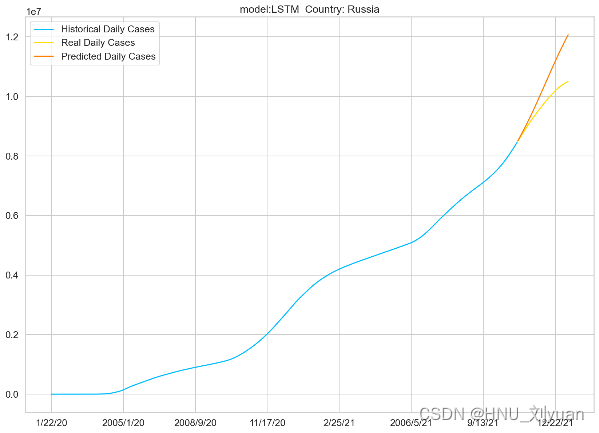
使用LSTM、GRUNet对俄罗斯累计感染人数的预测
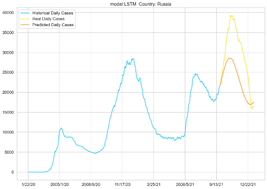
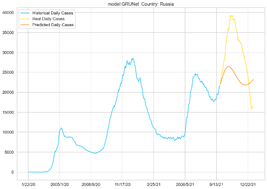
使用LSTM、GRUNet对俄罗斯每日新增感染人数的预测
从图上可以看出,对于每日新增的感染人数的预测误差要大于对于累计确诊的感染人数,所以从预测难度上来说,预测每日新增人数要难于预测累计确认人数,每日新增人数是波动的,有可能增加也可能减少,对于累计确诊人数的预测,可以依托于之前的数据趋势进行拟合得到。
总结
日常生活中序列数据十分常见,比如股票、气温、湿度等,能够准确的预测出来,对于生产生活都有着非常重要的作用。这次使用LSTM、GRUNet对新冠疫情的感染人数进行预测,使我了解并掌握了RNN相关的原理和应用。从预测结果上来看,有的预测结果差强人意,但是有的效果较差,可能需要考虑更多的因素进去。从预测结果可得到以下的启示:预测累计感染人数要比预测每日新增人数简单;预测的结果越长,后面越不准确;使用的预测序列越长结果越准确;最近的病毒变异导致感染人数激增是模型预测不出来的;以及正确的抗疫措施是非常重要的。
代码地址为:github链接














 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









