







什么是PG流复制?
Streaming Replication是pg9.0开始提供的传递WAL日志的方式,只要primary库一产生日志,就会立马传递到standby库。
在pg9.0之前,pg只能一个个传送wal日志(log shipping),备库至少比主库落后一个wal日志
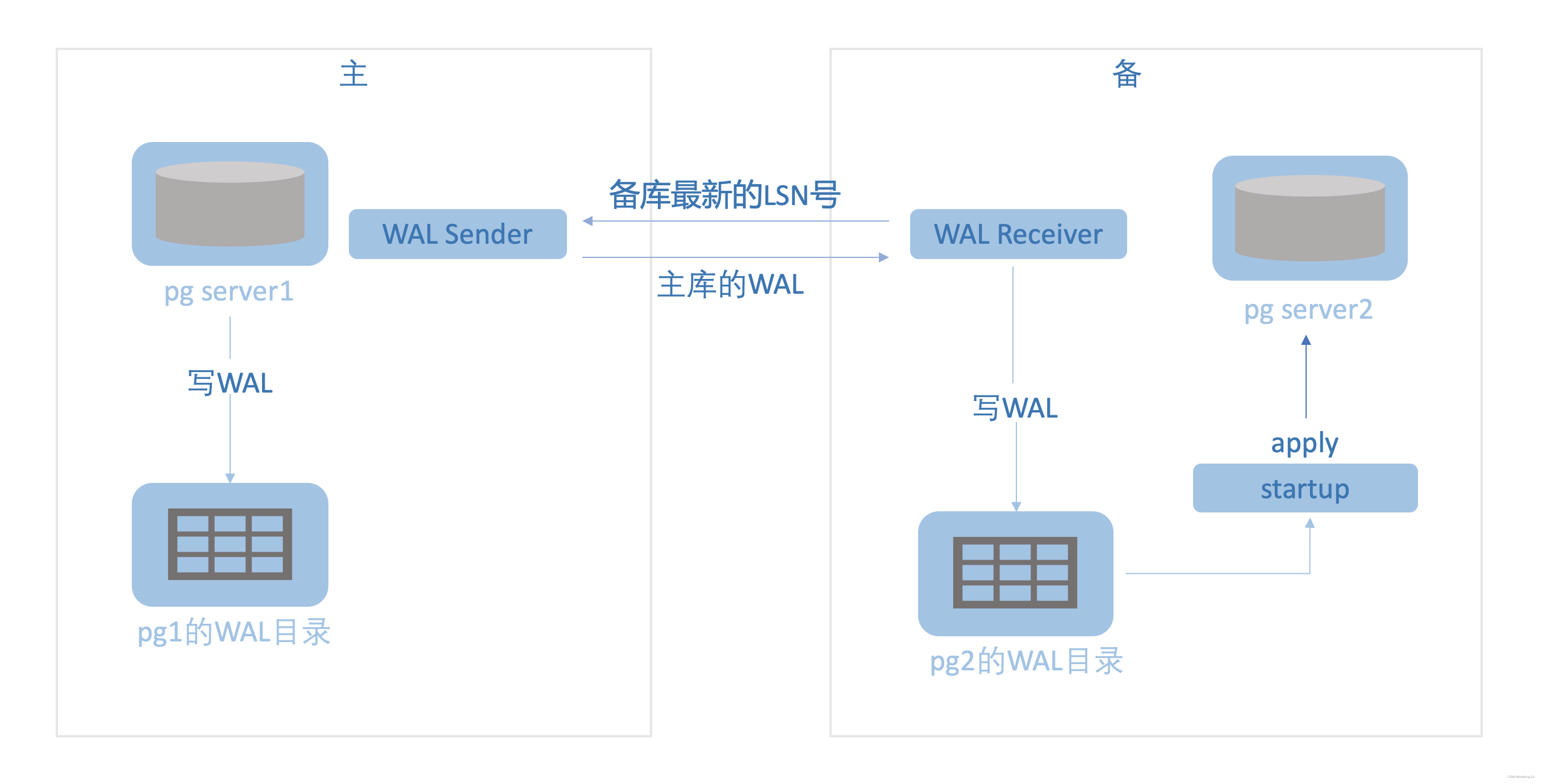
pg流复制进程
wal sender:wal sender存在于主库。wal sender进程将主库最新LSN到备库最新的LSN之间的wal 传递给备库
wal receiver:wal receiver存在于备库。wal receiver进程将备库最新的LSN号传递给主库。wal receiver接收wal sender传递过来的WAL数据并写入WAL日志
startup:备库实例恢复进程。将wal日志在备库上重放
pg 16776 14632 0 13:33 ? 00:00:00 postgres: wal sender process lzl 172.17.100.150(13338) streaming 0/3002D30
pg 16775 15329 0 13:33 ? 00:00:00 postgres: wal receiver process streaming 0/3002D30
pg 15330 15329 0 10:26 ? 00:00:00 postgres: startup process recovering 000000010000000000000003
pg流复制原理
pg流复制主要分为2个阶段,实例恢复阶段和主备同步阶段。
实例恢复阶段:当pg库异常宕机后,数据库启动时,pg会重放宕机前的最后一个checkpoint之后的所有WAL日志(这跟oracle、mysql等关系型数据库实例恢复是同样的原理,目的就是把数据库置为一致性状态)。pg备库在搭建时,一般主库都是不停机的,此时备份主库出来的备份库处于不一致状态,在备库启动时statup进程将进行实例恢复操作
主备同步阶段:wal receiver进程将备库最新的LSN号传递给主库,wal sender将主库最新LSN到备库最新的LSN之间的wal 传递给wal receiver,wal receiver接收WAL并将WAL写入到磁盘上,startup进程根据磁盘上的WAL日志在备库上重放
同步和异步
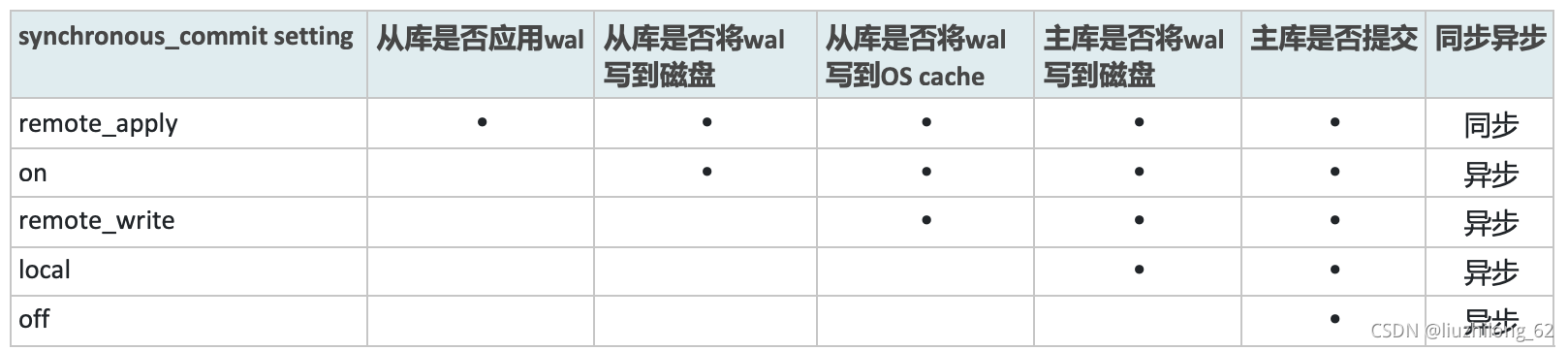
pg主从有5种模式,由synchronous_commit 参数控制。synchronous_commit 参数的本质就是控制主库什么时候提交。
remote_apply:所有备库上均已应用完WAL时,主库提交。所以这个模式是同步模式,主从是一致的,主库上能查到的数据备库上一定也可以查到,这种模式下主备没有延时,但对主库提交时间有影响,因为主库commit需要等待网络传输和备库应用时间
synchronous_commit的含义分2种情况,有从库和无从库时(synchronous_standby_name空或非空时)
当synchronous_standby_name为非空时:
remote_apply:从库已应用了wal,主库才可以提交。这种模式主从是同步的
on:default。主从的wal都写到磁盘上时,主库提交。类似半同步,不会丢数据。
remote_write:备库接收到wal并将wal日志写到文件系统cache上时,主库提交。此时从库的接收到wal但是还没有落盘,如果操作系统crash,会丢失数据。
local:主库wal刷到磁盘时提交。这种模式是异步的,主库不需要确认备库状态就可以提交。
off:本机wal没有刷到磁盘就可以提交,存在数据丢失风险,不推荐。
当synchronous_standby_name为空时:
(当synchronous_standby_name为空时,synchronous_commit只有on和off有效,如果是remote_apply, remote_write and local ,那么仍然被认为是on)
on:default。数据库wal写到磁盘上,事务才可以提交
off:本机wal没有刷到磁盘就可以提交,存在数据丢失风险,不推荐。
主从同步关系
主从可靠性

Failover
当主库crush时,备库就需要启动failover,此时备库就成为新主库。pg没有提供可以识别failure的方法,但是pg提供了激活主库的方法。(一般三方工具会调用pg激活方法,而主备监控、主库宕机判断、连接切换等等,都不是pg本身来做)
pg提供了2种方法将备库激活为主库:trigger_file文件和pg_ctl promote命令。(pg 12以后trigger_file变成promote_trigger_file)
trigger_file和pg_ctl promote在激活时都是一条命令就可以完成激活备库的任务,区别在于trigger_file需要在recover_file提前写好trigger_file配置
使用trigger_file做主备切换(pg_ctl promote同样的效果,比较简单):
1.备库recovery.conf中配置trigger_file
2.关闭主库
3.touch trigger_file,将老备库启动为新主库
4.配置recovery.conf,将老主库启动为新备库
5.观察新老主备库
failover示例:
环境:
主库 172.17.100.150 5432
备库 172.17.100.150 5433
1.备库recovery.conf中配置trigger_file
$ cat recovery.conf|grep trigger
trigger_file = ‘/pg/pg96data_sla/trigger.kenyon’
$ ll /pg/pg96data_sla/trigger.kenyon
ls: cannot access /pg/pg96data_sla/trigger.kenyon: No such file or directory
在recovery.conf中配置trigger文件路径就可以了,配置后不会出现trigger文件
备库postgres.conf添加配置
max_wal_senders = 6 #max_wal_senders是sender进程的最大数量,默认是0,所以切换前备库必须配置
hot_standby=on #备库打开查询功能
2.关闭主库
$ pg_ctl stop -D /pg/pg96data_pri -m fast
waiting for server to shut down… done
server stopped
(判断主库WAL是否全部被备库应用:pg9.6- cd pg_xlog;pg 10+ cd pg_wal)
ls -ltr|tail -n 1 |awk ‘{print $NF}’|while read xlog;do pg_xlogdump $xlog;done
观察备库wal中有关键词shutdown)
3.touch激活备库(或者 pg_ctl promote -D /pg/pg96data_sla
$ touch /pg/pg96data_sla/trigger.kenyon
此时recovery.conf变成recovery.done
4.主库设置为备库
配置新备库recovery.conf文件,可以直接cp老备库的过来,修改IP和目录
vi $新备库/recover.conf
standby_mode = on
primary_conninfo = ‘host=172.17.100.150 port=5433 user=lzl password=lzl’
recovery_target_timeline = ‘latest’
配置postgres.conf,将hot_standby = on写入conf,表示备库开启查询
vi $新备库/postgres.conf
hot_standby = on
启动新备库
/pg/pg96/bin/pg_ctl -D /pg/pg96data_pri -l /pg/pg96data_pri/server.log start
5.检查主备库
postgres=# \x
Expanded display is on.
postgres=# select * from pg_stat_replication ;
-[ RECORD 1 ]----±-----------------------------
pid | 24766
usesysid | 16384
usename | lzl
application_name | walreceiver
client_addr | 172.17.100.150
client_hostname |
client_port | 47345
backend_start | 2021-07-30 07:44:05.582546+00
backend_xmin |
state | streaming
sent_location | 0/4033790
write_location | 0/4033790
flush_location | 0/4033790
replay_location | 0/4033790
sync_priority | 0
sync_state | async
pg_basebackup
pg_basebackup是pg自带的备份工具,它用来做pg的基础备份。pg_basebackup可以用作PITR,也可以用来构造log-shipping standby和stream standby。它是pg的物理备份工具。
https://liuzhilong.blog.csdn.net/article/details/119533506
pg_rewind
pg_rewind可以用作pg主从的维护工具。当2个pg实例时间线(timeline)出现分叉时,pg_rewind可以做实例间的同步。(比如主库运行的情况下,备库failover后运行了一段时间,此时主备的时间线就出现了分叉)
https://liuzhilong.blog.csdn.net/article/details/119250794
Replication Slots
什么是pg复制槽?
主从架构下,如果从库还没有收到wal日志,主库就把wal删除了,这样的lag就不能自动恢复。复制槽就是为了确保主库不会把那些还没有被传到从库的WAL日志给删除。
在没有使用复制槽的情况下,可能需要用 wal_keep_size/wal_keep_segment和 archive_command去确保wal日志不被删除,但这种方式总会保留过多的wal,且在延时较大时也不能保证wal一定不会被删除。所以复制槽就是为此而生。
但是复制槽可能会导致主库一直不删除wal(比如从库已宕机的情况)导致磁盘被撑满,这时就需要max_slot_wal_keep_size来设置wal文件的保留上限。
复制槽参数:
max_slot_wal_keep_size:在有复制槽时,该参数定义pg_wal目录下wal文件的最大大小。默认值为-1,表示主库为从库保留wal文件的大小没有上限。
wal_keep_segments/wal_keep_size:pg12及以下为wal_keep_segments,pg13及以上为wal_keep_size。保证pg_wal下的wal文件不会被删除。在没有复制槽的情况下,wal文件超过该大小就可能被删除,可能导致从库不可追日志。如果调整的过大,可能导致目录被撑的很大。该参数默认为0,也就是不保留WAL文件。如果wal被删除,可能会出现如下报错
ERROR: requested WAL segment xxxx has already been removed
这时从库只能期待有归档,否则只要重搭。
primary_slot_name:设置slot的名字,表示pg主从开启复制槽。所以开启pg复制槽至少有类似下面的配置
primary_conninfo = ‘host=172.17.100.150 port=5433 user=lzl password=lzl’
primary_slot_name = ‘pg_slot_lzl’
max_replication_slots:复制槽的最大个数,重启生效。如果使用的复制槽不足,从库将启动失败。应将该值设置的较大。在pg9.6版本以下,默认值为0,pg10以上为10。
创建pg复制槽
1.设置主库max_replication_slots参数
主库:(我的pg版本为9.6)
max_replication_slots=10
加入postgres.conf,并重启主库
2.创建复制槽
创建复制槽:
postgres=# SELECT * FROM pg_create_physical_replication_slot(‘pg_slot_lzl’);
slot_name | xlog_position
-------------±--------------
pg_slot_lzl |
查看复制槽
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-------------±----------±-------
pg_slot_lzl | physical | f
3.设置从库primary_slot_name参数
primary_slot_name = ‘pg_slot_lzl’
加入recovery.conf,并重启从库
4.查看复制槽
postgres=# select *,pg_xlogfile_name(restart_lsn)as current_xxlog from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | current_xxlog
-------------±-------±----------±-------±---------±-------±-----------±-----±-------------±------------±--------------------±-------------------------
pg_slot_lzl | | physical | | | t | 12802 | | | 0/A002340 | | 00000002000000000000000A
–pg_xlogfile_name(restart_lsn)查看当前wal日志信息
查询冲突
什么是查询冲突?
备库在查询时可能会遇到如下错误
ERROR:canceling statement due to confilct with recovery。
为什么会产生冲突呢?我们细想一下,比如说备库正在执行基于某个表的查询(这个查询可能是应用产生的,也可能是手动连接进行的查询),这时主库执行了drop table操作,该操作写入wal日志后传至备库进行应用,为了保证数据一致性,postgresql必然会迅速回放数据,这时drop table和select就会形成冲突。如下图所示:
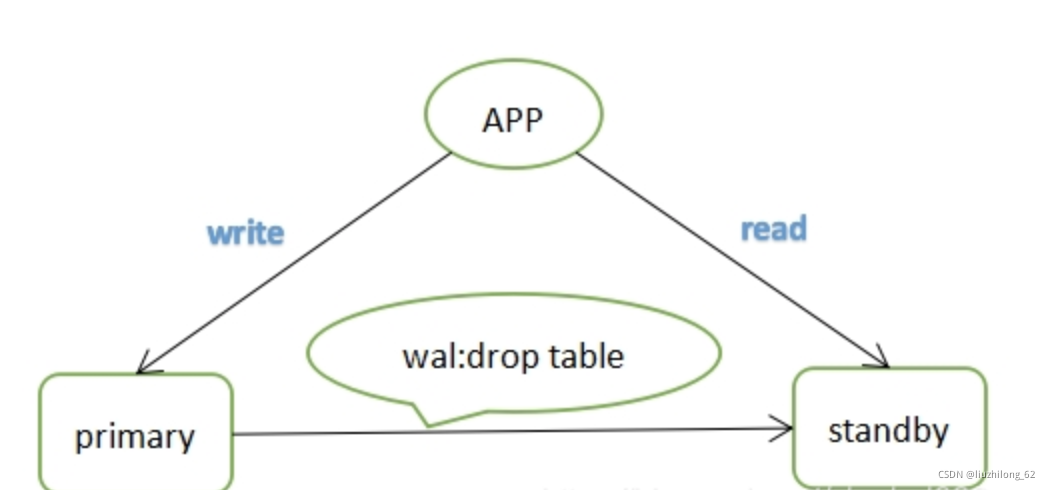
冲突场景:
上面只介绍了1种查询冲突的情况。总结一下有以下几种情况
1.主库排他锁(包括显示LOCK命令和各种DDL)
2.主库vacuum清理死元组,从库如果正在使用该元组,就会产生冲突
3.主库删除了从库查询正在使用的表空间
4.主库删除了从库正在使用的数据库
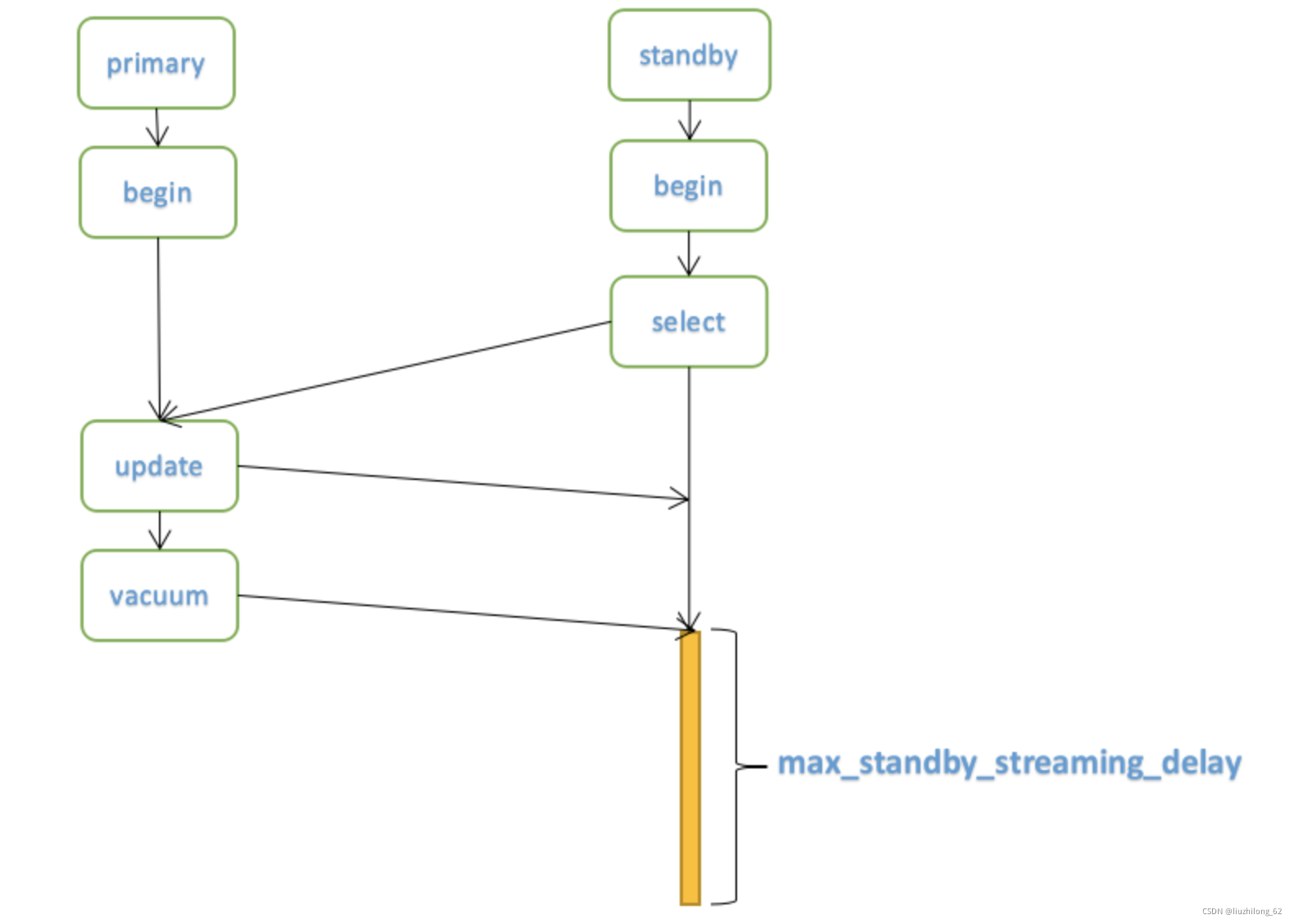
试想在仅有主库的情况下:
场景1:一个会话发起了drop table,此时发现有select语句正在执行,那么该会话只能等待select完成其事务。
场景2:一个会话发起vacuum或后台自动vacuum,不会与当前库查询发生冲突,因为vacuum不会清理正在使用的元组。
从库的处理就不同。因为主库不知道从库的事务状态,而从库又需要与主库保持一致,所以才发生了“查询冲突”
查询冲突参数
hot_standby_feedback:
这个参数是查询冲突这个话题中提到最多的参数,下面我们详细探讨一下。我们假设在没有备库的情况下,会话1查询某行数据,会话2删除该数据,然后commit,此时会话2执行一次vacuum,我们知道这次vacuum并不会删除该行数据,因为会话1的事务还需要使用该元组,所以不会清理该元组。那么如果是主从呢?主库在准备进行vacuum时怎么知道从库还在进行查询,这就是设置该参数的意义,设置hot_standby_feedback参数之后备库会定期向主库通知最小活跃事务id(xmin)值,这样使得主库vacuum进程不会清理大于xmin值的事务。
这个参数有利于减少冲突的发生,但并不能完全避免冲突,其实细想一下,这个参数只是减少了由于主库vacuum死亡元组造成的冲突,并不能解决排他锁造成的冲突。或者由于网络中断造成的冲突,假如主备之间的网络中断后,备库就无法向主库正常发送xmin值,如果时间够长,主库在这段时间内还是会清理无用元组,这样网络恢复后就可能发生上面的vacuum造成的冲突。
值得注意的是hot_standby_feedback参数并不会覆盖主库上old_snapshot_threshold参数限定的值,old_snapshot_threshold参数限制了死亡元组的无限膨胀,当事务信息超过old_snapshot_threshold的限制时,依然会进行清理。
max_standby_streaming_delay:
备机因为接收wal流日志产生查询冲突而取消查询之前的等待时间,设置该参数会在发生冲突时,备库查询不会立即取消,而是等待一个时间后如果还没结束再抛出报错。这个值的大小可以参考备库可能产生的长事务运行时间。
max_standby_archive_delay:
备机因为处理归档的wal日志产生查询冲突而取消查询之前的等待时间,和上面的参数类似。
vacuum_defer_cleanup_age:
指定vacuum延迟清理死亡元组的事务数,vacuum会延迟清除无效的记录,延迟的事务个数通过vacuum_defer_cleanup_age进行设置。即vacuum和vacuum full操作不会立即清理刚刚被删除元组
可以根据pg_stat_database和pg_stat_database_conflicts视图查看冲突发生的情况
其他相关参数
传输参数
max_wal_senders:使用wal sender获取wal的服务最大个数,也就是从库+baseback客户端的最大个数。pg9.6默认为0,pg10以后默认为10。
wal_send_timeout:wal传输xx秒失败后中断复制。该参数在从库宕机或者网络长期中断时,wal不会再尝试传输。默认60。0表示永
不中断复制
track_commit_timestamp:记录事务的时间。默认是off。
主库参数
synchronous_standby_names:
在主库上配置,备机的复制列表。有下面几种方式(s1,s2,s3代表备机的application_name,配置在recovery.conf中)
synchronous_standby_names=‘s1’ 代表s1备机返回就可以提交。
synchronous_standby_names=‘FIRST 2 (s1,s2,s3)’ 代表s1,s2,s3三个备机中前两个s1和s2返回主库就可以提交。
synchronous_standby_names=‘ANY 2 (s1,s2,s3)’ 代表s1,s2,s3三个备机中任意两个备机返回主库就可以提交。
synchronous_standby_names=’*’ 代表匹配任意主机,也就是任意主机返回就可以提交。
wal_level:
wal日志级别,这个参数决定了有多少信息写入wal日志,默认是replica,这种模式支持复制和wal归档,同时支持备库只读查询。
minimal:除了实例crash恢复需要的记录,其他不记录,比如CREATE TABLE AS,CREATE INDEX,CLUSTER,COPY可以跳过,该模式记录的日志信息不足以支持wal归档和流复制。
logic:在replica的基础上增加一些信息以支持逻辑解码,该模式会增大wal日志的数量,尤其是大量的update,delete操作的库。
在9.6之前还有archive和hot_standby模式,映射到现在的replica模式。
synchronous_commit:
前面已讲过,5种模式,各有优劣。
archive_mode :archive_mode =on表示打开归档
archive_command:归档命令,pg归档直接调用操作系统命令。可以是简单cp命令到备份端
listen_addresses:监听地址。’'表示所有IP都监听,默认为local
从库参数
hot_standby:on表示打开从库只读
primary_conninfo:从库连接主库的连接串。如primary_conninfo = ‘host=172.17.100.150 port=5432 user=lzl password=lzl’
trigger_file/promote_trigger_file:激活备库的激活文件。pg 12以前叫trigger_file,pg12及以后为promote_trigger_file
trigger_file和pg_ctl promote在激活时都是一条命令就可以完成激活备库,前面已经具体演示过
wal_receiver_create_temp_slot:当没有slot时,临时起一个slot(命为primary_slot_name)。默认是off的。
参考文档:
《PostgreSQL修炼之道》
https://www.postgresql.org/docs/current/warm-standby.html
https://www.postgresql.org/docs/13/high-availability.html
https://www.postgresql.org/docs/current/runtime-config-replication.html
https://www.postgresql.org/docs/13/runtime-config-wal.html
https://www.postgresql.org/docs/current/app-pgbasebackup.html
https://www.postgresql.org/docs/current/hot-standby.html#HOT-STANDBY-CONFLICT
https://cloud.tencent.com/developer/article/1555354
https://www.modb.pro/db/29737
https://wiki.postgresql.org/wiki/Streaming_Replication
https://www.percona.com/blog/2018/09/07/setting-up-streaming-replication-postgresql/
https://www.cybertec-postgresql.com/en/the-synchronous_commit-parameter/
https://blog.csdn.net/m15217321304/article/details/88850146
https://blog.51cto.com/lishiyan/2460518?source=dra


















 3311
3311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











